
KLUCZOWE TERMINY
Heurystyczne aktywne uczenie się: Zbiór algorytmów aktywnego uczenia się, w którym kryteria wyboru próby opierają się na jakiejś heurystycznej funkcji celu. Na przykład aktywne uczenie się oparte na przestrzeni wersji polega na wybraniu próbki, która może zmniejszyć rozmiar przestrzeni wersji.
Przestrzeń hipotez: zbiór wszystkich hipotez, w którym zakłada się, że zostanie znaleziona hipoteza obiektywna.
Uczenie się częściowo nadzorowane: Zestaw algorytmów uczenia się, w którym zarówno oznakowane, jak i nieoznaczone dane w zbiorze danych uczących są bezpośrednio wykorzystywane do uczenia klasyfikatora.
Statystyczne aktywne uczenie się: Zbiór algorytmów aktywnego uczenia się, w którym kryteria doboru próby opierają się na pewnej statystycznej funkcji celu, takiej jak minimalizacja błędu uogólnienia, obciążenia systematycznego i wariancji. Statystyczne aktywne uczenie się jest zwykle statystycznie optymalne.
Uczenie się nadzorowane: Zbiór algorytmów uczenia się, w którym wszystkie próbki w zbiorze danych szkoleniowych są oznaczone etykietami.
Uczenie się bez nadzoru: Zbiór algorytmów uczenia się, w którym wszystkie próbki w zbiorze danych szkoleniowych są nieoznaczone.
Przestrzeń wersji: Podzbiór przestrzeni hipotez zgodny ze zbiorem uczącym.
Adaptacyjny model geometryczny (AGM): nowe podejście do obliczeń geometrycznych wykorzystujące paradygmat obliczeń adaptacyjnych. W modelu zastosowano kryteria ciągłego udoskonalania oparte na metryce błędu, aby optymalnie dostosować się do dokładniejszej reprezentacji.
Adaptacyjna technika wielu rozdzielczości (AMRT): Do wizualizacji terenu w czasie rzeczywistym jest to metoda, która wykorzystuje sprytny sposób dynamicznej optymalizacji siatki w celu zapewnienia płynnej i ciągłej wizualizacji z dużą wydajnością.
Adaptacyjna pamięć przestrzenna (ASM): Metoda hybrydowa oparta na połączeniu tradycyjnej hierarchicznej struktury drzewiastej z koncepcją rozwijania lub zwijania węzłów drzewa.
Technologia biometryczna (BT): obszar badań cech fizycznych i behawioralnych w celu uwierzytelnienia i identyfikacji osób.
Triangulacja Delaunaya (DT): struktura danych geometrii obliczeniowej podwójna do diagramu Woronoja.
Paradygmat ewolucyjny (EP): Zbiorcza nazwa szeregu metod rozwiązywania problemów wykorzystujących zasady ewolucji biologicznej, takie jak dobór naturalny i dziedziczenie genetyczne.
Inteligencja roju (SI): Właściwość systemu, dzięki której zbiorowe zachowania prostych agentów wchodzących w interakcję lokalnie ze swoim otoczeniem powodują wyłonienie się spójnych funkcjonalnych wzorców globalnych.
Techniki oparte na topologii (TBT): Grupa metod wykorzystujących właściwości geometryczne zbioru obiektów w przestrzeni i ich bliskość
Diagram Woronoja (VD): podstawowa struktura danych geometrii obliczeniowej, która przechowuje informacje topologiczne dla zbioru obiektów.
Adaptacyjna inteligencja biznesowa: dyscyplina polegająca na wykorzystaniu technik przewidywania i optymalizacji do budowania samouczących się systemów "decyzyjnych".
Business Intelligence: zbiór narzędzi, metod, technologii i procesów niezbędnych do przekształcenia danych w praktyczną wiedzę.
Dane: Elementy gromadzone codziennie w postaci bitów, liczb, symboli i "obiektów".
Eksploracja danych: zastosowanie metod i narzędzi analitycznych do danych w celu identyfikacji wzorców, relacji lub uzyskania systemów wykonujących przydatne zadania, takie jak klasyfikacja, przewidywanie, szacowanie lub grupowanie powinowactwa.
Informacja: "Zorganizowane dane", które są wstępnie przetwarzane, oczyszczane, układane w struktury i pozbawione nadmiarowości.
Wiedza: "zintegrowana informacja", która obejmuje fakty i relacje, które zostały dostrzeżone, odkryte lub wyuczone.
Optymalizacja: Proces znalezienia rozwiązania, które najlepiej pasuje do dostępnych zasobów.
Przewidywanie: stwierdzenie lub twierdzenie, że określone wydarzenie nastąpi w przyszłości.
Sztuczne sieci neuronowe (SSN): syntetyczny system przetwarzania informacji, składający się z kilku prostych nieliniowych jednostek przetwarzających, połączonych elementami posiadającymi funkcje przechowywania informacji i programowania, dostosowujące się i uczące na podstawie wzorców, co naśladuje biologiczną sieć neuronową.
Ślepa separacja źródeł (BSS): Separacja ukrytych, nieredundantnych (tj. wzajemnie statystycznie niezależnych lub dekorelowanych) sygnałów źródłowych ze zbioru mieszanin liniowych w taki sposób, że regularność każdego wynikowego sygnału jest maksymalizowana, a regularność między sygnałami jest minimalizowana (tj. niezależność statystyczna jest maksymalizowana) bez (prawie) jakichkolwiek informacji o źródłach.
Konfirmacyjna analiza danych (CDA): podejście, w którym po zebraniu danych następuje nałożenie wcześniejszego modelu oraz analiza, oszacowanie i przetestowanie parametrów modelu.
Eksploracyjna analiza danych (EDA): podejście polegające na umożliwieniu samym danym ujawnienia ich podstawowej struktury i modelu, w dużym stopniu wykorzystując zbiór technik zwanych grafiką statystyczną.
Niezależna analiza składowych (ICA): Eksploracyjna metoda rozdzielania liniowej mieszaniny ukrytych źródeł sygnału na niezależne składowe jako optymalne szacunki pierwotnych źródeł na podstawie ich wzajemnej niezależności statystycznej i niegaussa.
Reguła uczenia się: Strategia zmiany wagi w systemie koneksjonistycznym mająca na celu optymalizację określonej funkcji celu. Reguły uczenia się są stosowane iteracyjnie do danych wejściowych zbioru uczącego, przy czym błąd jest stopniowo zmniejszany w miarę dostosowywania się wag.
Analiza głównych składowych (PCA): ortogonalna transformacja liniowa oparta na dekompozycji wartości osobliwych, która rzutuje dane na podprzestrzeń zachowującą maksymalną wariancję.
Sztuczne sieci neuronowe (ANN): Sztuczna sieć neuronowa, często nazywana po prostu "siecią neuronową" (NN), to połączona grupa sztucznych neuronów, która wykorzystuje model matematyczny lub model obliczeniowy do przetwarzania informacji w oparciu o koneksjonistyczne podejście do obliczeń. Sieć nabywa wiedzę z otoczenia w procesie uczenia się, a siła połączeń międzyneuronowych (wagi synaptyczne) służy do przechowywania zdobytej wiedzy.
