
Diagnostyka defektów przemysłowych urządzeń optycznych oparta na sieciach neuronowych
WSTĘP
Głównym krokiem w diagnostyce usterek urządzeń optycznych wysokiej jakości jest wykrywanie i charakteryzowanie defektów w postaci zarysowań i wgłębień w produktach. Tego rodzaju wady estetyczne, ukształtowane podczas różnych etapów produkcji, mogą powodować szkodliwe skutki dla specyfiki funkcjonalnej urządzeń optycznych, a także dla ich wydajności optycznej, generując niepożądane światło rozproszone, które może poważnie uszkodzić oczekiwane cechy optyczne. Wiarygodna diagnoza tych wad staje się zatem kluczowym zadaniem w celu zapewnienia nominalnej specyfikacji produktów. Co więcej, taka diagnoza jest silnie motywowana wymogami korekcji procesu produkcyjnego w celu zagwarantowania jakości produkcji masowej w celu utrzymania akceptowalnej wydajności produkcji. Niestety wykrywanie i mierzenie takich wad nadal stanowi trudny problem w warunkach produkcji, a nieliczne dostępne rozwiązania automatycznej kontroli pozostają nieskuteczne. Dlatego w większości przypadków diagnoza jest przeprowadzana na podstawie wizualnej inspekcji całej produkcji przez eksperta. Jednak to konwencjonalnie stosowane rozwiązanie cierpi na kilka ostrych ograniczeń związanych z wewnętrznymi ograniczeniami operatora (zmniejszona czułość na bardzo małe defekty, zmiana wyczerpującego wykrywania z powodu kurczenia się uwagi, zmęczenie operatora i znużenie z powodu powtarzalnego charakteru zadań wykrywania i diagnostyki błędów). Aby zbudować skuteczny system automatycznej diagnostyki, proponujemy podejście oparte na czterech głównych operacjach: wykrywaniu defektów, ekstrakcji danych, redukcji wymiarowości i klasyfikacji neuronowej. Pierwsza operacja opiera się na obrazowaniu mikroskopowym Nomarskiego. Te obrazy zawierają kilka elementów, które muszą zostać wykryte, a następnie sklasyfikowane w celu rozróżnienia defektów "fałszywych" (defektów możliwych do skorygowania) od defektów "trwałych" (stałych). Rzeczywiście, ze względu na środowisko przemysłowe, szereg defektów możliwych do skorygowania (takich jak kurz lub ślady czyszczenia) jest zwykle obecnych obok potencjalnych defektów "trwałych". Ekstrakcja istotnych cech jest kluczową kwestią w celu zapewnienia dokładności systemu klasyfikacji neuronowej; po pierwsze, ponieważ surowe dane (obrazy) nie mogą być wykorzystane, a ponadto, ponieważ praca z danymi o dużej liczbie wymiarów może mieć wpływ na wydajność uczenia się sieci neuronowej. W tym artykule przedstawiono system automatycznej diagnostyki, opisując działanie różnych faz. Przeprowadzono implementację na rzeczywistych przemysłowych urządzeniach optycznych, a eksperyment bada klasyfikację elementów opartą na sztucznej sieci neuronowej MLP.
