
Zaawansowane przetwarzanie obrazu w komórkowych sieciach neuronowych
WSTĘP
Od czasu wprowadzenia do społeczności badawczej w 1988 r. paradygmat komórkowej sieci neuronowej (CNN) stał się żyzną glebą dla inżynierów i fizyków, którzy w ciągu niecałych 20 lat opublikowali ponad 1000 artykułów naukowych i książek, związane głównie z cyfrowym przetwarzaniem obrazu (DIP). Ta sztuczna sieć neuronowa (ANN) oferuje niezwykłą zdolność integrowania złożonych procesów obliczeniowych w kompaktowe, programowalne w czasie rzeczywistym analogowe obwody VLSI, takie jak ACE16k , a ostatnio w urządzenia FPGA . CNN stanowi rdzeń rewolucyjnego Analogicznego Komputera Komórkowego (Roska i in., 1999), programowalnego systemu opartego na tzw. Uniwersalnej Maszynie CNN (CNN-UM). Analogiczne komputery CNN naśladują anatomię i fizjologię wielu narządów zmysłów i narządów biologicznych przetwarzających.
TŁO
Standardowa architektura CNN składa się z prostokątnego układu M × N komórek C(i,j) o współrzędnych kartezjańskich (i,j), i = 1, 2,…, M, j = 1, 2, … , N. Każdy komórka lub neuron C(i,j) jest ograniczona do sfery wpływów Sr(i,j) o dodatnim promieniu całkowitym r, zdefiniowanym przez:
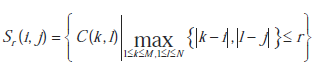
Zbiór ten nazywany jest sąsiedztwem (2r +1) × (2r +1). Parametr r kontroluje łączność komórki. Gdy r > N /2 i M = N, uzyskuje się w pełni połączoną CNN, co odpowiada klasycznemu modelowi SSN Hopfielda. Równanie stanu dowolnej komórki C(i,j) w strukturze tablicowej M × N standardowego CNN można opisać wzorem:

gdzie C i R są wartościami kontrolującymi przejściową odpowiedź obwodu neuronu (podobnie jak filtr RC), I jest ogólnie stałą wartością, która odchyla macierz stanu Z = {zij}, a Sr jest lokalnym sąsiedztwem zdefiniowanym w (1 ), który kontroluje wpływ danych wejściowych X = {xij} i wyjściowych sieci Y = {yij} przez czas t. Oznacza to, że zarówno płaszczyzna wejściowa, jak i wyjściowa oddziałują na stan komórki poprzez definicję zestawu wag o wartościach rzeczywistych A(i, j; k, l) oraz B(i, j; k, l), których rozmiar jest określony przez r. Szablony klonowania A i B nazywane są odpowiednio operatorami sprzężenia zwrotnego i wyprzedzającego. Izotropowy CNN jest zwykle definiowany ze stałymi wartościami r, I, A i B, co oznacza, że dla obrazu wejściowego X dla każdego piksela (i, j) zapewniany jest neuron C(i,j), przy czym zdefiniowane są obwody o stałym obciążeniu poprzez szablony sprzężenia zwrotnego i wyprzedzającego A i B. Wartość stanu neuronu zij jest korygowana za pomocą parametru odchylenia I i przekazywana jako dane wejściowe do funkcji wyjściowej w postaci:

Zdecydowana większość szablonów zdefiniowanych w kompendium szablonów CNN-UM opiera się na tym schemacie izotropowym, wykorzystującym r = 1 i obrazy binarne w płaszczyźnie wejściowej. Jeśli nie jest stosowane żadne sprzężenie zwrotne (tj. A = 0), wówczas CNN zachowuje się jak sieć splotów, wykorzystując B jako filtr przestrzenny, I jako próg i fragmentarycznie liniowy sygnał wyjściowy (3) jako ogranicznik. Zatem praktycznie każdy filtr przestrzenny z teorii DIP może zostać zaimplementowany w takim CNN ze sprzężeniem zwrotnym, zapewniając stabilność wyjścia binarnego poprzez definicję wartości bezwzględnej centralnego sprzężenia zwrotnego większej niż 1.
ZAAWANSOWANE PRZETWARZANIE OBRAZU CNN
W tej sekcji dokonano opisu bardziej złożonych modeli CNN, aby zapewnić głębszy wgląd w projekty CNN, w tym struktury wielowarstwowe i szablony nieliniowe, a także zilustrować jego potężne możliwości DIP.
Szablony nieliniowe
Problemem często poruszanym przy wykrywaniu krawędzi DIP jest odporność na szum . W tym sensie detektor EDGE CNN do obrazów w skali szarości nadawanych przez

jest typowym przykładem filtra słabego przeciwzakłóceniowego, powstałego w wyniku ustalonego liniowego szablonu wyprzedzającego w połączeniu z pobudzającym sprzężeniem zwrotnym. Jednym ze sposobów zapewnienia większej odporności detektora na szum jest zdefiniowanie nieliniowego szablonu B w postaci:

Ten nieliniowy szablon w rzeczywistości definiuje różne współczynniki dla otaczających pikseli przed wykonaniem przestrzennego filtrowania obrazu wejściowego X. Zatem CNN zdefiniowana za pomocą nieliniowych szablonów jest ogólnie zależna od X i nie można jej traktować jako modelu izotropowego. Dopuszczalne są tylko dwie wartości otaczających współczynników B: jedna pobudzająca dla różnic w luminancji większych niż próg th w stosunku do piksela centralnego (tj. pikseli brzegowych), a druga hamująca, podwojona w wartości bezwzględnej, dla podobnych pikseli, gdzie th zwykle wynosi ustawić na około 0,5. Szablon sprzężenia zwrotnego A = 2 pozostaje niezmieniony, ale wartość obciążenia I należy wybrać z następującej analizy: Dla danego elementu zij stanu udział wij nieliniowego filtra wyprzedzającego (5) można wyrazić jako:
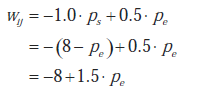
gdzie ps to liczba podobnych pikseli w sąsiedztwie 3 × 3, a pe pozostałych pikseli krawędziowych. Np. jeśli centralny piksel ma 8 sąsiadów krawędziowych, wij = 12 - 8 = 4, natomiast jeśli wszyscy jego sąsiedzi są do niego podobni, to wij = -8. Zatem piksel zostanie wybrany jako krawędź w zależności od liczby jego sąsiadów na krawędzi, zapewniając możliwość redukcji szumu. Na przykład wykrywanie krawędzi dla pikseli z co najmniej 3 sąsiadami krawędziowymi wymusza I ∈ (4, 5). Głównym rezultatem jest to, że włączenie nieliniowości do definicji współczynników B, a co za tym idzie, definicja głównych parametrów CNN w ujęciu pikselowym powoduje powstanie potężniejszych i bardziej złożonych filtrów DIP
Operatory morfologiczne
Morfologia matematyczna wnosi ważny wkład w dziedzinę DIP. W podejściu klasycznym każdy operator morfologiczny opiera się na szeregu prostych koncepcji z Teorii Mnogości. Ponadto wszystkie można podzielić na kombinacje dwóch podstawowych operatorów: erozji i dylatacji. Obydwa operatory przyjmują jako dane wejściowe dwie części danych: binarny obraz wejściowy i tzw. element strukturujący, który jest zwykle reprezentowany przez szablon 3×3. Piksel należy do obiektu, jeśli jest aktywny (tj. jego wartość wynosi 1 lub jest czarny), natomiast pozostałe piksele są klasyfikowane jako elementy tła o wartości zerowej. Podstawowe operatory morfologiczne definiowane są przy użyciu wyłącznie pikseli obiektu, oznaczonych jako 1 w elemencie strukturalnym. Jeśli piksel nie jest używany w dopasowaniu, pozostaje pusty. Zarówno operatory dylatacji, jak i erozji można zdefiniować za pomocą elementów strukturalnych.