Ewoluująca rozmyta sieć neuronowa (EFuNN): Ewoluująca rozmyta sieć neuronowa to dynamiczna architektura, w której węzły reguł rosną w razie potrzeby i kurczą się w wyniku agregacji. Nowe jednostki reguł i połączenia można łatwo dodawać bez zakłócania istniejących węzłów. Schemat uczenia się często opiera się na koncepcji "węzła zwycięskiej reguły".
Logika rozmyta: Logika rozmyta to obszar zastosowań teorii zbiorów rozmytych, zajmujący się niepewnością w rozumowaniu. Wykorzystuje koncepcje, zasady i metody opracowane w ramach teorii zbiorów rozmytych do formułowania różnych form rozsądnego rozumowania przybliżonego. Logika rozmyta pozwala na ustawienie wartości członkostwa w zakresie (włącznie) od 0 do 1, a w swojej formie językowej pozwala na nieprecyzyjne pojęcia, takie jak "nieznacznie", "całkiem" i "bardzo". W szczególności umożliwia częściowe członkostwo w zestawie.
Rozmyte sieci neuronowe (FNN): to sieci neuronowe wzbogacone o możliwości logiki rozmytej, takie jak wykorzystanie danych rozmytych, reguł, zbiorów i wartości rozmytych. Systemy neurorozmyte (NFS): System neurorozmyty to system rozmyty, który wykorzystuje algorytm uczenia się wywodzący się z teorii sieci neuronowych lub inspirowany nią w celu określenia jego parametrów (zbiorów rozmytych i reguł rozmytych) poprzez przetwarzanie próbek danych.
Mapa samoorganizująca się (SOM): Samoorganizująca się mapa jest podtypem sztucznych sieci neuronowych. Jest szkolony przy użyciu uczenia się bez nadzoru w celu uzyskania niskowymiarowej reprezentacji próbek szkoleniowych, przy jednoczesnym zachowaniu właściwości topologicznych przestrzeni wejściowej. Samoorganizująca się mapa to jednowarstwowa sieć ze sprzężeniem zwrotnym, w której składnie wyjściowe są ułożone w niskowymiarową siatkę (zwykle 2D lub 3D). Każde wejście jest połączone ze wszystkimi neuronami wyjściowymi. Do każdego neuronu dołączony jest wektor wag o tej samej wymiarowości co wektory wejściowe. Liczba wymiarów wejściowych jest zwykle znacznie większa niż wymiar wyjściowy siatki. SOM są używane głównie do redukcji wymiarowości, a nie do rozszerzania.
Soft Computing: Soft Computing odnosi się do partnerstwa technik obliczeniowych w informatyce, sztucznej inteligencji, uczeniu maszynowym i niektórych dyscyplinach inżynieryjnych, które próbują badać, modelować i analizować złożone zjawiska. Głównymi partnerami w tym momencie są logika rozmyta, obliczenia neuronowe, rozumowanie probabilistyczne i algorytmy genetyczne. Zatem zasadą miękkiego przetwarzania danych jest wykorzystanie tolerancji na nieprecyzyjność, niepewność i częściową prawdę w celu osiągnięcia wykonalności, solidności, taniego rozwiązania i lepszego kontaktu z rzeczywistością.
Adaptacyjność: Właściwość struktur, które dynamicznie i autonomicznie zmieniają swoje zachowanie w odpowiedzi na bodźce wejściowe.
Adaptacyjny model obliczeniowy: abstrakcja o dużej mocy Turinga, która naśladuje zachowanie potencjalnie samomodyfikujących się złożonych systemów.
Urządzenie adaptacyjne: Struktura zachowująca się dynamicznie, z umieszczonym obok urządzeniem i mechanizmem adaptacyjnym.
Funkcje adaptacyjne i akcje adaptacyjne: Akcje adaptacyjne to wywołania funkcji adaptacyjnych, które mogą określić zmiany, jakie należy wprowadzić w zestawie reguł danej warstwy oraz w funkcjach adaptacyjnych warstwy znajdującej się bezpośrednio pod nimi.
Mechanizm adaptacyjny: dyscyplina zmian powiązana z zestawem reguł urządzenia adaptacyjnego, która zmienia zachowanie urządzenia znajdującego się obok niego poprzez wykonywanie działań adaptacyjnych.
Adaptacyjne urządzenie oparte na regułach: urządzenie adaptacyjne, którego zachowanie jest określone przez dynamicznie zmieniający się zestaw reguł, np.: automaty adaptacyjne, gramatyki adaptacyjne itp.
Zależność od kontekstu: reinterpretacja terminów ze względu na warunki występujące w innym miejscu zdania, np. zasady umowy w języku angielskim, sprawdzanie typu w Pascalu.
Formalizm kontekstowy (zależny): abstrakcja zdolna do reprezentowania języków Chomsky′ego typu 1 lub typu 0. Do wyrażania takich języków dobrze nadają się automaty adaptacyjne i adaptacyjne gramatyki bezkontekstowe.
Hierarchiczne (wielopoziomowe) urządzenie adaptacyjne: warstwowe struktury adaptacyjne, w których działania adaptacyjne warstwy mogą modyfikować zarówno reguły własnej warstwy, jak i funkcje adaptacyjne warstwy podstawowej.
Urządzenie sąsiadujące (lub bazowe): dowolne urządzenie wykorzystywane jako podstawa do formułowania urządzeń adaptacyjnych. Najbardziej wewnętrzna część wielopoziomowego urządzenia znajdującego się poniżej nie może być adaptacyjna
Bionika: zastosowanie metod i systemów występujących w przyrodzie do badania i projektowania systemów inżynieryjnych. Wydaje się, że słowo to powstało z połączenia "biologii" i "elektroniki" i zostało użyte po raz pierwszy przez J. E. Steele w 1958 roku.
Wielomian Czebyszewa: ważny rodzaj wielomianów stosowanych w interpolacji danych, zapewniający najlepsze przybliżenie funkcji ciągłej w ramach normy maksymalnej.
Zakres dynamiczny: Termin używany do opisania stosunku pomiędzy najmniejszymi i największymi możliwymi wartościami zmiennej wielkości.
FPGA: Akronim oznaczający Field-Programmable Gate Array, urządzenie półprzewodnikowe wynalezione w 1984 roku przez R. Freemana, które zawiera programowalne interfejsy i komponenty logiczne zwane "blokami logicznymi" służące do wykonywania funkcji podstawowych bramek logicznych (np. XOR) lub bardziej złożonych funkcje kombinowane, takie jak dekodery.
Odcinkowa funkcja liniowa: funkcja f(x), którą można podzielić na pewną liczbę odcinków liniowych, z których każdy jest zdefiniowany dla niezachodzącego na siebie przedziału x.
Splot przestrzenny: termin używany do określenia liniowej kombinacji serii dyskretnych danych 2D (obrazu cyfrowego) z kilkoma współczynnikami lub wagami. W teorii Fouriera splot w przestrzeni jest równoważny (przestrzennemu) filtrowaniu częstotliwości.
Szablon: Znany również jako jądro lub jądro splotu, to zestaw współczynników używanych do wykonywania operacji filtrowania przestrzennego na obrazie cyfrowym za pośrednictwem operatora splotu przestrzennego.