TŁO
Obecnie jedynym rozwiązaniem, które istnieje w celu wykrywania i klasyfikowania defektów powierzchni optycznych, jest rozwiązanie wizualne, przeprowadzane przez eksperta. Pierwsza oryginalność tej pracy dotyczy zastosowanego czujnika: mikroskopii Normarskiego. Trzy główne zalety odróżniające mikroskopię Nomarskiego (znaną również jako "mikroskopia kontrastu różnicowo-interferencyjnego" od innych technik mikroskopowych, uzasadniają nasze preferencje dla tej techniki obrazowania. Pierwsza z nich jest związana z wyższą czułością tej techniki w porównaniu do innych klasycznych technik mikroskopowych. Ponadto mikroskopia DIC jest odporna na niejednorodność oświetlenia. Wreszcie, ta technologia dostarcza informacji względnych do głębokości (3-wymiar), które mogą być wykorzystane do określenia chropowatości lub głębokości defektu. Ta ostatnia zaleta oferuje cenny dodatkowy potencjał do scharakteryzowania rys i wad wgłębień w zaawansowanych technologicznie urządzeniach optycznych. Dlatego mikroskopia Nomarskiego wydaje się być odpowiednią techniką wykrywania niedoskonałości powierzchni. Z drugiej strony, ponieważ wykazały wiele atrakcyjnych cech w złożonych zadaniach rozpoznawania i klasyfikacji wzorców , techniki oparte na sztucznych sieciach neuronowych są wykorzystywane do rozwiązywania trudnych problemów. W naszym konkretnym przypadku problem jest związany z klasyfikacją małych defektów na dużej powierzchni obserwacyjnej. Te obiecujące techniki mogą jednak napotkać trudności w przypadku danych o dużej liczbie wymiarów. Dlatego interesują nas również metody redukcji wymiarowości danych.
DETEKCJA I KLASYFIKACJA DEFEKTÓW
Sugerowany proces diagnozy jest opisany w ogólnym zarysie na schemacie na Rysunku 1. Przedstawiono każdy krok, najpierw fazy wykrywania i ekstrakcji danych, a następnie fazę klasyfikacji połączoną z redukcją wymiarowości. W drugiej części przeprowadzono pewne badania na rzeczywistych danych przemysłowych i przedstawiono uzyskane wyniki.
Wykrywanie i ekstrakcja danych
Celem etapu wykrywania defektów jest ekstrakcja obrazów defektów z cyfrowego obrazu wydanego przez detektor DIC. Proponowana metoda (Voiry, Houbre, Amarger i Madani, 2005) obejmuje cztery fazy:
o Wstępne przetwarzanie: transformacja cyfrowego obrazu wydanego przez DIC w celu zmniejszenia wpływu niejednorodności oświetlenia i zwiększenia widoczności docelowych defektów,
o Dopasowanie adaptacyjne: proces adaptacyjny w celu dopasowania defektów,
o Filtrowanie i segmentacja: usuwanie szumów i charakteryzacja zarysów defektów.
o Ekstrakcja obrazu defektu: poprawna konstrukcja reprezentacji defektu.
Na koniec obraz powiązany z danym wykryciem daje izolowaną (od innych elementów) reprezentację defektu (np. przedstawia defekt w jego bezpośrednim otoczeniu), jak pokazano na rysunku 2. Jednak informacje zawarte w tak wygenerowanych obrazach są wysoce redundantne, a obrazy te niekoniecznie mają ten sam wymiar (zwykle ten wymiar może okazać się sto razy większy). Dlatego te surowe dane (obrazy) nie mogą być bezpośrednio przetwarzane i muszą być najpierw odpowiednio zakodowane, przy użyciu pewnych transformacji. Takie transformacje muszą być naturalnie niezmienne w odniesieniu do transformacji geometrycznych (translacja, obrót i skalowanie) i odporne na różne zaburzenia (szum, zmienność luminancji i zmienność tła). Transformacja Fouriera-Mellina jest używana, ponieważ zapewnia niezmienne deskryptory, które są uważane za mające dobrą zdolność kodowania w zadaniach klasyfikacyjnych. Na koniec przetworzone cechy muszą zostać znormalizowane, przy użyciu transformacji centrującej-redukującej. Dostarczenie zestawu 13 cech przy użyciu takiej transformacji jest pierwszym akceptowalnym kompromisem między ograniczeniami przetwarzania w czasie rzeczywistym w środowisku przemysłowym a jakością reprezentacji obrazu defektowego.