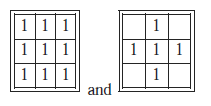
odpowiednio dla łączności 8 lub 4 sąsiadów. W przypadku dylatacji element nadający strukturę jest umieszczany nad każdym pikselem wejściowym. Jeśli którykolwiek z 9 (lub 5) pikseli rozważanych w (7) jest aktywny, wówczas aktywny będzie również piksel wyjściowy . Operator erozji można zdefiniować jako dualność dylatacji, czyli dylatacji wykonywanej na tle. Bardziej złożone operatory morfologiczne opierają się na elementach strukturalnych, które zawierają również piksele tła. Tak jest w przypadku transformacji Hit and Miss Transform (HMT), uogólnionego operatora morfologicznego używanego do identyfikacji pewnych lokalnych konfiguracji pikseli. Na przykład elementy strukturalne zdefiniowane przez
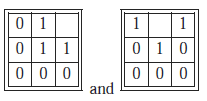
służą do wyszukiwania wypukłych pikseli obiektu narożnego pod kątem 90° na obrazie. Piksel zostanie wybrany jako aktywny w obrazie wyjściowym, jeśli jego lokalne sąsiedztwo dokładnie odpowiada temu określonemu przez element nadający strukturę. Jednakże, aby obliczyć pełny, niezorientowany detektor narożny, konieczne będzie wykonanie 8 HMT, po jednym dla każdej obróconej wersji (8), OR-ing 8 pośrednich obrazów wyjściowych w celu uzyskania obrazu końcowego. W kontekście CNN HMT można uzyskać w prosty sposób poprzez:
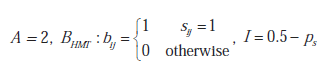
(9)
gdzie S = {sij} jest elementem strukturalnym, a ps jest całkowitą liczbą aktywnych pikseli. Ponieważ szablon wejściowy B HTM CNN jest zdefiniowany poprzez element strukturalny S i biorąc pod uwagę, że istnieje 29 = 512 różnych możliwych elementów strukturalnych 3 × 3, będzie również 512 różnych erozji typu hit-and-mis. Aby osiągnąć odwrotny wynik, tj. Rozszerzenie typu hit-and-miss, próg musi być przeciwny do tego w (9)
Kontrola zakresu dynamicznego CNN i fragmentaryczne mapowania liniowe
Techniki DIP można klasyfikować według dziedziny, w której operują: domena obrazowa lub przestrzenna lub domena transformacji (np. domena Fouriera). Techniki domeny przestrzennej to te, które działają bezpośrednio na pikselach obrazu (np. Na jego poziomie intensywności). Ogólny operator przestrzenny można zdefiniować za pomocą

gdzie X i Y są odpowiednio obrazami wejściowymi i wyjściowymi, a T jest operatorem przestrzennym zdefiniowanym w sąsiedztwie Sr wokół każdego piksela X(i, j), jak zdefiniowano w (1). W oparciu o to sąsiedztwo operatory przestrzenne można podzielić na dwa typy: operatory przetwarzania jednopunktowego, znane również jako operatory mapowania, oraz operatory przetwarzania lokalnego, które można zdefiniować za pomocą maski filtra przestrzennego (tj. splotu dyskretnego 2D) (Jain, 1989). ). Najprostszą postać T uzyskuje się, gdy Sr ma rozmiar 1 piksela. W tym przypadku Y zależy tylko od wartości intensywności X dla każdego piksela, a T staje się funkcją transformacji poziomu intensywności, czyli mapowaniem, w postaci
s = T(r)
gdzie X i Y są odpowiednio obrazami wejściowymi i wyjściowymi, a T jest operatorem przestrzennym zdefiniowanym w sąsiedztwie Sr wokół każdego piksela X(i, j), jak zdefiniowano w (1). W oparciu o to sąsiedztwo operatora przestrzennego można podzielić na dwa typy: operatory przetwarzania jednopunktowego, znane również jako operatory mapowania, oraz operatory przetwarzania lokalnego, które można zdefiniować za pomocą maski filtra przestrzennego (tj. splotu dyskretnego 2D) . Najprostszą postać T uzyskuje się, gdy Sr ma rozmiar 1 piksela. W tym przypadku Y zależy tylko od wartości intensywności X dla każdego piksela, a T staje się funkcją transformacji poziomu intensywności lub mapowaniem w postaci +1] zakresu. Odchylenie I kontroluje średni punkt zakresu wejściowego, gdzie funkcja wyjściowa daje wynik o wartości zerowej. Zaczynając od oryginalnej komórki lub neuronu CNN (1)-(3), następuje krótki przegląd modelu CNN kontroli zakresu dynamicznego (DRC), zdefiniowanego po raz pierwszy w . Sieć ta jest zaprojektowana do wykonywania fragmentarycznego liniowego odwzorowania T na X, z zakresem wejściowym [m-d, m+d] i zakresem wyjściowym [a, b]. Zatem,
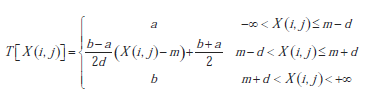
(12)
Aby móc realizować tę funkcję w wielowarstwowym CNN, muszą zostać spełnione następujące ograniczenia:
|b-a| ≤ i d ≤ 1 (13)
Komórkę CNN kontrolującą żądany zakres wejściowy można zdefiniować za pomocą następujących parametrów:
A1 = 0 , B1 = 1/d I1 = -m/d
(14)
Sieć ta wykonuje mapowanie liniowe pomiędzy [m-d, m+d] i [-1,+1]. Jego wyjście jest wejściem drugiego CNN, którego parametry to:
A2, B2 = (b -a)/2 , I2 = (b + a)/2
(15)
Wynikiem tej drugiej sieci jest dokładnie odwzorowanie T zdefiniowane w (12) ograniczone ograniczeniami (13). Jedną z najprostszych technik stosowanych w celu zwiększenia kontrastu obrazu w skali szarości jest rozciąganie kontrastu lub normalizacja. Technika ta maksymalizuje zakres dynamiczny poziomów intensywności na obrazie na podstawie odpowiednich szacunków maksymalnych i minimalnych wartości intensywności. Zatem w przypadku znormalizowanych obrazów w skali szarości, gdzie minimalny (tj. czarny) i maksymalny (tj. biały) poziom intensywności są reprezentowane odpowiednio przez wartości 0 i 1; jeśli taki obraz o zakresie intensywności dynamicznej [f, g] ⊆ [0, +1] zostanie podany na wejście 2-warstwowego CNN określonego przez (14) i (15), to następujące parametry pozwolą uzyskać pożądaną dynamikę liniową maksymalizacja zasięgu:
a = 0 , b = 1 , m = (g +f)/2 , d = (g-f)/2
Sieć DRC można łatwo zastosować do odcinkowego przybliżenia wielomianowego pierwszego rzędu nieliniowych, ciągłych odwzorowań. Jedną z możliwych możliwości jest wielowarstwowa implementacja wielomianów Czebyszewa sterowanych błędami w DRC CNN, jak opisano. Możliwe odwzorowania obejmują między innymi funkcje wartości bezwzględnej, logarytmicznej, wykładniczej, radialnej oraz funkcje potęgowe o wartościach całkowitych i rzeczywistych.
PRZYSZŁE TRENDY
Inżynierowie i specjaliści nieustannie poszukują: konkurować i naśladować naturę, zwłaszcza niektóre "inteligentne" zwierzęta. Wizja to szczególny obszar zainteresowania inżynierów komputerów. W tym kontekście tak zwane oko bioniczne osadzone w architekturze CNN-UM idealnie nadaje się do realizacji wielu czasoprzestrzennych modeli neuromorficznych. Dzięki potężnemu zestawowi narzędzi do przetwarzania obrazu i kompaktowej implementacji VLSI CNN-UM może być używany do programowania lub naśladowania różnych modeli siatkówek, a nawet ich kombinacji. Co więcej, może łączyć modele oparte na biologii, modele inspirowane biologią i modele analogiczne algorytmy przetwarzania sztucznego obrazu. To połączenie z pewnością przyniesie szerszy rodzaj zastosowań i rozwiązań.
WNIOSEK
W ostatniej dekadzie zbadano szereg innych postępów w definicji i charakterystyce CNN. Obejmuje to definicję metod projektowania i wdrażania dzielnic o wymiarach większych niż 3×3 w CNN-UM , wdrażanie przez CNN niektórych technik kompresji obrazu lub projektowanie Algorytm szybkiej transformacji Fouriera oparty na CNN dla sygnałów analogowych oraz wiele innych. W tym artykule dokonano ogólnego przeglądu głównych właściwości i cech modelu komórkowej sieci neuronowej, koncentrując się na jej zastosowaniach DIP. CNN jest obecnie podstawowym i potężnym zestawem narzędzi do zadań nieliniowego przetwarzania obrazu w czasie rzeczywistym, głównie ze względu na jego wszechstronną programowalność, która umożliwiła rozwój sprzętu do zastosowań w czujnikach wizualnych
Zastosowanie ANN w dziedzinie betonu konstrukcyjnego
WSTĘP
Mechanizmy sztucznej inteligencji (AI) są coraz częściej stosowane do wszelkiego rodzaju problemów inżynierii lądowej. Nowe metody i algorytmy, które pozwalają inżynierom lądowym na wykorzystywanie tych technik w różny sposób w przypadku różnych problemów, są dostępne lub są udostępniane. Jedna z technik AI wyróżnia się na tle pozostałych: sztuczne sieci neuronowe (ANN). Ich najbardziej niezwykłymi cechami są zdolność uczenia się, możliwość generalizacji i tolerancja na błędy. Te cechy sprawiają, że ich stosowanie jest opłacalne i opłacalne w każdej dziedzinie, a w szczególności w inżynierii budowlanej. Obecnie najbardziej rozpowszechnionym materiałem budowlanym jest beton, głównie ze względu na jego wysoką wytrzymałość i możliwość dostosowania do szalunków podczas procesu produkcji. W tym rozdziale znajdziemy różne zastosowania ANN do betonu konstrukcyjnego.
Sztuczne sieci neuronowe
Warren McCulloch i Walter Pitts są uznawani za twórców sztucznych sieci w latach 40. XX wieku, ponieważ jako pierwsi zaprojektowali sztuczny neuron . Zaproponowali model neuronu w trybie binarnym (aktywnym lub nieaktywnym) ze stałym progiem, który musi zostać przekroczony, aby zmienić stan. Niektóre z wprowadzonych przez nich koncepcji są nadal przydatne. Sztuczne sieci neuronowe mają na celu symulację właściwości występujących w biologicznych systemach neuronowych za pomocą modeli matematycznych za pomocą sztucznych mechanizmów. Neuron jest uważany za formalny element, moduł lub podstawową jednostkę sieciową, która odbiera informacje z innych modułów lub środowiska; następnie integruje i oblicza te informacje, aby wyemitować pojedyncze wyjście, które zostanie identycznie przesłane do kolejnych wielu neuronów (Wasserman, 1989). Wyjście sztucznego neuronu jest określane przez jego funkcje propagacji lub wzbudzenia, aktywacji i transferu. Funkcja propagacji jest na ogół sumą każdego wejścia pomnożonego przez wagę jego połączenia (wartość netto):
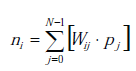
Funkcja aktywacji modyfikuje ten ostatni, wiążąc sygnał wejściowy neuronalny z kolejnym stanem aktywacji.