VLSI: Akronim oznaczający integrację na bardzo dużą skalę. Jest to proces tworzenia układów scalonych poprzez połączenie tysięcy (obecnie setek milionów) obwodów tranzystorowych w jeden układ scalony. Typowym urządzeniem VLSI jest mikroprocesor.
Modelowanie oparte na agentach: wykorzystanie inteligentnych agentów oraz ich działań i interakcji w danym środowisku do symulacji złożonej dynamiki systemu.
Dyfuzja innowacji: spopularyzowane przez Everetta Rogersa badanie procesu komunikowania i przyjmowania innowacji wśród członków systemu społecznego.
Inteligentny agent: autonomiczny program, który jest w stanie uczyć się i dostosowywać do swojego środowiska, aby wykonywać określone zadania powierzone mu przez jego mistrza.
Inteligentny system: system posiadający spójny zestaw komponentów i podsystemów współpracujących ze sobą w celu podejmowania działań zorientowanych na cel.
Inteligentne modelowanie systemów: proces konstruowania, kalibracji i walidacji modeli inteligentnych systemów.
System wieloagentowy: system rozproszony z grupą inteligentnych agentów, którzy komunikują się, targują, konkurują i współpracują z innymi agentami i otoczeniem, aby osiągnąć cele wyznaczone przez swoich mistrzów.
Inteligencja organizacyjna: zdolność organizacji do postrzegania, interpretowania i wybierania najwłaściwszej reakcji na otoczenie, aby osiągnąć swoje cele
Analiza kopuli: przekształca niegaussowskie rozkłady prawdopodobieństwa do wspólnej odpowiedniej przestrzeni (zwykle przestrzeni Gaussa), w której ma sens obliczanie korelacji jako momentów drugich.
DIME: Reprezentuje dyplomatyczne, informacyjne, wojskowe i ekonomiczne aspekty informacji, które należy połączyć w spójny wzór.
Globalna optymalizacja: odnosi się do zbioru algorytmów używanych do statystycznego próbkowania przestrzeni parametrów lub zmiennych w celu optymalizacji systemu, ale często jest również używany do próbkowania ogromnej przestrzeni w celu uzyskania informacji. Istnieje wiele wariantów, w tym symulowane wyżarzanie, algorytmy genetyczne, optymalizacja kolonii mrówek, wspinaczka po wzgórzach itp.
ISM: Anakronim dla Ideas by Statistical Mechanics w kontekście rzeczownika zdefiniowanego jako: Przekonanie (lub system przekonań) akceptowane jako autorytatywne przez jakąś grupę lub szkołę. Doktryna lub teoria; zwłaszcza teoria szalona lub wizjonerska. Charakterystyczna doktryna, teoria, system lub praktyka.
Meme: Nawiązuje do technologii pierwotnie zdefiniowanej w celu wyjaśnienia ewolucji społecznej, która została udoskonalona tak, aby oznaczała podobne do genu narzędzie analityczne do badania ewolucji kulturowej.
Pamięć: może mieć wiele form i mechanizmów. W tym przypadku w technologiach sztucznej inteligencji wykorzystywane są dwa główne procesy pamięci kory nowej, pamięć krótkotrwała (STM) i pamięć długoterminowa (LTM).
Symulowane wyżarzanie (SA): klasa algorytmów próbkowania z ogromnej przestrzeni, która ma matematyczny dowód zbieżności z globalnymi optymalnymi minimami. Większość algorytmów SA stosowanych w większości systemów nie wykorzystuje w pełni tego dowodu, ale dowód często jest przydatny, aby dać pewność, że system uniknie utknięcia na długi czas w lokalnych optymalnych regionach.
Mechanika statystyczna: Dział fizyki matematycznej zajmujący się układami o dużej liczbie stanów. Zastosowania nierównowagowej nieliniowej mechaniki statystycznej są obecnie powszechne w wielu dziedzinach, począwszy od nauk fizycznych i biologicznych, przez finanse, po informatykę itp.
Agent: W terminologii RL jest odpowiedzialny za podejmowanie decyzji zgodnie z obserwacjami swojego otoczenia.
Środowisko: W terminologii RL jest to każdy warunek zewnętrzny agenta.
Dylemat eksploracji-eksplotacji: Jest to klasyczny dylemat RL, w którym należy osiągnąć rozwiązanie kompromisowe. Eksploracja oznacza losowe poszukiwanie nowych działań w celu osiągnięcia prawdopodobnej (ale jeszcze nieznanej) lepszej nagrody niż wszystkie znane, podczas gdy eksploatacja koncentruje się na wykorzystaniu bieżącej wiedzy w celu maksymalizacji nagrody (podejście zachłanne).
Wartość w czasie życia: Jest to miara szeroko stosowana w aplikacjach marketingowych, która oferuje długoterminowy wynik, który należy zmaksymalizować.
Nagroda: W terminologii RL natychmiastowa nagroda to wartość zwracana przez otoczenie agentowi w zależności od podjętego działania. Długoterminowa nagroda to suma wszystkich natychmiastowych nagród w całym procesie decyzyjnym.
Wrażliwość: Podobna miara, która oferuje stosunek pozytywów, które są prawidłowo klasyfikowane przez model. Specyficzność: Miara wskaźnika sukcesu w problemie klasyfikacji. Jeśli istnieją dwie klasy (mianowicie, pozytywna i negatywna), specyficzność mierzy stosunek negatywów, które są poprawnie klasyfikowane przez model.
Sztuczne społeczeństwa: Złożone systemy, potencjalnie dużego, zbioru agentów, których interakcje są ograniczone normami i rolami, za które odpowiadają agenci.
Agenci poznawczy: Agenci oprogramowania obdarzeni wysokim poziomem postaw mentalnych, takimi jak przekonania, cele i plany.
Świadomość kontekstu: Odnosi się do idei, że komputery mogą zarówno wyczuwać, jak i reagować zgodnie ze stanem środowiska, w którym się znajdują. Urządzenia mogą posiadać informacje o okolicznościach, w których są w stanie działać i odpowiednio reagować.
Interakcja naturalna: Badanie relacji między ludźmi a maszynami mające na celu tworzenie interaktywnych artefaktów, które szanują i wykorzystują naturalną dynamikę, za pomocą której ludzie komunikują się i odkrywają prawdziwy świat.
Inteligentne domy: Domy wyposażone w inteligentne czujniki i urządzenia w ramach infrastruktury komunikacyjnej, która umożliwia różnym systemom i urządzeniom komunikowanie się ze sobą w celach monitorowania i konserwacji
Wszechobecne przetwarzanie: Model interakcji człowiek-komputer, w którym przetwarzanie informacji jest zintegrowane z codziennymi przedmiotami i czynnościami. W przeciwieństwie do paradygmatu pulpitu, w którym pojedynczy użytkownik wybiera interakcję z pojedynczym urządzeniem w wyspecjalizowanym celu, w przypadku przetwarzania wszechobecnego użytkownik wchodzi w interakcję z wieloma urządzeniami obliczeniowymi i systemami jednocześnie, w trakcie zwykłych czynności, i niekoniecznie musi być tego świadomy.