Redukcja wymiarowości
Aby uzyskać poprawny opis defektów, musimy wziąć pod uwagę mniej lub bardziej istotną liczbę niezmienników Fouriera-Mellina. Jednak praca z danymi o dużej liczbie wymiarów stwarza problemy, znane jako "przekleństwo wymiarowości". Po pierwsze, liczba próbek wymagana do osiągnięcia wstępnie zdefiniowanego poziomu precyzji w zadaniach aproksymacyjnych rośnie wykładniczo wraz z wymiarem. Tak więc, intuicyjnie, liczba próbek potrzebna do prawidłowego nauczenia się problemu staje się szybko zbyt duża, aby mogła być zebrana przez rzeczywiste systemy, gdy wymiar danych wzrasta. Ponadto, podczas pracy w dużym wymiarze pojawiają się zaskakujące zjawiska: na przykład, wariancja odległości między wektorami pozostaje stała, podczas gdy jej średnia wzrasta wraz z wymiarem przestrzennym, a lokalne właściwości jądra Gaussa są również tracone. Te ostatnie punkty wyjaśniają, że zachowanie wielu algorytmów sztucznej sieci neuronowej może być zmienione podczas pracy z danymi o dużej liczbie wymiarów. Na szczęście większość danych dotyczących rzeczywistych problemów znajduje się w rozmaitości o wymiarze p (wymiar wewnętrzny danych), znacznie mniejszym niż jej wymiar surowy. Zmniejszenie wymiarowości danych do tej mniejszej wartości może zatem zmniejszyć problemy związane z wysokim wymiarem. Aby zmniejszyć wymiarowość problemu, stosujemy analizę odległości krzywoliniowej (CDA). Ta technika jest związana z analizą składowych krzywoliniowych (CCA), której celem jest odtworzenie topologii oryginalnej przestrzeni n-wymiarowej w nowej przestrzeni p-wymiarowej (gdzie p
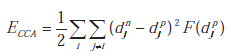
Gdzie dm
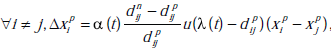
Gdzie 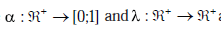 są dwiema funkcjami malejącymi, reprezentującymi odpowiednio parametr uczenia i czynnik sąsiedztwa. CCA zapewnia również podobną metodę, aby rzutować, w sposób ciągły, nowe punkty w oryginalnej przestrzeni na przestrzeń rzutowaną, wykorzystując wiedzę o już rzutowanych wektorach. Jednak ponieważ CCA napotyka trudności z rozwijaniem bardzo nieliniowych rozmaitości, zaproponowano ewolucję zwaną CDA . Obejmuje ona odległości krzywoliniowe (w celu lepszego przybliżenia odległości geodezyjnych na rozważanej rozmaitości) zamiast odległości euklidesowych. Odległości krzywoliniowe są przetwarzane w dwuetapowy sposób. Najpierw budowany jest graf między wektorami, biorąc pod uwagę k-NN, e lub inne sąsiedztwo, ważone odległością euklidesową między sąsiednimi węzłami. Następnie odległość krzywoliniowa między dwoma wektorami jest obliczana jako minimalna odległość między tymi wektorami na wykresie przy użyciu algorytmu Dijkstry. Na koniec oryginalny algorytm CCA jest stosowany przy użyciu przetworzonych odległości krzywoliniowych. Ten algorytm pozwala na radzenie sobie z bardzo nieliniowymi rozmaitościami i jest znacznie bardziej odporny na wybory funkcji a i l. Został on pomyślnie użyty jako wstępny krok przed klasyfikacją maksymalnego prawdopodobieństwa , a my pokazaliśmy również jego pozytywny wpływ na wydajność klasyfikacji opartej na technice sieci neuronowych . W tym ostatnim artykule po raz pierwszy wykazaliśmy, że problem syntetyczny (mimo to zdefiniowany na podstawie naszych rzeczywistych danych przemysłowych), którego wewnętrzna wymiarowość wynosi dwa, jest lepiej traktowany przez MLP po redukcji wymiarów 2D niż w jego surowym wyrażeniu. Pokazaliśmy również, że CDA działa lepiej w przypadku tego problemu niż CCA i wstępne przetwarzanie Self Organizing Map.