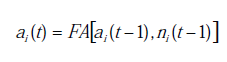
Funkcja przejścia jest stosowana do wyniku funkcji aktywacji. Służy do ograniczenia wyjścia neuronu i jest zazwyczaj podawana przez interpretację przeznaczoną dla wyjścia. Niektóre z najczęściej używanych funkcji przejścia to sigmoidalna (aby uzyskać wartości w przedziale [0,1]) i hiperboliczna tangensowa (aby uzyskać wartości w przedziale [-1,1]).
outi = FT(ai(t)
Po zdefiniowaniu każdego elementu procesu należy zaprojektować typ sieci (topologię sieci), która ma zostać użyta. Można je podzielić na sieci forward-feed, w których informacje przemieszczają się tylko w jednym kierunku (od wejścia do wyjścia) oraz sieci z częściowym lub całkowitym sprzężeniem zwrotnym, w których informacje mogą płynąć w dowolnym kierunku. Na koniec należy zdefiniować reguły uczenia się i typ szkolenia. Reguły uczenia się dzielą się na nadzorowane i nienadzorowane , a w ramach tych ostatnich, samoorganizujące się uczenie się i uczenie się przez wzmacnianie . Typ szkolenia będzie zależał od wybranego typu uczenia się.
Wprowadzenie do betonu (materiał i struktura)
Beton konstrukcyjny to materiał budowlany wytwarzany z mieszanki cementu, wody, kruszyw i dodatków lub domieszek o różnych funkcjach. Celem jest stworzenie materiału o wyglądzie skały, o wystarczającej wytrzymałości na ściskanie i zdolności do przyjmowania odpowiednich kształtów strukturalnych. Beton jest formowalny w fazie przygotowywania, po wymieszaniu składników powstaje płynna masa, która wygodnie zajmuje wnęki w formie zwanej szalunkiem. Po kilku godzinach beton twardnieje dzięki reakcji chemicznej hydratacji eksperymentowanej z cementem, generując pastę, która otacza kruszywa i nadaje zespołowi wygląd sztucznej skały nieco podobnej do konglomeratu. Stwardniały beton oferuje dobrą wytrzymałość na ściskanie, ale bardzo niską wytrzymałość na rozciąganie. Dlatego konstrukcje wykonane z tego materiału muszą być wzmacniane za pomocą stalowych prętów zbrojeniowych, skonfigurowanych za pomocą prętów, które są umieszczane (przed wylaniem betonu) wzdłuż linii, gdzie obliczenia przewidują najwyższe naprężenia rozciągające. Pękanie, które zmniejsza trwałość konstrukcji, jest w ten sposób utrudnione, a wystarczająca wytrzymałość jest gwarantowana przy bardzo niskim prawdopodobieństwie awarii. Całość utworzona z betonu i prętów zbrojeniowych jest określana jako beton konstrukcyjny. Dwie fazy charakteryzują zatem ewolucję betonu w czasie. W pierwszej fazie beton musi być wystarczająco płynny, aby zapewnić łatwość układania, a czas początkowego wiązania musi być wystarczająco długi, aby umożliwić transport z zakładu na miejsce pracy. Płynność zależy zasadniczo od rodzaju i ilości składników w mieszance. Specjalne domieszki chemiczne (takie jak plastyfikatory i superplastyfikatory) gwarantują płynność bez znacznego zwiększania ilości wody, której stosunek w stosunku do ilości cementu (lub stosunek woda/cement, w/c) jest odwrotnie proporcjonalny do uzyskanej wytrzymałości. Nauka reologii zajmuje się badaniem zachowania świeżego betonu. Do określenia płynności świeżego betonu można zastosować różne testy, z których najpopularniejszym jest test stożka Abramsa lub test stożka opadowego . Druga faza (i najdłuższa w czasie) to faza stwardniałego betonu, która określa zachowanie struktury, której nadaje kształt, z punktu widzenia użyteczności (poprzez narzucenie ograniczeń na pękanie i podatność) i odporności na awarie (poprzez narzucenie ograniczeń na minimalne obciążenia, którym można się oprzeć, w porównaniu z siłami wewnętrznymi wytwarzanymi przez obciążenie zewnętrzne), zawsze w ramach wystarczającej trwałości dla przewidywanego okresu użytkowania. Badanie betonu konstrukcyjnego z każdego punktu widzenia zostało podjęte zgodnie z wieloma różnymi optykami. Ścieżka eksperymentalna była bardzo produktywna, generując w ciągu ostatnich 50 lat bazę danych (z tendencją do rozproszenia), która została wykorzystana do zatwierdzenia badań prowadzonych wzdłuż drugiej i trzeciej ścieżki, które następują. Ścieżka analityczna stanowi również podstawowe narzędzie do podejścia do zachowania betonu, zarówno z punktu widzenia materiału, jak i konstrukcji. Rozwój teoretycznych modeli zachowań sięga początku XX wieku, a opracowane od tego czasu równania teoretyczne były korygowane poprzez testowanie (jak wspomniano powyżej), zanim stały się częścią kodów i specyfikacji. Ta metoda analizy została wzmocniona przez rozwój metod numerycznych i systemów obliczeniowych, zdolnych do rozwiązywania dużej liczby równoczesnych równań. W szczególności metoda elementów skończonych (i inne metody z tej samej rodziny) oraz techniki optymalizacji przyniosły niezwykłą zdolność do przybliżania zachowania betonu konstrukcyjnego, a ich wyniki zostały porównane w wielu zastosowaniach za pomocą wyżej wymienionych testów eksperymentalnych. Dostępne są zatem trzy podstawowe kierunki badań. Będąc wzajemnie uzupełniającymi się, odegrały decydującą rolę w produkcji krajowych i międzynarodowych kodów i zasad, które kierują lub stanowią prawodawstwo w zakresie projektu, wykonania i konserwacji prac z betonu konstrukcyjnego. Beton jest złożonym materiałem, który stwarza szereg problemów dla badań analitycznych, a zatem jest odpowiednim polem do rozwoju technik analizy opartych na sieciach neuronowych. Zastosowanie sztucznych sieci neuronowych do problemów w dziedzinie betonu konstrukcyjnego rozwinęło się w ciągu ostatnich kilku lat na dwa sposoby. Z jednej strony, analityczne i konstrukcyjne systemy optymalizacji szybsze niż tradycyjne (zwykle iteracyjne) metody zostały wygenerowane zaczynając od wyrażeń i reguł obliczeniowych. Z drugiej strony, liczne bazy danych utworzone z dużej liczby testów opublikowanych w społeczności naukowej pozwoliły na rozwój bardzo wydajnych ANN, które rzuciły światło na różne złożone zjawiska. W kilku przypadkach, konkretne zaprojektowane kody zostały ulepszone poprzez wykorzystanie tych technik; poniżej przedstawiono kilka przykładów.