Sieci czujników bezprzewodowych: Sieci bezprzewodowe składające się z rozproszonych przestrzennie autonomicznych urządzeń wykorzystujących czujniki do wspólnego monitorowania warunków fizycznych lub środowiskowych, takich jak temperatura, dźwięk, wibracje, ciśnienie, ruch lub zanieczyszczenia, w różnych lokalizacjach.
Ambient Intelligence: Ambient Intelligence (AmI) zajmuje się nowym światem, w którym urządzenia komputerowe są wszędzie rozproszone, umożliwiając ludziom interakcję w środowiskach świata fizycznego w inteligentny i dyskretny sposób. Środowiska te powinny być świadome potrzeb ludzi, dostosowywać wymagania i prognozować zachowania.
Świadomość kontekstu: Świadomość kontekstu oznacza, że system jest świadomy bieżącej sytuacji, z którą mamy do czynienia.
Systemy wbudowane: Systemy wbudowane oznaczają, że urządzenia elektroniczne i komputerowe są osadzone w bieżących obiektach lub towarach.
Inteligentna sala decyzyjna: Przestrzeń podejmowania decyzji, np. sala konferencyjna lub centrum sterowania, wyposażona w inteligentne urządzenia i/lub systemy wspomagające procesy podejmowania decyzji.
Inteligentny dom: Dom wyposażony w kilka urządzeń elektronicznych i interaktywnych, które pomagają mieszkańcom w zarządzaniu konwencjonalnymi decyzjami domowymi.
Inteligentne systemy transportowe: Inteligentne systemy stosowane w obszarze transportu, a mianowicie w kwestiach ruchu drogowego i podróżowania.
Inteligentne pojazdy: Pojazd wyposażony w czujniki i komponenty wspomagające podejmowanie decyzji.
Wszechobecne przetwarzanie: Wszechobecne przetwarzanie jest powiązane ze wszystkimi fizycznymi częściami naszego życia, użytkownik może nie mieć pojęcia o urządzeniach obliczeniowych i szczegółach związanych z tymi fizycznymi częściami.
Wszechobecne przetwarzanie: Wszechobecne przetwarzanie oznacza, że mamy dostęp do urządzeń obliczeniowych w dowolnym miejscu w sposób zintegrowany i spójny.-
Automatyczne rozpoznawanie mowy: Rozpoznawanie maszynowe i konwersja wypowiedzianych słów na tekst.
Eksploracja danych: Zastosowanie metod analitycznych i narzędzi do danych w celu identyfikacji wzorców, relacji lub uzyskania systemów wykonujących przydatne zadania, takie jak klasyfikacja, przewidywanie, szacowanie lub grupowanie powinowactwa.
Ekstrakcja informacji: Automatyczne wyodrębnianie ustrukturyzowanej wiedzy z nieustrukturyzowanych dokumentów. Tekst zaszumiony: Tekst z jakąkolwiek różnicą w formie powierzchniowej od zamierzonego, poprawnego lub oryginalnego tekstu.
Optyczne rozpoznawanie znaków: Tłumaczenie obrazów tekstu pisanego odręcznie lub maszynowo (zwykle przechwytywanego przez skaner) na tekst edytowalny maszynowo.
Indukcja reguł: Proces uczenia się, z przypadków lub instancji, relacji reguł if-then, które składają się z poprzednika (część if, definiująca warunki wstępne lub zakres reguły) i następnika (część then, stwierdzająca klasyfikację, przewidywanie lub inne wyrażenie własności, która zachodzi dla przypadków zdefiniowanych w poprzedniku). Analiza tekstu: Proces wydobywania przydatnej i ustrukturyzowanej wiedzy z nieustrukturyzowanych dokumentów w celu znalezienia przydatnych skojarzeń i spostrzeżeń.
Klasyfikacja tekstu (lub kategoryzacja tekstu): Zadanie polega na uczeniu się modeli dla danego zestawu klas i stosowaniu tych modeli do nowych, niewidzianych dokumentów w celu przypisania do klasy.
Automatyczne rozpoznawanie mowy: Rozpoznawanie maszynowe i konwersja wypowiedzianych słów na tekst.
Eksploracja danych: Zastosowanie metod analitycznych i narzędzi do danych w celu identyfikacji wzorców, relacji lub uzyskania systemów wykonujących użyteczne zadania, takie jak klasyfikacja, przewidywanie, szacowanie lub grupowanie powinowactwa.
Ekstrakcja informacji: Automatyczne wyodrębnianie ustrukturyzowanej wiedzy z nieustrukturyzowanych dokumentów.
Ekstrakcja wiedzy: Wyjaśnienie wewnętrznej wiedzy systemu lub zestawu danych w sposób, który jest łatwy do zinterpretowania przez użytkownika.
Tekst zaszumiony: Tekst z jakąkolwiek różnicą w formie powierzchniowej od zamierzonego, poprawnego lub oryginalnego tekstu.
Optyczne rozpoznawanie znaków: Tłumaczenie obrazów tekstu pisanego ręcznie lub maszynowo (zwykle przechwytywanego przez skaner) na tekst edytowalny maszynowo.
Indukcja reguł: Proces uczenia się, z przypadków lub instancji, relacji reguł if-then, które składają się z poprzednika (część if, definiująca warunki wstępne lub zakres reguły) i następnika (część then, stwierdzająca klasyfikację, przewidywanie lub inne wyrażenie własności, która obowiązuje dla przypadków zdefiniowanych w poprzedniku).
Analiza tekstu: Proces wydobywania przydatnej i ustrukturyzowanej wiedzy z nieustrukturyzowanych dokumentów w celu znalezienia przydatnych skojarzeń i spostrzeżeń.
Angiografia: Obraz naczyń krwionośnych uzyskany dowolną możliwą procedurą.
Tętnica: Każde z naczyń, które transportują krew z serca do innych części ciała.
Tomografia komputerowa: Eksploracja promieni rentgenowskich, która tworzy szczegółowe obrazy przekrojów osiowych ciała. Tomografia komputerowa uzyskuje wiele obrazów poprzez obracanie się wokół ciała. Komputer łączy wszystkie te obrazy w ostateczny obraz, który przedstawia przekrój ciała jak plaster.
System ekspercki: Komputer lub program komputerowy, który może dawać odpowiedzi podobne do tych od eksperta.
Segmentacja: W wizji komputerowej segmentacja odnosi się do procesu podziału obrazu cyfrowego na wiele regionów. Celem segmentacji jest uproszczenie i/lub zmiana reprezentacji obrazu na coś, co jest bardziej znaczące i łatwiejsze do analizy. Segmentacja obrazu jest zwykle stosowana do lokalizowania obiektów i granic (struktur) na obrazach, w tym przypadku drzewa wieńcowego w ramach cyfrowej angiografii.
Zwężenie: Zwężenie to nieprawidłowe zwężenie w naczyniu krwionośnym lub innym narządzie lub strukturze rurowej. Tętnica wieńcowa, która jest zwężona lub zwężona, nazywana jest zwężoną. Nagromadzenie tłuszczu, cholesterolu i innych substancji z czasem może zatkać tętnicę. Wiele zawałów serca jest spowodowanych całkowitym zablokowaniem naczynia w sercu, zwanego tętnicą wieńcową.