są dwiema funkcjami malejącymi, reprezentującymi odpowiednio parametr uczenia i czynnik sąsiedztwa. CCA zapewnia również podobną metodę, aby rzutować, w sposób ciągły, nowe punkty w oryginalnej przestrzeni na przestrzeń rzutowaną, wykorzystując wiedzę o już rzutowanych wektorach. Jednak ponieważ CCA napotyka trudności z rozwijaniem bardzo nieliniowych rozmaitości, zaproponowano ewolucję zwaną CDA . Obejmuje ona odległości krzywoliniowe (w celu lepszego przybliżenia odległości geodezyjnych na rozważanej rozmaitości) zamiast odległości euklidesowych. Odległości krzywoliniowe są przetwarzane w dwuetapowy sposób. Najpierw budowany jest graf między wektorami, biorąc pod uwagę k-NN, e lub inne sąsiedztwo, ważone odległością euklidesową między sąsiednimi węzłami. Następnie odległość krzywoliniowa między dwoma wektorami jest obliczana jako minimalna odległość między tymi wektorami na wykresie przy użyciu algorytmu Dijkstry. Na koniec oryginalny algorytm CCA jest stosowany przy użyciu przetworzonych odległości krzywoliniowych. Ten algorytm pozwala na radzenie sobie z bardzo nieliniowymi rozmaitościami i jest znacznie bardziej odporny na wybory funkcji a i l. Został on pomyślnie użyty jako wstępny krok przed klasyfikacją maksymalnego prawdopodobieństwa , a my pokazaliśmy również jego pozytywny wpływ na wydajność klasyfikacji opartej na technice sieci neuronowych . W tym ostatnim artykule po raz pierwszy wykazaliśmy, że problem syntetyczny (mimo to zdefiniowany na podstawie naszych rzeczywistych danych przemysłowych), którego wewnętrzna wymiarowość wynosi dwa, jest lepiej traktowany przez MLP po redukcji wymiarów 2D niż w jego surowym wyrażeniu. Pokazaliśmy również, że CDA działa lepiej w przypadku tego problemu niż CCA i wstępne przetwarzanie Self Organizing Map.
Implementacja na przemysłowych urządzeniach optycznych
Aby zweryfikować przedstawione powyżej koncepcje i dostarczyć przemysłowy prototyp, zrealizowano automatyczny system sterowania. Obejmuje on mikroskop Olympus B52 połączony ze stolikiem Corvus, który umożliwia skanowanie całego komponentu optycznego . Zastosowano 50-krotne powiększenie, co prowadzi do mikroskopijnych pól 1,77 mm x 1,33 mm i pikseli o rozmiarze 1,28 μm x 1,28 μm. Proponowana metoda przetwarzania obrazu jest stosowana on-line. Oprogramowanie do postprodukcji umożliwia zebranie fragmentów defektu, które są wykrywane w różnych polach mikroskopowych (na przykład fragmentów długiej rysy), aby utworzyć tylko jeden defekt, i obliczyć ogólną kartografię sprawdzanego urządzenia . Te urządzenia zostały wykorzystane do uzyskania dużej liczby obrazów Nomarskiego, z których wyodrębniono obrazy defektów przy użyciu wspomnianej techniki. Przeprowadzono dwa eksperymenty zwane A i B, przy użyciu dwóch różnych urządzeń optycznych. Tabela 1 przedstawia różne parametry odpowiadające tym eksperymentom. Ważne jest, aby zauważyć, że w celu uniknięcia uczenia się fałszywych klas, obrazy elementów przedstawiające mikroskopijne granice pól lub dwa (lub więcej) różne defekty zostały odrzucone z używanej bazy danych. Ponadto badane urządzenia optyczne nie były specjalnie czyszczone, co tłumaczy obecność niektórych pyłów i śladów