Zastosowanie sztucznych sieci neuronowych w problemach optymalizacji
Projektowanie konstrukcji betonowych opiera się na określeniu dwóch podstawowych parametrów: grubości elementu (efektywnej głębokości d, głębokości przekroju belki lub płyty mierzonej od powierzchni ściskanej do środka ciężkości zbrojenia) i ilości zbrojenia (ustalonej jako całkowita powierzchnia As stali w przekroju, zmaterializowanej jako pręty zbrojeniowe lub współczynnik zbrojenia, stosunek powierzchni stali do powierzchni betonu w przekroju). Metody obliczeniowe są iteracyjne, ponieważ w konstrukcji należy zweryfikować dużą liczbę warunków, a wyżej wymienione parametry są ustalone jako funkcja trzech podstawowych warunków, które są kolejno przestrzegane: bezpieczeństwo konstrukcyjne, maksymalna ciągliwość przy zniszczeniu i minimalny koszt. Reguły projektowania, wyrażone za pomocą równań, pozwalają na pierwsze rozwiązanie, które jest korygowane tak, aby spełniało wszystkie scenariusze obliczeniowe, ostatecznie zbieżne, gdy różnica między parametrami wejściowymi i wyjściowymi jest nieistotna. W niektórych przypadkach możliwe jest opracowanie algorytmów optymalizacyjnych, których analityczne sformułowanie otwiera drogę do wygenerowania bazy danych. Hadi wykonał tę pracę dla belek żelbetowych podpartych w prosty sposób, a wyrażenia uzyskane po procesie optymalizacji określają parametry określone powyżej, przy jednoczesnym przypisaniu kosztu związanego z optymalnym rozwiązaniem (związanego z kosztem materiałów i deskowania). Za pomocą tych wyrażeń Hadi opracowuje bazę danych z następującymi zmiennymi: zastosowany moment zginający (M), wytrzymałość betonu na ściskanie (fc), wytrzymałość stali (fy), szerokość przekroju (b), głębokość przekroju (h) oraz koszty jednostkowe betonu (Cc), stali (Cs) i deskowania (Cf). Użyte parametry sieci są następujące. Liczba próbek treningowych wynosi 550; liczba neuronów warstwy wejściowej wynosi 8; liczba neuronów warstwy ukrytej wynosi 10; liczba neuronów warstwy wyjściowej wynosi 4; typ propagacji wstecznej to propagacja wsteczna Levenberga-Marquardta; funkcja aktywacji jest funkcją sigmoidalną; szybkość uczenia się; 0,01; liczba epok wynosi 3000; suma kwadratów błędu wynosi 0,08. Sieć została przetestowana na 50 próbkach i dała średni błąd 6,1%. Hadi bada różne czynniki przy wyborze architektury sieci i typu algorytmu propagacji wstecznej. Gdy używane są dwie warstwy ukrytych neuronów, precyzja nie ulega poprawie, podczas gdy czas obliczeń wzrasta. Liczba próbek zależy od złożoności problemu i liczby parametrów wejściowych i wyjściowych. Jeśli wartość kosztów wejściowych jest stała, nie ma zauważalnych ulepszeń precyzji między trenowaniem sieci z 200 lub 1000 próbek. Gdy koszty są wprowadzane jako parametry wejściowe, 100 próbek nie wystarcza do osiągnięcia zbieżności w treningu. Na koniec sprawdzany jest również algorytm treningowy, badając zakres między czystą propagacją wsteczną (zbyt wolną do treningu), propagacją wsteczną z pędem i adaptacyjnym uczeniem się, propagacją wsteczną z regułą aktualizacji Levenberga-Marquardta i szybką propagacją wsteczną uczenia się. Ta ostatnia jest ostatecznie zachowana, ponieważ wymaga mniej czasu, aby sieć zbiegła się, zapewniając jednocześnie bardzo dobre wyniki
Zastosowanie sztucznych sieci neuronowych do przewidywania mierzalnych parametrów fizycznych betonu: wytrzymałości i konsystencji betonu
Inne zastosowania sieci neuronowych są wspierane przez duże bazy danych eksperymentalnych, tworzone przez lata badań, które pozwalają na przewidywanie zjawisk o złożonej formulacji analitycznej. Jednym z takich przypadków jest określenie dwóch podstawowych parametrów betonu: jego urabialności po wymieszaniu, niezbędnej do łatwego umieszczania w betonie, oraz jego wytrzymałości na ściskanie po stwardnieniu, która jest podstawą oceny nośności konstrukcji. Zmiennymi, które koniecznie określają te dwa parametry, są składniki betonu: ilości cementu, wody, drobnego kruszywa (piasku), grubego kruszywa (drobnego żwiru i dużego żwiru) oraz inne składniki, takie jak dodatki pucolanowe (które zapewniają solidność i opóźniony wzrost wytrzymałości, szczególnie w przypadku popiołu lotnego i pyłu krzemionkowego) i domieszki (które upłynniają świeżą mieszankę, umożliwiając użycie zmniejszonych ilości wody). Nadal nie ma modeli analitycznych ani numerycznych, które wiernie przewidują konsystencję świeżego betonu (związaną z płynnością i zwykle ocenianą na podstawie opadu uformowanego stożka betonowego) lub wytrzymałość na ściskanie (określoną przez kruszenie pryzmatycznych próbek w prasie). Öztaş i inni opracowali sieć neuronową na podstawie 187 mieszanek betonowych, dla których znane są wszystkie parametry, wykorzystując 169 z nich do treningu i 18 wybranych losowo do weryfikacji. Zmienne bazy danych są czasami traktowane jako stosunek między nimi, ponieważ dostępna jest wiedza na temat zależności opadu i wytrzymałości od takich parametrów.Architektura sieci, określona przez 7 neuronów wejściowych i dwie ukryte warstwy odpowiednio 5 i 3 neuronów. Algorytm uczenia się wstecznej propagacji został użyty w dwóch ukrytych warstwach z sprzężeniem do przodu. Algorytm uczenia się użyty w badaniu to algorytm skalowanych gradientów sprzężonych (SCGA), funkcja aktywacji jest funkcją sigmoidalną, a liczba epok wynosi 10 000. Zdolność predykcyjna sieci jest lepsza w przypadku wyjścia "Wytrzymałość na ściskanie" (maksymalny błąd 6%) niż w przypadku wyjścia "Opad" (błędy do 25%). Wynika to z faktu, że związek między wybranymi zmiennymi a wytrzymałością jest znacznie silniejszy niż w przypadku opadu, na który wpływają inne nieuwzględniane zmienne (np. rodzaj i moc betoniarki, kolejność mieszania składników, wilgotność kruszywa) oraz metoda pomiaru konsystencji, której adekwatność dla konkretnego rodzaju betonu użytego w bazie danych jest kwestionowana przez niektórych autorów.
Zastosowanie sztucznych sieci neuronowych do opracowywania wzorów i kodów projektowych
Ostatnim zastosowaniem przedstawionym w tym artykule jest analiza odpowiedzi na siły ścinające w belkach betonowych. Siły te generują poprzeczne naprężenia rozciągające w belkach betonowych, które wymagają umieszczenia prętów zbrojeniowych prostopadle do osi belki, znanych jako obręcze lub wiązania. Analityczne określenie obciążenia niszczącego ze zmiennych, które wpływają na ten problem, jest bardzo złożone i ogólnie rzecz biorąc większość wzorów stosowanych obecnie opiera się na eksperymentalnych interpolacjach bez spójności wymiarowej. Cladera i Marí zbadali ten problem poprzez testy laboratoryjne, opracowując sieć neuronową do analizy wytrzymałości belek bez zbrojenia ścinającego. Opierają się na bazie danych skompilowanej przez Bentza i Kuchmę, gdzie zmiennymi są efektywna głębokość (d), szerokość belki (b, choć wprowadzono ją jako d/b), rozpiętość ścinania, współczynnik zbrojenia podłużnego (?l = As/bd) i wytrzymałość betonu na ściskanie (fc). Oczywiście obciążenie niszczące jest podawane dla każdego z 177 testów znalezionych w bazie danych. Używają 147 testów do trenowania sieci i 30 do weryfikacji, na architekturze jednowarstwowej z 10 ukrytymi neuronami i mechanizmem uczenia się retropropagacji. Aby uzyskać najlepsze wyniki, potrzebnych było prawie 8000 iteracji. Dostosowanie dostarczone przez trening przedstawia średni współczynnik Vtest/Vpred wynoszący 0,99 i 1,02 w walidacji. Autorzy skutecznie stworzyli laboratorium z siecią neuronową, w którym "testują" (w zakresie parametrów) nowe belki, zmieniając wyłącznie jeden parametr za każdym razem. Na koniec wymyślają dwa alternatywne wzory projektowe, które zauważalnie poprawiają każdy dany wzór opracowany do tego momentu. Tabela 3 przedstawia porównanie tych dwóch wyrażeń (nazwanych równaniem 7 i równaniem 8) z innymi znalezionymi w serii międzynarodowych kodów.Ö
WNIOSEK
• Dziedzina betonu konstrukcyjnego wykazuje duży potencjał do zastosowania sieci neuronowych. Przedstawiono udane podejścia do optymalizacji, przewidywania złożonych parametrów fizycznych i opracowywania wzorów projektowych. Topologia sieci stosowana w większości przypadków dla betonu konstrukcyjnego jest typu forward-feed, wielowarstwowa z propagacją wsteczną, zazwyczaj z jedną lub dwiema ukrytymi warstwami. Najczęściej stosowanymi algorytmami szkoleniowymi są gradient zstępujący z pędem i adaptacyjne uczenie się oraz Levenberg-Marquardt.
• Największym potencjałem sieci neuronowych jest ich zdolność do generowania wirtualnych laboratoriów testowych, które zastępują precyzyjne drogie rzeczywiste testy laboratoryjne w odpowiednim zakresie wartości. Metodyczny program "testowania" rzuca światło na wpływ różnych zmiennych w złożonych zjawiskach przy obniżonych kosztach.
• Dziedzina betonu konstrukcyjnego opiera się na rozległych bazach danych, generowanych przez lata, które można analizować za pomocą tej techniki. Należy podjąć wysiłki w celu skompilowania i ujednolicenia tych baz danych w celu wyodrębnienia maksymalnej możliwej wiedzy, która ma duży wpływ na bezpieczeństwo konstrukcyjne.
Zautomatyzowana kryptoanaliza
WSTĘP
Klasyczne szyfry służą do szyfrowania wiadomości tekstowych napisanych w języku naturalnym w taki sposób, że są one czytelne tylko dla nadawcy lub zamierzonego odbiorcy. Wiele klasycznych szyfrów można złamać metodą siłowego przeszukiwania przestrzeni klucza. Jednym z istotnych problemów pojawiających się w zautomatyzowanej kryptoanalizie jest rozpoznawanie tekstu jawnego. Komputer powinien być w stanie zdecydować, które z wielu możliwych odszyfrowania są sensowne. Można to osiągnąć za pomocą funkcji punktacji tekstu, opartej np. na n-gramach lub innych statystykach tekstu. Funkcja punktacji może być również używana w połączeniu z metodami AI w celu przyspieszenia kryptoanalizy.