Thresholding: Technika przetwarzania obrazów cyfrowych polegająca na stosowaniu określonej właściwości lub operacji do pikseli, których wartość intensywności przekracza określony próg.
Kompresja: Naprężenie generowane przez ściskanie lub ściskanie.
Konsystencja: Względna ruchliwość lub zdolność świeżo wymieszanego betonu lub zaprawy do płynięcia; typowym pomiarem betonu jest osiadanie, równe osiadaniu mierzonemu z dokładnością do 1/4 cala (6 mm) uformowanej próbki bezpośrednio po usunięciu stożka osiadania.
Ciągliwość: Ta właściwość materiału, dzięki której może on ulegać dużym trwałym odkształceniom bez pęknięcia.
Szalunek: Cały system podparcia świeżo położonego betonu, w tym forma lub poszycie, które stykają się z betonem, a także elementy nośne, osprzęt i niezbędne wzmocnienia; czasami nazywane szalunkiem w Wielkiej Brytanii.
Rozpiętość ścinania: Odległość między reakcją a najbliższym punktem obciążenia
Bezpieczeństwo konstrukcyjne: Reakcja konstrukcyjna silniejsza niż siły wewnętrzne wytwarzane przez obciążenie zewnętrzne.
Rozciąganie: Naprężenie wytwarzane przez rozciąganie.
Sztuczne sieci neuronowe: Połączony zestaw wielu prostych jednostek przetwarzających, powszechnie nazywanych neuronami, które wykorzystują model matematyczny, który reprezentuje relację wejścia/wyjścia
Algorytm propagacji wstecznej: Technika uczenia nadzorowanego stosowana przez sieci neuronowe, która iteracyjnie modyfikuje wagi połączeń sieci, tak aby błąd podawany przez sieć po porównaniu wyników z wynikami pożądanymi się zmniejszał.
Obliczenia ewolucyjne: Zestaw technik sztucznej inteligencji stosowanych w problemach optymalizacji, które są inspirowane mechanizmami biologicznymi, takimi jak naturalna ewolucja.
Programowanie genetyczne: Technika uczenia maszynowego wykorzystująca algorytm ewolucyjny w celu optymalizacji populacji programów komputerowych zgodnie z funkcją sprawności, która określa zdolność programu do wykonywania danego zadania.
Genotyp: Reprezentacja osobnika na całej kolekcji genów, do której stosuje się operatory krzyżowania i mutacji.
Fenotyp: Wyraz właściwości kodowanych przez genotyp osobnika. Populacja: Grupa osobników wykazujących takie same lub podobne struktury genomu, co pozwala na zastosowanie operatorów genetycznych.
Przestrzeń wyszukiwania: Zbiór wszystkich możliwych sytuacji, w których może znajdować się problem, który chcemy rozwiązać.
Sztuczne sieci neuronowe: Sieć wielu prostych procesorów ("jednostek" lub "neuronów"), która imituje biologiczną sieć neuronową. Jednostki są połączone jednokierunkowymi kanałami komunikacyjnymi, które przenoszą dane numeryczne. Sieci neuronowe można trenować w celu znajdowania nieliniowych relacji w danych i są wykorzystywane w takich zastosowaniach jak robotyka, rozpoznawanie mowy, przetwarzanie sygnałów lub diagnostyka medyczna.
Algorytm propagacji wstecznej: Algorytm uczenia się ANN, oparty na minimalizacji błędu uzyskanego z porównania między wyjściami, które sieć daje po zastosowaniu zestawu wejść sieciowych, a wyjściami, które powinna dać (pożądane wyjścia).
Klasyfikacja: Wpływ zjawiska na wstępnie zdefiniowaną klasę lub kategorię poprzez badanie jego charakterystycznych cech. W naszej pracy polega to na określeniu charakteru wykrytych defektów powierzchni urządzeń optycznych (na przykład "kurz" lub "inny rodzaj defektów").
Redukcja wymiarowości danych: Redukcja wymiarowości danych to przekształcenie danych wielowymiarowych w sensowną reprezentację zredukowanej wymiarowości. Celem jest znalezienie ważnych relacji między parametrami i odtworzenie tych relacji w przestrzeni o niższej wymiarowości. W idealnym przypadku uzyskana reprezentacja ma wymiarowość odpowiadającą wymiarowości wewnętrznej danych. Redukcja wymiarowości jest ważna w wielu dziedzinach, ponieważ ułatwia klasyfikację, wizualizację i kompresję danych o wysokiej wymiarowości. W naszej pracy jest ona wykonywana przy użyciu analizy odległości krzywoliniowej.
Wymiar wewnętrzny danych: gdy dane są opisywane wektorami (zbiorami wartości charakterystycznych), wymiar wewnętrzny danych jest efektywną liczbą stopni swobody zestawu wektorów. Zasadniczo wymiar ten jest mniejszy niż wymiar danych surowych, ponieważ mogą istnieć liniowe i/lub nieliniowe relacje między różnymi składnikami wektorów.
Wymiar danych surowych: gdy dane są opisywane wektorami (zbiorami wartości charakterystycznych), wymiar danych surowych jest po prostu liczbą składników tych wektorów.
Wykrywanie: identyfikacja zjawiska między innymi na podstawie szeregu cech charakterystycznych lub "symptomów". W naszej pracy polega to na identyfikowaniu nieregularności powierzchni na urządzeniach optycznych.
MLP (Multi Layer Perceptron): Ta szeroko stosowana sztuczna sieć neuronowa wykorzystuje perceptron jako prosty procesor. Model perceptronu, zaproponowany przez Rosenblatta, wygląda następująco:
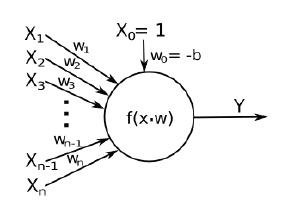
Na tym schemacie X oznacza wejścia, a Y wyjście neuronu. Każde wejście jest mnożone przez wagę w, próg b jest odejmowany od wyniku, a na koniec Y jest przetwarzane przez zastosowanie funkcji aktywacji f. Wagi połączenia są dostosowywane podczas fazy uczenia się przy użyciu algorytmu propagacji wstecznej.
Automatyczne systemy oceny: Aplikacje skupiające się na ocenie mocnych i słabych stron uczniów w różnych działaniach edukacyjnych za pomocą testów oceniających.
Wspomagane komputerowo uczenie się współpracy (CSCL): Temat badawczy dotyczący wspierania metodologii uczenia się współpracy za pomocą komputerów i narzędzi współpracy.
Nauka oparta na grach: Nowy typ nauki, który łączy treści edukacyjne i gry komputerowe w celu poprawy satysfakcji i wyników uczniów podczas zdobywania nowej wiedzy i umiejętności.
Inteligentne systemy nauczania: Program komputerowy, który zapewnia uczniom spersonalizowane/adaptacyjne instrukcje bez ingerencji ludzi.
Ontologie: Zestaw pojęć w obrębie domeny, które przechwytują i reprezentują wiedzę konsensualną w sposób ogólny i mogą być ponownie wykorzystywane i udostępniane w aplikacjach oprogramowania.