czyszczenia. Elementy tych dwóch baz danych zostały oznaczone przez eksperta dwoma różnymi etykietami: "kurz" (klasa 1) i "inne defekty" (klasa -1). Tabela 1 przedstawia również podział elementów między dwie zdefiniowane klasy. Korzystając z tego eksperymentalnego układu, przeprowadzono eksperyment klasyfikacyjny. Najpierw tę sztuczną sieć neuronową wytrenowano do zadania dyskryminacji między klasami 1 i -1, używając bazy danych B. Ta faza szkolenia używała BFGS z algorytmem regularyzacji bayesowskiej i została osiągnięta 5 razy. Następnie zdolność generalizacji uzyskanej sieci neuronowej została przetworzona przy użyciu bazy danych A. Ponieważ bazy danych A i B zostały wydane z różnych urządzeń optycznych, takie wyniki generalizacji są znaczące. Zgodnie z tą procedurą przeprowadzono 14 różnych eksperymentów w celu zbadania globalnej wydajności klasyfikacji i wpływu redukcji wymiarowości CDA na tę wydajność. W pierwszym eksperymencie wykorzystano oryginalne cechy wydane przez Fourriera-Mellina (13-wymiarowe), pozostałe wykorzystały te same cechy po redukcji przestrzeni n-wymiarowej CDA (z n zmieniającym się między 2 a 13). W konsekwencji złożoność architektury neuronowej, a zatem czas przetwarzania, można zaoszczędzić, używając redukcji wymiarowości CDA, przy jednoczesnym zachowaniu poziomu wyników. Ponadto uzyskane wyniki są zadowalające: około 70% defektów "pyłowych" jest dobrze rozpoznawanych (może to wystarczyć do zamierzonego zastosowania), podobnie jak około 97% innych defektów (nieliczne błędy 3% mogą jednak stanowić problem, ponieważ każdy "stały" defekt musi zostać zgłoszony). Ponadto uważamy, że ta znacząca różnica w wynikach między rozpoznawaniem klasy 1 a klasy -1 wynika z faktu, że klasa 1 jest niedoreprezentowana w bazie danych uczenia się.
PRZYSZŁE TRENDY
Kolejna faza tej pracy będzie dotyczyć zadań klasyfikacyjnych obejmujących więcej klas. Chcemy również użyć znacznie więcej niezmienników Fouriera-Mellina, ponieważ uważamy, że poprawiłoby to wydajność klasyfikacji poprzez dostarczanie dodatkowych informacji. W tym przypadku technika redukcji wymiarowości oparta na CDA byłaby najważniejszym krokiem w celu utrzymania rozsądnej złożoności systemu klasyfikacji i czasu przetwarzania.
WNIOSEK
Niezawodna diagnoza wad estetycznych w wysokiej jakości urządzeniach optycznych jest kluczowym zadaniem w celu zapewnienia nominalnej specyfikacji produktów i poprawy jakości produkcji poprzez badanie wpływu procesu na takie wady. Aby zapewnić niezawodną diagnozę, potrzebny jest automatyczny system do wykrywania wad, a po drugie, do odróżniania wad "fałszywych" (wad korygowanych) od wad "trwałych" (stałych). W tym artykule opisano kompletne ramy, które umożliwiają wykrywanie wszystkich wad obecnych w surowym obrazie Nomarskiego i wyodrębnianie odpowiednich cech w celu klasyfikacji tych wad. Uzyskane prawidłowe wyniki dla klasyfikacji defektów "kurzu" w porównaniu z "innymi" za pomocą sieci neuronowej MLP wykazały trafność proponowanego podejścia. Ponadto redukcja wymiarowości danych pozwala na użycie klasyfikatora o niskiej złożoności (przy zachowaniu poziomu wydajności), a tym samym na zaoszczędzenie czasu przetwarzania.
Powrót