TŁO
Rozpoznawanie języka to dziedzina sztucznej inteligencji badająca, jak wykorzystywać komputery do rozpoznawania języka tekstu. Jest to proste zadanie, gdy mamy wystarczającą ilość tekstu z akcentami, ponieważ charakteryzują one używany język z bardzo dużą dokładnością. Obecnie istnieje wiele zestawów narzędzi, które automatycznie sprawdzają/korygują często zarówno błędy ortograficzne, jak i gramatyczne. W związku z tym przypominamy również ocenę rozpoznawania języka NIST (LRE-05, LRE-07) jako część trwającej serii ocen technologii rozpoznawania języka. McMahon i Smith (1998) przedstawiają przegląd technik przetwarzania języka naturalnego opartych na modelach statystycznych. Przypominamy kilka podstawowych pojęć z kryptografii (więcej szczegółów można znaleźć w artykule zautomatyzowana kryptoanaliza klasycznych szyfrów). Istnieje odwracalna reguła szyfrowania (algorytm), jak przekształcić tekst jawny w tekst zaszyfrowany i odwrotnie. Algorytmy te zależą od tajnego parametru K zwanego kluczem. Zestaw możliwych kluczy K nazywany jest przestrzenią kluczy. Wejściem i wyjściem tych algorytmów jest ciąg liter z tekstu jawnego lub alfabetu tekstu zaszyfrowanego. Zarówno nadawca, jak i odbiorca używają tego samego tajnego klucza i tych samych algorytmów szyfrowania i deszyfrowania. Kryptoanaliza to proces odzyskiwania klucza lub odzyskiwania tekstu jawnego bez znajomości klucza. W obu przypadkach potrzebujemy podprogramu rozpoznawania tekstu jawnego, który ocenia (z pewnym prawdopodobieństwem) każdy kandydujący podciąg, czy jest to poprawny tekst jawny, czy nie. Takie automatyczne rozpoznawanie tekstu wymaga odpowiedniego modelu używanego języka.
ROZPOZNAWANIE TEKSTU JAWNEGO DLA AUTOMATYCZNEJ KRYPTANALIZY
W procesie automatycznej kryptoanalizy odszyfrowujemy tekst zaszyfrowany wieloma możliwymi kluczami, aby uzyskać kandydujące teksty jawne. Większość kandydatów jest niepoprawna, nie mająca znaczenia w języku naturalnym. Z drugiej strony, nawet poprawny tekst jawny może być trudny do rozpoznania, a przy złej procedurze rozpoznawania może zostać całkowicie pominięty. Podstawowym typem algorytmu odpowiednim do automatycznej kryptoanalizy jest atak siłowy. Ten atak jest wykonalny tylko wtedy, gdy przestrzeń kluczy jest przeszukiwalna w zasobach obliczeniowych dostępnych dla atakującego. Średni czas potrzebny do zweryfikowania kandydata silnie wpływa na rozmiar przeszukiwanej przestrzeni kluczy. Zatem rozpoznawanie tekstu jawnego jest najważniejszą częścią algorytmu z punktu widzenia wydajności. Z drugiej strony, tylko najbardziej złożone algorytmy osiągają naprawdę wysoką dokładność rozpoznawania tekstu jawnego. Zatem złożoność i dokładność algorytmów rozpoznawania tekstu jawnego muszą być starannie zrównoważone. Algorytm integruje trzy warstwy rozpoznawania tekstu jawnego, a mianowicie predykat testu negatywnego, szybką funkcję punktacji i precyzyjną funkcję punktacji, jako filtr trójwarstwowy. Ostateczna funkcja punktacji jest również używana do sortowania wyników. Pierwszy filtr powinien być bardzo szybki, z bardzo niskim prawdopodobieństwem błędu. Szybki wynik powinien być łatwy do obliczenia, ale nie jest wymagany do precyzyjnej identyfikacji poprawnego tekstu jawnego. Poprawne rozpoznawanie tekstu jawnego jest rolą precyzyjnej funkcji punktacji. W algorytmie najlepszy wynik jest najwyższy. Jeśli wynik jest obliczany w przeciwnym znaczeniu, algorytm musi zostać odpowiednio przepisany. W niektórych przypadkach możemy zintegrować szybką funkcję punktacji w teście negatywnym lub z precyzyjną punktacją, co prowadzi do filtrów dwuwarstwowych. Możliwe jest również użycie jeszcze większej liczby kroków filtrowania opartego na predykatach i wynikach. Jednak eksperymenty pokazują, że proponowana architektura trzech warstw jest najbardziej elastyczna, a więcej warstw może nawet prowadzić do spadku wydajności.
Filtrowanie negatywne
Celem predykatu testu negatywnego jest identyfikacja tekstów kandydackich, które NIE są tekstem jawnym (z bardzo dużym prawdopodobieństwem, w idealnym przypadku z pewnością). Ludzie mogą wyraźnie rozpoznać zły tekst, po prostu na niego patrząc. Implementacja tej zdolności w komputerach należy do dziedziny sztucznej inteligencji. Jednak większość współczesnych metod AI (np. sieci neuronowe) wydaje się być zbyt wolna, aby można ją było zastosować na tym etapie algorytmu siłowego, ponieważ każdy tekst musi zostać oceniony za pomocą tego predykatu. Większość metod szybkiego filtrowania tekstu negatywnego opiera się na zabronionych n-gramach. Jako n-gram rozważalibyśmy tylko sekwencję n kolejnych liter. Jeśli rozmiar alfabetu wynosi N, możliwe jest utworzenie Nn możliwych n-gramów. W przypadku wyższego n tylko niewielka ich część może pojawić się w prawidłowym tekście w danym języku. Korzystając z drzewa leksykalnego lub tabeli wyszukiwania, można łatwo (i szybko) sprawdzić, czy dany n-gram jest prawidłowy, czy nie. Tak więc naturalnym testem jest sprawdzenie każdego n-gramu w tekście, czy jest poprawny, czy nie. Istnieją dwa podstawowe problemy wynikające z tego podejścia - prawdziwy tekst jawny może zawierać (umyślnie) błędnie napisane, nietypowe lub obce słowa, a zatem nasza baza danych n-gramów może być niekompletna. Możemy ograniczyć nasz test do pewnych określonych wzorców, np. zbyt długiego ciągu następujących po sobie samogłosek/spółgłosek. Wzorce te można sprawdzić w czasie zależnym od długości kandydata tekstu jawnego. Filtr może również opierać się na sprawdzaniu tylko kilku n-gramów w ustalonej lub losowej pozycji w tekście, np. pierwszych czterech literach. Reguła odrzucania tekstów powinna opierać się na dokładnym typie szyfru, który próbujemy rozszyfrować. Na przykład, jeśli pierwsze cztery litery odszyfrowanego tekstu jawnego nie zależą od jakiejś części klucza, filtr oparty tylko na ich poprawności nie będzie skuteczny. Interesującym pytaniem jest, czy możliwe jest stworzenie systemu, który może skutecznie uczyć się swoich reguł filtrowania z istniejących odszyfrowanych tekstów, nawet w procesie odszyfrowywania.
Funkcje punktacji
Dzięki krokowi negatywnego filtra możemy wyeliminować około 90% lub więcej tekstów kandydackich. Liczba tekstów do zweryfikowania jest nadal bardzo duża, dlatego musimy zastosować bardziej precyzyjne metody rozpoznawania tekstu jawnego. Używamy funkcji punktacji, która przypisuje wartość - wynik - każdemu tekstowi, który przetrwał eliminację w poprzednich krokach. Tutaj wyższy wynik oznacza większe prawdopodobieństwo, że dany tekst jest prawidłowym tekstem jawnym. Dla każdej funkcji punktacji możemy przypisać próg i powinno być bardzo mało prawdopodobne, aby prawidłowy tekst jawny miał wynik poniżej tego progu. Rzeczywistą wartość progową można znaleźć albo eksperymentalnie (poprzez ocenę dużej liczby rzeczywistych tekstów), albo może być oparta na analizie statystycznej. Szybkość funkcji punktacji można określić, używając klasycznych szacunków złożoności algorytmu. Precyzję punktacji można zdefiniować za pomocą rozdzielenia prawidłowych i nieprawidłowych tekstów jawnych. Istnieje kompromis związany z punktacją, ponieważ szybsze funkcje punktacji są mniej precyzyjne i odwrotnie. Dlatego stosujemy dwie funkcje punktacji: jedną, która jest szybka, ale mniej precyzyjna, z niższą wartością progową, i jedną, która jest bardzo precyzyjna, ale trudniejsza do obliczenia. Przykład rozkładów funkcji punktacji można znaleźć na poniższych rysunkach.
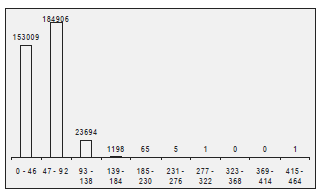
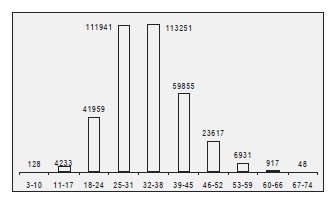
Funkcja punktacji na rysunku pierwszym jest znacznie dokładniejsza niż na rysunku drugim, ale czas obliczeniowy wymagany do oceny jest podwojony. Co więcej, funkcja punktacji na rysunku pierwszym została utworzona ze zmniejszonego słownika dopasowanego do danego szyfrogramu. Ocena oparta na kompletnym słowniku jest wolniejsza, trudniejsza do wdrożenia i może być nawet mniej precyzyjna. Funkcje punktacji mogą być oparte na słowach słownikowych, statystykach n-gramów lub innych konkretnych statystykach. Trudno jest zapewnić uniwersalną funkcję punktacji, ponieważ proces deszyfrowania dla różnych typów szyfrów ma wpływ na rzeczywiste wyniki funkcji punktacji. Np. podczas próby odszyfrowania szyfru transpozycyjnego wiemy już, które litery pojawiają się z jaką częstotliwością, a zatem statystyki oparte na częstotliwości liter nie odgrywają żadnej roli w punktacji. Z drugiej strony są one dość znaczące dla szyfrów podstawieniowych. Najczęstsze uniwersalne funkcje punktacji to :
1. Liczba słów słownikowych w tekście / ułamek znaczącego tekstu. Punktacja oparta na słowach słownikowych jest bardzo precyzyjna, jeśli mamy wystarczająco duży słownik. Nawet jeśli nie każde słowo w ukrytej wiadomości znajduje się w naszym słowniku, jest bardzo mało prawdopodobne, że jakieś nieprawidłowe odszyfrowanie zawiera większą część tekstu złożoną ze słów słownikowych. Usunięcie krótkich słów ze słownika może zwiększyć precyzję. Inną możliwością jest użycie wag opartych na długości słowa. Słowa słownikowe można znaleźć za pomocą drzew leksykalnych. W niektórych językach powinniśmy używać słownika rdzeni słów, zamiast całych słów. Szybkość oceny zależy odpowiednio od długości tekstu i średniej długości słów w słowniku.