Agenci oprogramowania: Jednostki oprogramowania, takie jak programy oprogramowania lub roboty, charakteryzujące się autonomią, współpracą i zdolnościami uczenia się.
Modele ucznia: Reprezentacja zachowania ucznia i stopnia kompetencji pod względem istniejącej wiedzy podstawowej na temat domeny.
Uszkodzenie pancerza: Wydobycie kamieni lub elementów betonowych z warstwy pancerza przez działanie fal.
Warstwa pancerza: Zewnętrzna warstwa falochronu z gruzu, składająca się z ciężkich kamieni lub bloków betonowych.
Sztuczne sieci neuronowe: Połączony zestaw wielu prostych jednostek przetwarzających, powszechnie nazywanych neuronami, które wykorzystują model matematyczny reprezentujący relację wejścia/wyjścia.
Algorytm propagacji wstecznej: Technika uczenia nadzorowanego stosowana przez sieci neuronowe, która iteracyjnie modyfikuje wagi połączeń sieci, tak aby błąd podawany przez sieć po porównaniu wyjść z pożądanym zmniejszał się.
Falochron: Konstrukcja przybrzeżna zbudowana w celu osłonięcia obszaru przed falami, zwykle do załadunku lub rozładunku statków.
Odbicie: Proces, w którym energia nadchodzących fal jest zwracana w kierunku morza.
Znaczna wysokość fali: W analizie zapisu fal, średnia wysokość najwyższej jednej trzeciej wybranej liczby fal.
Adaptacja: Adaptacja to proces modyfikacji oparty na danych wejściowych lub obserwacjach. System informacyjny powinien dostosowywać się do konkretnych potrzeb poszczególnych użytkowników w celu uzyskania zoptymalizowanych wyników.
Indeksowanie: Indeksowanie oznacza przypisanie terminów (słów), które reprezentują dokument w indeksie. Indeksowanie może być przeprowadzane ręcznie lub automatycznie. Automatyczne indeksowanie wymaga wyeliminowania słów pomijanych i stemmingu.
Pobieranie informacji: Pobieranie informacji dotyczy reprezentacji i wiedzy, a następnie wyszukiwania odpowiednich informacji w tych źródłach wiedzy. Pobieranie informacji zapewnia technologię stojącą za wyszukiwarkami.
Analiza linków: Linki między stronami w sieci stanowią duże źródło wiedzy, które jest wykorzystywane przez algorytmy analizy linków do wielu celów. Wiele algorytmów podobnych do PageRank określa wynik jakości lub autorytetu na podstawie liczby przychodzących linków strony. Ponadto analiza linków jest stosowana w celu identyfikacji tematycznych stron, społeczności internetowych i innych struktur społecznych.
Systemy rekomendacji: Działania lub treści są sugerowane użytkownikowi na podstawie wcześniejszych doświadczeń zebranych od innych użytkowników. Bardzo często dokumenty są rekomendowane na podstawie profili podobieństwa między użytkownikami.
Rozszerzenie terminu: Terminy nieobecne w oryginalnym zapytaniu do systemu wyszukiwania informacji wprowadzonym przez użytkownika są dodawane automatycznie. Rozszerzone zapytanie jest następnie ponownie wysyłane do systemu.
Ważenie: Ważenie określa ważność terminu dla dokumentu. Wagi są obliczane przy użyciu wielu różnych wzorów, które uwzględniają częstotliwość występowania każdego terminu w dokumencie i w zbiorze, a także długość dokumentu i średnią lub maksymalną długość dowolnego dokumentu w zbiorze.
Diagnostyka wspomagana komputerowo: Obszar badawczy obejmujący rozwój technik obliczeniowych i procedur wspomagających pracowników służby zdrowia w podejmowaniu decyzji dotyczących diagnostyki medycznej.
Redukcja wymiarowości: Znajdowanie zredukowanego zestawu danych, z możliwością mapowania większego zestawu.
Ekstrakcja cech: Znajdowanie reprezentatywnych cech określonego problemu z próbek o różnych cechach.
Obrazy medyczne: Obrazy generowane w specjalistycznym sprzęcie, wykorzystywane w celu wspomagania diagnostyki medycznej. Np.: obrazy rentgenowskie, tomografia komputerowa, obrazy rezonansu magnetycznego.
Rozpoznawanie wzorców: Obszar badawczy obejmujący rozwój metod i zautomatyzowanych technik identyfikacji i klasyfikacji próbek w określonych grupach, zgodnie z reprezentatywnymi cechami.
Diagnostyka radiologiczna: Diagnostyka medyczna oparta na analizie i interpretacji wzorców obserwowanych na obrazach medycznych.
Samouporządkowujące się mapy: Kategoria algorytmów opartych na sztucznych sieciach neuronowych, które wyszukują, za pomocą samouporządkowania, w celu utworzenia mapy cech reprezentujących zaangażowane próbki w określonym problemie.
Chiński pokój: W eksperymencie myślowym Searle′a, prosi nas, abyśmy wyobrazili sobie mężczyznę siedzącego w pokoju z wieloma księgami zasad. Do pokoju wprowadzono zestaw symboli. Mężczyzna przetwarza symbole zgodnie z księgami zasad i przekazuje nowy zestaw symboli poza pokój. Symbole umieszczone w pokoju odpowiadają chińskiemu pytaniu, a symbole, które przekazuje, są odpowiedzią na pytanie w języku chińskim. Jednak mężczyzna przestrzegający zasad nie zna chińskiego. Przykład sugeruje, że program komputerowy mógłby podobnie przestrzegać zasad, aby odpowiedzieć na pytanie bez żadnego zrozumienia.
Klasyczne przetwarzanie symboli: Klasyczny pogląd na poznanie był taki, że było ono analogiczne do symbolicznych obliczeń w komputerach cyfrowych. Informacje są reprezentowane jako ciągi symboli, a przetwarzanie poznawcze obejmuje manipulację tymi ciągami za pomocą zestawu reguł. Zgodnie z tym poglądem szczegóły dotyczące sposobu implementacji takich obliczeń nie są uważane za ważne.
Koneksjonizm: Koneksjonizm to termin używany do opisania zastosowania sztucznych sieci neuronowych w badaniu umysłu. W opisach koneksjonistycznych wiedza jest reprezentowana przez siłę połączeń między zestawem sztucznych neuronów.
Koneksjonizm eliminacyjny: Koneksjonista eliminacyjny stara się przedstawić opis poznania, który unika symboli i działa na poziomie subsymbolicznym. Na przykład koncepcja "psa" mogłaby zostać ujęta w rozproszonej reprezentacji jako szereg cech wejściowych (np. czworonożny, futrzasty, szczeka itp.), a następnie istniałaby w sieci w formie ważonych połączeń między jego jednostkami przypominającymi neurony.
Uogólnienie: Sztuczne sieci neuronowe, po wyszkoleniu, są w stanie uogólniać poza elementy, na których zostały wyszkolone, i generować podobne dane wyjściowe w odpowiedzi na dane wejściowe, które są podobne do tych napotkanych podczas szkolenia.
Koneksjonizm implementacyjny: W tej mniej ekstremalnej wersji koneksjonizmu celem jest znalezienie sposobu na wdrożenie klasycznego przetwarzania symboli przy użyciu sztucznych sieci - i znalezienie sposobu na uwzględnienie przetwarzania symboli na poziomie neuronów.
Decyzja leksykalna: Zadania decyzji leksykalnej to miara opracowana w celu zbadania procesów związanych z rozpoznawaniem słów. Prezentowane jest słowo lub pseudosłowo (bezsensowny ciąg liter zgodny z zasadami pisowni), a czytelnik jest proszony o naciśnięcie przycisku, aby wskazać, czy wyświetlane jest słowo, czy nie. Czas potrzebny na podjęcie decyzji jest rejestrowany w milisekundach. Miara może dostarczyć wskazówek dotyczących różnych aspektów przetwarzania tekstu - na przykład, jak znajome jest słowo czytelnikowi.
Sztuczna sieć neuronowa: Sieć wielu prostych procesorów ("jednostek" lub "neuronów"), która imituje biologiczną sieć neuronową. Jednostki są połączone jednokierunkowymi kanałami komunikacyjnymi, które przenoszą dane liczbowe. Sieci neuronowe można trenować, aby znajdowały nieliniowe relacje w danych i są wykorzystywane w takich zastosowaniach jak robotyka, rozpoznawanie mowy, przetwarzanie sygnałów lub diagnostyka medyczna.
Astrocyty: Astrocyty są podtypem komórek glejowych w mózgu. Pełnią wiele funkcji, w tym tworzenie bariery krew-mózg, dostarczanie składników odżywczych do tkanki nerwowej i odgrywają główną rolę w procesie naprawy i bliznowacenia w mózgu. Modulują transmisję synaptyczną, a ostatnio odkryto ich kluczową rolę w przetwarzaniu informacji.
Algorytm propagacji wstecznej: Technika uczenia nadzorowanego stosowana do trenowania sieci neuronowych, oparta na minimalizacji błędu uzyskanego z porównania wyników, które sieć daje po zastosowaniu zestawu danych wejściowych sieci, z wynikami, które powinna dać (pożądane wyniki).
Obliczenia ewolucyjne: Podejście do rozwiązania kierowane przez ewolucję biologiczną, która zaczyna się od potencjalnych modeli rozwiązań, a następnie iteracyjnie stosuje algorytmy w celu znalezienia najlepiej dostosowanych modeli z zestawu, które mają służyć jako dane wejściowe do następnej iteracji, co ostatecznie prowadzi do modelu najlepiej reprezentującego dane.
Algorytmy genetyczne: Algorytmy genetyczne (GA) to adaptacyjne algorytmy heurystyczne oparte na ewolucyjnych ideach doboru naturalnego i genetyki. Podstawowa koncepcja GA została zaprojektowana w celu symulacji procesów w naturalnym systemie niezbędnych do ewolucji, w szczególności tych, które podążają za zasadami po raz pierwszy określonymi przez Karola Darwina dotyczącymi przetrwania najsilniejszych. Jako takie stanowią one inteligentne wykorzystanie losowego wyszukiwania w określonej przestrzeni wyszukiwania w celu rozwiązania problemu.
System glejowy: Powszechnie nazywane gliami (po grecku "klej"), są komórkami nieneuronalnymi, które zapewniają wsparcie i odżywianie, utrzymują homeostazę, tworzą mielinę i uczestniczą w transmisji sygnałów w układzie nerwowym. Szacuje się, że w mózgu człowieka liczba komórek glejowych przewyższa liczbę neuronów w stosunku 10 do 1.
Trening hybrydowy: :metoda zdobywania wiedzy, która łączy nadzorowany i nienadzorowany trening systemów łącznikowych.
Synapsa: Specjalistyczne połączenia, przez które komórki układu nerwowego wysyłają sygnały do siebie nawzajem i do komórek nieneuronalnych, takich jak te w mięśniach lub gruczołach.
Reguła asocjacyjna: Implikacja postaci X ? Y w transakcyjnej bazie danych z parametrami wsparcia (s) i pewności (c). X i Y to zbiór elementów, s to ułamek transakcji zawierających X?Y, a c% transakcji zawierających X zawiera również Y.
Klasyfikacja: Technika eksploracji danych, która konstruuje model (klasyfikator) z danych historycznych (danych szkoleniowych) i używa go do przewidywania kategorii niewidzianych krotek.
Klastrowanie: Technika eksploracji danych w celu podziału obiektów danych na zbiór grup w taki sposób, aby maksymalizować podobieństwo wewnątrzgrupowe, a minimalizować podobieństwo międzygrupowe.
Eksploracja danych: Ekstrakcja interesujących, nietrywialnych, niejawnych, wcześniej nieznanych i potencjalnie przydatnych informacji lub wzorców z danych w dużych bazach danych.
Strumień danych: Ciągły przepływ danych ze źródła danych, np. czujnika, tickera giełdowego, urządzenia monitorującego itp. Strumień danych charakteryzuje się nieograniczonym rozmiarem. Opisowa technika eksploracji: technika eksploracji danych, która indukuje model opisujący cechy danych. Techniki te są zazwyczaj nienadzorowane i całkowicie oparte na danych.
Predykcyjna technika eksploracji: technika eksploracji danych, która indukuje model z danych historycznych w sposób nadzorowany i wykorzystuje model do przewidywania pewnych cech nowych danych.
Atak siłowy: Wyczerpująca technika kryptoanalityczna, która przeszukuje całą przestrzeń kluczy w celu znalezienia poprawnego klucza.
Kryptoanaliza: Jest to proces próby odszyfrowania danego tekstu zaszyfrowanego i/lub znalezienia klucza bez znajomości klucza lub z jego częściową znajomością. Jest to również obszar badawczy badający techniki kryptoanalizy. Przestrzeń kluczy: Zbiór wszystkich możliwych kluczy dla danego szyfrogramu. Przestrzeń kluczy może być ograniczona do podprzestrzeni całego K przez pewną wcześniejszą wiedzę.
Tekst jawny: Niezaszyfrowany tekst, ciąg liter z alfabetu P danego kryptosystemu.
Atak relaksacyjny: Technika kryptoanalityczna, która przeszukuje przestrzeń kluczy poprzez przyrostowe aktualizacje kluczy kandydujących. Zwykle stosuje wiedzę z poprzednich próbnych deszyfrowania, aby zmienić niektóre części klucza.
Sztuczna sieć neuronowa (ANN): Model matematyczny inspirowany biologicznymi sieciami neuronowymi. Jednostki te nazywane są neuronami połączonymi w różnych warstwach wejściowych, ukrytych i wyjściowych. W przypadku określonego bodźca (dane liczbowe w warstwie wejściowej) niektóre neurony są aktywowane zgodnie z funkcją aktywacji i generują numeryczne wyjście. W ten sposób ANN jest trenowana, przechowując nauczony model w macierzach wagowych neuronów. Wykazano, że tego rodzaju przetwarzanie jest odpowiednie do znajdowania nieliniowych relacji w danych, będąc bardziej elastycznym w niektórych zastosowaniach niż modele wyodrębnione za pomocą technik rozkładu liniowego.