2. Odległość rangowa n-gramów. Ranga n-gramu to jego pozycja zależna od kolejności opartej na częstościach n-gramów (połączona dla wszystkich n do danej granicy zależnej od języka). Ta metoda jest stosowana w szybkim automatycznym rozpoznawaniu języka: obliczanie rang n-gramów danego tekstu i porównywanie ich z rangami znaczących n-gramów uzyskanymi z dużego korpusu różnych języków. Poprawny język powinien mieć najmniejszą odległość. Nawet jeśli tę metodę można dostosować do rozpoznawania tekstu jawnego, np. poprzez tworzenie "losowego" korpusu lub korpusu zaszyfrowanego, nie wydaje się to praktyczne.
3. Częstotliwość odległości statystyk n-gramowych. Wynik tekstu można oszacować na podstawie różnicy zmierzonej częstości n-gramów i szacowanych częstości z dużego korpusu. Zakładamy, że poprawny tekst jawny będzie miał najmniejszą odległość od statystyk korpusowych. Jednak ze względu na właściwości statystyczne tekstu nie zawsze jest to prawdą w przypadku krótkich lub szczegółowych tekstów. Dlatego precyzja tej funkcji punktacji jest wyższa w przypadku dłuższych tekstów. Szybkość oceny zależy od rozmiaru tekstu i rozmiaru n.
4. Tabele punktacji dla n-gramów. Jeśli weźmiemy pod uwagę statystyki wszystkich n-gramów, zobaczymy, że większość n-gramów wnosi bardzo małą wartość do końcowego wyniku. Możemy wziąć pod uwagę wkład tylko najpopularniejszych n-gramów. Dla danego języka (i danego szyfrogramu) możemy przygotować tabelę wyników n-gramów ze stałą liczbą wpisów. Wynik jest oceniany jako suma punktów przypisanych do n-gramów w danym tekście kandydackim. Możemy przypisać zarówno dodatnie wyniki dla typowych prawidłowych n-gramów, jak i ujemne wyniki dla typowych nieprawidłowych/rzekomo rzadkich n-gramów. Jednak precyzja tej metody jest bardzo niska, szczególnie w przypadku szyfrów transpozycyjnych. W naszych eksperymentach wyniki mają rozkład normalny, a zazwyczaj poprawny tekst jawny nie ma najwyższych możliwych wartości. Z drugiej strony, ta funkcja punktacji jest łatwa do oceny i może być dostosowana do danego szyfrogramu. Dlatego może być używana jako szybka funkcja punktacji fastScore(X). 5. Wskaźnik koincydencji (i inne podobne statystyki) Wskaźnik koincydencji, oznaczony jako IC, jest odpowiednią i szybką statystyką stosowaną do szyfrów, które modyfikują częstotliwość występowania liter. Pojęcie to pochodzi z prawdopodobieństwa wystąpienia tej samej litery w dwóch różnych tekstach w tej samej pozycji. Zaszyfrowane teksty są uważane za losowe i mają (znormalizowany) wskaźnik koincydencji bliski 1,0. Z drugiej strony, tekst jawny ma znacznie wyższy IC w pobliżu wartości oczekiwanej dla danego języka i alfabetu. Dla języka angielskiego oczekiwana wartość wynosi 1,73. Jak w przypadku wszystkich statystyk opartych na funkcji punktacji, jej precyzja jest zależna od długości tekstu. Wskaźnik koincydencji jest najbardziej odpowiedni dla szyfrów polialfabetycznych, w których szyfrowanie zależy od położenia litery w tekście (np. szyfr Vigenère′a). Można go dostosować do innych typów szyfrów, np. do szyfrów transpozycyjnych, biorąc pod uwagę, że alfabet jest tworzony przez wszystkie możliwe n-gramy z pewnym n > 1.
PRZYSZŁE TRENDY
Przetwarzanie i rozpoznawanie języka mają zastosowanie w różnych obszarach poza kryptoanalizą (OCR, automatyczne tłumaczenie). Niektóre techniki kryptoanalityczne można uogólnić dla tych dziedzin. Np. niektóre litery lub grupy liter są często zastępowane innymi w zeskanowanych dokumentach. W związku z tym korygowanie tych dokumentów jest podobne do kryptoanalizy szyfrów podstawieniowych. Dzięki badaniom nad sztuczną inteligencją można uzyskać nowe spostrzeżenia na temat struktury języka naturalnego, które mogą pomóc w dalszej kryptoanalizie. Kryptoanaliza jest również ściśle związana z wysiłkami automatycznego tłumaczenia. Niektóre otwarte problemy, które muszą zostać rozwiązane przez rozpoznawanie języka odpowiednie do kryptoanalizy klasycznych szyfrów, to:
• W jaki sposób rozpoznawanie tekstu powinno być zintegrowane z procesem deszyfrowania, aby zapewnić sprzężenie zwrotne, np. w przypadku częściowo odszyfrowanych słów, oszacować nowy klucz itp. Jest to szczególnie ważne, jeśli użyjemy bardziej zaawansowanej heurystyki wyszukiwania niż wyszukiwanie siłowe w przestrzeni kluczy.
• W jaki sposób składnia i semantyka języka mogą pomóc w rozpoznawaniu tekstu i wyszukiwaniu kluczy.
• W jaki sposób różne kodowania i systemy pisma wpływają na kryptoanalizę. Specyficzne problemy pojawiają się przy pracy z różnymi systemami pisma .
• Jak prawidłowo rozpoznawać tekst z celowymi błędami ortograficznymi i specjalnymi słowami kodowymi.
Inny zestaw problemów pojawia się, gdy używane są różne języki naturalne, takie jak rozpoznawanie języka, określone alfabety, wpływ znaków diakrytycznych itp. Nasze badania pokazują, że język wiadomości zaszyfrowanej szyfrem podstawieniowym można rozpoznać nawet bez deszyfrowania. Możliwe jest nawet użycie słownika innego (choć podobnego) języka w procesie deszyfrowania. Interesującym pytaniem badawczym jest to, czy możliwe jest stworzenie całkowicie ogólnej funkcji rozpoznawania języka (lub ograniczonej do pewnej rodziny języków) nadającej się do kryptoanalizy. Rozpoznawanie tekstu jawnego w kryptoanalizie można również postrzegać jako specyficzny problem wyszukiwania informacji . Wyszukiwanie informacji wielojęzycznych ma na celu podobne problemy do problemów przedstawionych powyżej . Badania w tych obszarach mogą wyraźnie na siebie wpływać w przyszłości.
WNIOSEK
W tym artykule podsumowano wykorzystanie i ograniczenia przetwarzania języka w kontekście kryptoanalizy klasycznych szyfrów. Ich zastosowanie zwykle różni się w zależności od charakteru analizowanych systemów szyfrów, chociaż przedstawiliśmy kilka typowych technik, które można łatwo dostosować do konkretnej sytuacji. Większość ataków kryptoanalitycznych wymaga bardzo szybkiego rozpoznawania języka, ale z drugiej strony duża prędkość często powoduje niedokładne wyniki, aż do punktu nierozpoznawalnych odszyfrowań. Rolą badań nad sztuczną inteligencją jest znajdowanie szybszych i bardziej precyzyjnych predykatów językowych i łączenie ich w użyteczny system rozpoznawania tekstu jawnego.
Do zrobienia!
Zautomatyzowana kryptoanaliza klasycznych szyfrów
WSTĘP
Klasyczne szyfry służą do szyfrowania wiadomości tekstowych zapisanych w języku naturalnym w taki sposób, że są one czytelne tylko dla nadawcy lub zamierzonego odbiorcy. Wiele klasycznych szyfrów można złamać metodą siłowego przeszukiwania przestrzeni klucza. Metody sztucznej inteligencji, takie jak heurystyka optymalizacyjna, można wykorzystać do zawężenia przestrzeni wyszukiwania, przyspieszenia przetwarzania tekstu i rozpoznawania tekstu w procesie kryptoanalizy. Przedstawiamy tutaj szeroki przegląd różnych technik AI, które można wykorzystać w kryptoanalizie klasycznych szyfrów. W następnej części Zautomatyzowana kryptoanaliza - Przetwarzanie języka omówiono konkretne metody skutecznego rozpoznawania prawidłowo odszyfrowanego tekstu spośród wielu możliwych odszyfrowanych.
TŁO
Kryptoanalizę można postrzegać jako próbę przetłumaczenia tekstu zaszyfrowanego (zaszyfrowanego tekstu) na język ludzki. Kryptoanalizę można zatem powiązać z lingwistyką obliczeniową. Obszar ten powstał w wyniku wysiłków podejmowanych w Stanach Zjednoczonych w latach 50. XX wieku, aby komputery automatycznie tłumaczyły teksty z języków obcych na angielski, w szczególności rosyjskie czasopisma naukowe. Obecnie jest to dziedzina badań poświęcona opracowywaniu algorytmów i oprogramowania do inteligentnego przetwarzania danych językowych. Systematyczne (publiczne) wysiłki na rzecz automatyzacji kryptoanalizy przy użyciu komputerów można prześledzić do pierwszych prac napisanych pod koniec lat 70. Jednak obszar badań nadal ma wiele otwartych problemów, ściśle związanych z obszarem sztucznej inteligencji. Z obecnego stanu wiedzy można wnioskować, że chociaż komputery są bardzo przydatne w wielu zadaniach kryptoanalitycznych, ludzka inteligencja jest nadal niezbędna w kompletnej kryptoanalizie. Dla wygody czytelnika przypominamy kilka podstawowych pojęć z kryptografii. Bardzo dokładny przegląd klasycznych szyfrów został napisany przez Kahna (1974). Wiadomość do zaszyfrowania (tekst jawny) jest napisana małymi literami P = {a, b, c
x, y, z}. Zaszyfrowana wiadomość (tekst szyfrowany) jest napisana wielkimi literami alfabetu C = {A, B, C
X, Y, Z}. Różne alfabety są używane w celu lepszego odróżnienia tekstu jawnego od tekstu szyfrowanego. W rzeczywistości te alfabety są takie same. Istnieje odwracalna reguła szyfrowania (algorytm), jak przekształcić tekst jawny w tekst szyfrowany i odwrotnie. Algorytmy te zależą od tajnego parametru K zwanego kluczem. Zestaw możliwych kluczy K nazywany jest przestrzenią kluczy. Dane wejściowe i wyjściowe tych algorytmów to ciąg liter z odpowiednich alfabetów, P* i C*. Zarówno nadawca, jak i odbiorca używają tego samego tajnego klucza i tych samych algorytmów szyfrowania i deszyfrowania. Istnieją trzy podstawowe klasyczne systemy szyfrowania wiadomości, a mianowicie podstawienie, transpozycja i klucz bieżący. W szyfrze podstawieniowym ciąg liter jest zastępowany innym ciągiem liter przy użyciu przepisanej substytucji pojedynczych liter, np. od lewej "a" do "A", zastępując literę "b" literą "N", literę "c" literą "G" itd. Szyfr transpozycyjny zmienia kolejność liter zgodnie z tajnym kluczem K. W przeciwieństwie do szyfrów podstawieniowych częstotliwość liter w tekście jawnym i szyfrogramie pozostaje taka sama. Ta cecha jest wykorzystywana do rozpoznawania, że tekst został zaszyfrowany przez jakiś szyfr transpozycyjny. Typowy szyfr z kluczem bieżącym polega na wyprowadzeniu z klucza głównego K klucza bieżącego K0 K1 K2 …Kn. Jeśli P = C = K jest grupą, to po prostu yi = eK( xi) = xi + Ki . Dlatego wygodnie jest zdefiniować algorytm szyfrowania dla szyfrów klasycznych w następujący sposób:
Definicja 1: Klasyczny system szyfrów to pięciokrotność (P, C, K, E, D), gdzie spełnione są następujące warunki:
1. P jest skończonym zbiorem alfabetu tekstu jawnego, a P* zbiorem wszystkich skończonych ciągów symboli z P.
2. C jest skończonym zbiorem alfabetu szyfrogramu, a C* zbiorem wszystkich skończonych ciągów symboli z C
3. K jest skończonym zbiorem możliwych kluczy.
4. Dla każdego K ∈ K istnieje algorytm szyfrowania eK ∈ E i odpowiadający mu algorytm deszyfrowania dK ∈ D taki, że dK (eK(x)) = x dla każdego wejścia x ∈ P i K ∈ K.
5. Algorytm szyfrowania przypisuje dowolnemu skończonemu ciągowi x0 x1 x2…xn z P* wynikowy ciąg szyfrogramu y0 y1 y2…yn z C*, gdzie yi = eK(xi) . Rzeczywisty klucz może lub nie musi zależeć od indeksu i.
Innym typowym przypadkiem dla P i C są r-krotności alfabetu łacińskiego. W przypadku szyfrów transpozycyjnych klucz jest okresowo powtarzany dla r-krotności. W przypadku szyfrów podstawieniowych r-krotności kluczem jest r-krotność kluczy. W przypadku kluczy bieżących istnieje inny generator strumienia kluczy g: K × P → K, który generuje z początkowego klucza K i ewentualnie z tekstu jawnego x0 x1 x2&hellup;
xn-1 rzeczywisty klucz Kn . W przypadku szyfrów klasycznych występują dwie typowe sytuacje, gdy próbujemy odzyskać tekst jawny:
1. Niech dane wejściowe do algorytmu deszyfrującego dK ∈ D z nieznanym kluczem K będą ciągiem tekstu zaszyfrowanego y0 y1K y2 …ynn z C*, gdzie yi = eK( xi). Naszym celem jest znalezienie ciągu tekstu jawnego x0 x1 x2…xn z P*. Tak więc w każdym wykonaniu algorytm przeszukuje przestrzeń kluczy K.
2. Algorytm deszyfrowania dK ∈ D i klucz K są nieznane. Naszym celem jest 2nalezienie dla ciągu szyfrogramu y0 y1 y2&hellup;ynK z C*, gdzie yi = eK( xi), ciągu jawnego tekstu x0 x1 x2…xn z P*. Wymaga to innego algorytmu niż rzeczywisty dK ∈ D, a także pewnych dodatkowych informacji. Zwykle dostępny jest inny szyfrogram, powiedzmy z0 z1 z2K…zn z C*. Tak więc w każdym wykonaniu algorytm przeszukuje możliwe podstawienia, które są odpowiednie dla obu szyfrogramów.
W obu przypadkach potrzebujemy podprogramu rozpoznawania tekstu jawnego, który ocenia kandydacki podciąg o długości v dla możliwego tekstu jawnego, powiedzmy ct c1+t c2+t …c+t := xt x1+t x2+t…xv+t . Takie automatyczne rozpoznawanie tekstu wymaga odpowiedniego modelu używanego języka.
AUTOMATYCZNA KRYPTANALIZA
Istnieją dwie proste metody automatycznej kryptoanalizy. Niestety, żadna z nich nie nadaje się do dłuższych ciągów znaków w praktyce. Pierwsza z nich dotyczy szyfrów transpozycyjnych. Gdy nie są znane żadne inne informacje o szyfrze, możemy użyć ogólnej metody, zwanej anagramowaniem, aby rozszyfrować wiadomość. W tej metodzie próbujemy złożyć sensowny ciąg znaków (anagram) z szyfrogramu. Osiąga się to poprzez ułożenie liter w słowa ze słownika. Gdy znajdziemy sensowne słowo, przetwarzamy resztę wiadomości w ten sam sposób. Gdy nie jesteśmy w stanie utworzyć bardziej sensownych słów, cofamy się i próbujemy innych możliwych słów, aż znajdziemy cały sensowny anagram. Druga, bardzo podobna, metoda dotyczy szyfrów podstawieniowych. Tutaj próbujemy złożyć sensowny ciąg znaków (anagram) z szyfrogramu, przeszukując wszystkie możliwe podstawienia liter, aby uzyskać słowa ze słownika używanego języka. Chociaż rozmiar przestrzeni klucza jest duży, automatyczna kryptoanaliza wykorzystuje wiele innych metod opartych np. na rozkładzie częstości liter. Automatyczna kryptoanaliza prostych szyfrów podstawieniowych może odszyfrować większość wiadomości zarówno ze znanymi granicami słów , jak i bez tych informacji . Istnieją inne klasyczne szyfry, w których transpozycja lub podstawienie zależy nie tylko od rzeczywistego klucza, ale także od pozycji w bloku liter ciągu. Do skutecznej automatycznej kryptoanalizy wymagane są co najmniej dwie warstwy przetwarzania kandydatów w postaci jawnego tekstu, filtrowania i punktowania. Lepsze wyniki uzyskuje się poprzez dodatkowe warstwy filtrujące. To oczywiście zwiększa złożoność obliczeniową. Poniżej przedstawiamy przegląd tych warstw filtrujących.
Zautomatyzowane ataki siłowe
Podstawowym typem algorytmu nadającego się do zautomatyzowanej kryptoanalizy jest atak siłowy. Ponieważ musimy przeszukać całą przestrzeń kluczy, ten atak jest wykonalny tylko wtedy, gdy przestrzeń kluczy nie jest "zbyt duża". Dokładne określenie ilościowe przeszukiwalnej przestrzeni kluczy zależy od zasobów obliczeniowych dostępnych dla atakującego i średniego czasu potrzebnego do weryfikacji kandydata na odszyfrowany tekst. Zatem rozpoznawanie tekstu jawnego jest najważniejszą częścią algorytmu z punktu widzenia wydajności. Z drugiej strony, tylko najbardziej złożone algorytmy osiągają naprawdę wysoką dokładność rozpoznawania tekstu jawnego. Dlatego też wymagana jest ostrożna równowaga między złożonością algorytmów rozpoznawania tekstu jawnego a jego dokładnością. Jest mało prawdopodobne, aby zautomatyzowana kryptoanaliza dawała tylko jeden możliwy wynik, ale możliwe jest ograniczenie zestawu możliwych odszyfrowania do rozmiaru, który można opanować. Zgłoszone wyniki powinny być sortowane według prawdopodobieństwa, że są prawdziwym tekstem jawnym. Zidentyfikowaliśmy trzy warstwy rozpoznawania tekstu jawnego, a mianowicie negatywny predykat testowy, szybką funkcję punktacji i precyzyjną funkcję punktacji. Wszystkie trzy funkcje są używane jako filtr trójwarstwowy, a ostateczna funkcja punktacji jest również używana do sortowania wyników. Pierwszy filtr powinien być bardzo szybki i powinien mieć bardzo niskie prawdopodobieństwo błędu. Szybki wynik powinien być łatwy do obliczenia, ale nie jest wymagany do precyzyjnej identyfikacji poprawnego tekstu jawnego. Poprawne rozpoznawanie tekstu jawnego jest rolą precyzyjnej funkcji punktacji. W algorytmie najlepszy wynik jest najwyższy. Jeśli wynik jest obliczany w przeciwnym znaczeniu, algorytm musi zostać odpowiednio przepisany. W niektórych przypadkach możemy zintegrować szybką funkcję punktacji w negatywnym teście lub z precyzyjną punktacją, co prowadzi do filtrów dwuwarstwowych. Możliwe jest również użycie jeszcze większej liczby kroków filtrowania opartego na predykatach i wynikach. Jednak eksperymenty pokazują, że proponowana architektura trzech warstw jest najbardziej elastyczna, a więcej warstw może nawet prowadzić do spadku wydajności.
Zastosowania metod sztucznej inteligencji
Metody sztucznej inteligencji (AI) można stosować w czterech głównych obszarach zautomatyzowanej kryptoanalizy:
1. Rozpoznawanie tekstu jawnego: Celem AI jest dostarczanie predykatów negatywnych, które filtrują błędne odszyfrowania, oraz funkcji punktacji, które oceniają podobieństwo tekstu do języka naturalnego.
2. Heurystyka wyszukiwania klucza: Celem AI jest dostarczanie heurystyk w celu przyspieszenia procesu odszyfrowywania, albo poprzez ograniczenie przestrzeni klucza, albo poprzez kierowanie wyborem kolejnych kluczy do wypróbowania w odszyfrowaniu. Ten obszar jest najczęściej badany, ponieważ może dostarczyć jasnych wyników eksperymentalnych i znaczącej oceny.
3. Oszacowanie tekstu jawnego: Celem AI jest oszacowanie znaczenia tekstu jawnego na podstawie częściowego odszyfrowania lub oszacowanie niektórych części tekstu jawnego na podstawie danych zewnętrznych (np. nadawcy szyfrogramu, kontekstu historycznego i geograficznego, określonych reguł gramatycznych itp.). Oszacowane części tekstu jawnego mogą następnie prowadzić do znacznie łatwiejszego całkowitego odszyfrowania. Ten obszar badań jest w większości niezbadany, a oszacowanie tekstu jawnego jest wykonywane przez kryptoanalityka.
4. Automatyczna ocena bezpieczeństwa: Celem kryptoanalizy jest nie tylko łamanie szyfrów i poznawanie sekretów, ale jest ona również wykorzystywana podczas tworzenia nowych szyfrów w celu oceny ich bezpieczeństwa. Chociaż większość klasycznych szyfrów jest już "przestarzała", ich kryptoanaliza jest nadal ważna, np. w nauczaniu nowoczesnych zasad bezpieczeństwa komputerowego. Podczas nauczania klasycznych szyfrów przydatne jest posiadanie narzędzia AI (np. systemu eksperckiego), które może zautomatyzować ocenę bezpieczeństwa szyfru (przynajmniej przy niektórych słabszych założeniach). Chociaż włożono wiele pracy w automatyczną ocenę nowoczesnych protokołów bezpieczeństwa, nie znamy niektórych narzędzi służących do oceny projektów "klasycznych" szyfrów.
Obszarem, który najlepiej jest zbadać, jest obszar heurystyki wyszukiwania kluczy. Wynika to bezpośrednio z faktu, że przeszukiwanie metodą siłową całej przestrzeni kluczy można uznać za bardzo prymitywną metodę deszyfrowania. Większość klasycznych szyfrów nie została zaprojektowana z uwzględnieniem statystyk tekstu. Możemy przypisać wynik dla każdego klucza w przestrzeni kluczy, który jest skorelowany z prawdopodobieństwem, że tekst odszyfrowany danym kluczem jest tekstem jawnym. Wynik, gdy jest rozpatrywany w przestrzeni kluczy, z pewnością ma pewne lokalne maksima, które mogą prowadzić bezpośrednio do sensownego tekstu jawnego lub tekstu, z którego tekst jawny jest łatwo odgadnięty. Dlatego może być przydatne rozważenie różnych technik relaksacyjnych w celu przeszukiwania przestrzeni kluczy w celu maksymalizacji funkcji punktacji. Jedną z najwcześniejszych demonstracji technik relaksacyjnych w celu złamania szyfrów podstawieniowych przedstawili Peleg & Rosenfeld (1979) oraz Hunter & McKenzie (1983). Udane ataki mające zastosowanie do wielu klasycznych szyfrów mogą być implementowane przy użyciu podstawowego wspinania się na wzgórze, poprzez przeszukiwanie tabu, symulowane wyżarzanie i zastosowania algorytmów genetycznych/ewolucyjnych. Algorytmy genetyczne osiągnęły wiele sukcesów w łamaniu klasycznych szyfrów, jak zademonstrowali Mathews (1993) lub Clark (1994), i mogą nawet złamać maszynę wirnikową. Russell, Clark & Stepney (1998) przedstawiają atak anagramowy przy użyciu rozwiązywacza opartego na algorytmie optymalizacji kolonii mrówek. Tego typu ataki próbują zbiec do poprawnego klucza poprzez małe zmiany rzeczywistego klucza. Współczynnik powodzenia ataków jest zwykle mierzony ułamkiem zrekonstruowanego klucza i/lub tekstu. Metody relaksacyjne mogą z dużym prawdopodobieństwem znaleźć klucze lub przybliżenia tekstu jawnego, nawet jeśli nie jest wykonalne przeszukanie całej przestrzeni kluczy. Sukces zależy głównie od rozmiaru szyfrogramu, ponieważ punktacja jest zwykle oparta na statystykach. Jednym z niezbadanych wyzwań jest rozważenie zastosowania wielu technik relaksacji. Po pierwsze, można użyć heurystyki, aby zmniejszyć przestrzeń klucza, a następnie albo brutalne wyszukiwanie, albo inna heurystyka jest używana z większą precyzją, aby zakończyć odszyfrowanie.
TRENDY PRZYSZŁOŚCI
Uzyskane wyniki w dużym stopniu zależą od rozmiaru szyfrogramu, a odszyfrowania są zwykle tylko częściowe. Techniki automatycznej kryptoanalizy muszą być również dopasowane do danego problemu. Np. ataki na szyfry podstawieniowe mogą wykorzystywać statystyki pojedynczych liter, ale w przypadku ataków przeznaczonych na szyfry transpozycyjne statystyki te są niezmienne i nie mają sensu ich stosowanie. Zautomatyzowana kryptoanaliza jest zwykle badana tylko w kontekście tych dwóch głównych typów szyfrów, ale istnieje szeroki obszar niezbadanych problemów dotyczących różnych klasycznych typów szyfrów, takich jak uruchamianie szyfrów typu klucza. Konkretne zastosowania technik AI mogą zawieść w przypadku niektórych kryptosystemów, jak wskazali Wagner, S., Affenzeller, M. i Schragl, D. (2004). Kryptoanaliza zależy również od języka , chociaż istnieją pewne godne uwagi wyjątki, jeśli chodzi o podobne języki. Wraz ze wzrostem mocy obliczeniowej, nawet niedawno używane szyfry, takie jak Data Encryption Standard (DES), stają się przedmiotem zautomatyzowanej kryptoanalizy. Oprócz zastosowania heurystyki do kryptoanalizy, konieczne są dalsze badania w obszarach szacowania tekstu jawnego i automatycznej oceny bezpieczeństwa. System ekspercki, który obejmowałby te obszary i łączył je ze sztuczną inteligencją do rozpoznawania tekstu jawnego i heurystyki wyszukiwania, może być silnym narzędziem do nauczania bezpieczeństwa komputerowego lub do pomocy w analizie kryminalistycznej lub badaniach historycznych obejmujących zaszyfrowane materiały.
WNIOSEK
Niniejszy artykuł dotyczy zautomatyzowanej kryptoanalizy klasycznych szyfrów, gdzie klasyczne szyfry są uważane za szyfry sprzed II wojny światowej lub szyfry ołówkowo-papierowe. Heurystyki optymalizacyjne są dość skuteczne w atakach na te szyfry, ale zazwyczaj nie można ich w pełni zautomatyzować. Ich zastosowanie zazwyczaj różni się w zależności od charakteru analizowanych systemów szyfrów. Ważnym kierunkiem badań jest rozszerzenie technik od klasycznej kryptoanalizy do zautomatyzowanego deszyfrowania nowoczesnych cyfrowych kryptosystemów. Innym ważnym problemem jest stworzenie zestawu w pełni zautomatyzowanych narzędzi kryptoanalitycznych lub kompletnego systemu eksperckiego, który można dostosować do różnych typów szyfrów i języków.
Powrót