Metoda elementów skończonych (MES): Jest to technika analizy numerycznej służąca do uzyskiwania rozwiązań równań różniczkowych, które opisują lub w przybliżeniu opisują szeroką gamę problemów. Podstawowe założenie MES głosi, że skomplikowaną domenę można podzielić na szereg mniejszych regionów (elementy skończone), w których równania różniczkowe są w przybliżeniu rozwiązywane. Poprzez złożenie zestawu równań dla każdego regionu określa się zachowanie w całej domenie problemu.
Badanie echa uderzeniowego: Nieniszcząca procedura oceny oparta na monitorowaniu ruchu powierzchni wynikającego z krótkotrwałego uderzenia mechanicznego. Na podstawie analiz drgań mierzonych przez czujniki można uzyskać diagnozę stanu materiału.
Ocena nieniszcząca (NDE): Techniki NDE, badania ND lub inspekcji ND są stosowane w kontroli jakości materiałów. Techniki te nie niszczą obiektu testowego i wydobywają informacje o wewnętrznej strukturze obiektu. Aby wykryć różne wady, takie jak pęknięcia i korozja, dostępne są różne metody testowania, takie jak prześwietlenie rentgenowskie (gdzie pęknięcia pojawiają się na filmie), ultradźwięki (gdzie pęknięcia pojawiają się jako echo na ekranie) i echo uderzeniowe (pęknięcia są wykrywane przez zmiany w trybach rezonansowych obiektu).
Rozpoznawanie wzorców: Ważny obszar badań dotyczący automatycznego odkrywania lub identyfikowania figur, znaków, kształtów, form i wzorów bez aktywnego udziału człowieka w procesie decyzyjnym. Jest również związany z klasyfikowaniem danych w kategoriach. Klasyfikacja polega na uczeniu się modelu rozdzielania kategorii danych, do tego rodzaju uczenia maszynowego można podejść, stosując techniki statystyczne (modele parametryczne lub nieparametryczne) lub heurystyczne. Jeśli w procesie uczenia podano pewne wcześniejsze informacje, nazywa się to nadzorowanym lub półnadzorowanym, w przeciwnym razie nazywa się to nienadzorowanym.
Analiza głównych składowych (PCA): Metoda osiągania redukcji wymiarowości. Reprezentuje zbiór danych N-wymiarowych za pomocą ich projekcji na zbiór r optymalnie zdefiniowanych osi (głównych składowych). Ponieważ osie te tworzą zestaw ortogonalny, PCA daje liniową transformację danych. Główne składowe reprezentują źródła wariancji w danych. Zatem najbardziej znaczące główne składowe pokazują te cechy danych, które najbardziej się zmieniają.
Widma sygnałów: Zbiór składowych częstotliwości rozłożonych z oryginalnego sygnału w dziedzinie czasu. Istnieje kilka technik mapowania funkcji w dziedzinie czasu na dziedzinę częstotliwości jako transformacje Fouriera i falkowe oraz jej odwrotne transformacje, które umożliwiają rekonstrukcję oryginalnego sygnału
Akcelerometr: Urządzenie mierzące przyspieszenie, które jest przekształcane na sygnał elektryczny przesyłany do sprzętu do akwizycji sygnału. W testach echa uderzeniowego zmierzone przyspieszenie odnosi się do przemieszczeń drgań spowodowanych wzbudzeniem krótkiego uderzenia.
Redukcja wymiarowości: Proces mający na celu zmniejszenie liczby zmiennych problemu. Wymiar problemu jest podany przez liczbę zmiennych (cech lub parametrów), które reprezentują dane. Po ekstrakcji cech sygnału (która zmniejsza oryginalną przestrzeń próbki sygnału), wymiarowość może zostać bardziej zredukowana za pomocą metod selekcji cech.
Szybka transformata Fouriera (FFT): Klasa algorytmów stosowanych w cyfrowym przetwarzaniu sygnałów do obliczania dyskretnej transformaty Fouriera (DFT) i jej odwrotności. Ma zdolność przenoszenia funkcji z dziedziny czasu do dziedziny częstotliwości. Uzyskane składowe częstotliwości są widmami sygnału.
Ekstrakcja cech (FE): Proces mapowania przestrzeni wielowymiarowej na przestrzeń o mniejszej liczbie wymiarów. W przetwarzaniu sygnałów, zamiast przetwarzania surowych sygnałów z tysiącami próbek, bardziej wydajne jest przetwarzanie cech wyodrębnionych z sygnałów, takich jak moc sygnału, częstotliwość główna i współczynnik tłumienia.
Wybór cech (FS): Technika, która wybiera podzbiór cech z danego zestawu cech, które reprezentują istotne właściwości danych. FS można również zdefiniować jako zadanie wyboru małego podzbioru cech, który jest wystarczający do dobrego przewidywania etykiet docelowych, co jest kluczowe dla efektywnego uczenia się. Istnieje kilka metod FS opartych na marginesach (np. relief, simba) lub teorii informacji (np. infogain). Nadzorowane metody FS wykorzystują wiedzę a priori na temat zmiennej klasyfikacji, aby wybrać zmienne silnie skorelowane ze znaną zmienną.
Pozostaw-Jedną-Poza: Metoda stosowana w klasyfikacji z następującymi krokami: i.) Oznacz przypadki bazy danych znanymi klasami. ii.) Wybierz przypadek bazy danych. iii.) Oszacuj klasę dla wybranego przypadku przez klasyfikator, używając pozostałych przypadków jako danych treningowych. iv.) Powtarzaj kroki ii i iii do końca przypadków. v.) Oblicz średni procent sukcesu dla wyników klasyfikacji.
Kondycjoner sygnału (SC): Urządzenie, które konwertuje jeden typ sygnału elektronicznego na inny typ sygnału. Jego głównym zastosowaniem jest konwersja sygnału, który może być trudny do odczytania przez konwencjonalne urządzenia pomiarowe, na format łatwiejszy do odczytania. Typowe funkcje SC to wzmocnienie, izolacja elektryczna i liniowość.
Sztuczne sieci neuronowe: Zestaw podstawowych jednostek przetwarzania, które komunikują się ze sobą za pomocą ważonych połączeń. Jednostki te dają początek równoległemu przetwarzaniu o szczególnych właściwościach, takich jak zdolność do adaptacji lub uczenia się, uogólniania, grupowania lub organizowania danych, aproksymacji funkcji nieliniowych. Każda jednostka otrzymuje dane wejściowe od sąsiadów lub zewnętrznych źródeł i wykorzystuje je do obliczenia sygnału wyjściowego. Taki sygnał jest propagowany do innych jednostek lub jest składnikiem wyjścia sieci. Aby zmapować zestaw wejściowy na wyjściowy, sieć neuronowa jest trenowana przez uczenie wzorców, zmieniając ich wagi zgodnie z właściwymi zasadami uczenia się.
Automatyczna kontrola wizualna: Automatyczna forma kontroli jakości, zwykle realizowana przy użyciu jednej lub więcej kamer podłączonych do jednostki przetwarzania. Automatyczna kontrola wizualna została zastosowana do szerokiej gamy produktów. Jej celem jest zminimalizowanie skutków zmęczenia wzroku operatorów, którzy wykonują wykrywanie defektów w środowisku linii produkcyjnej.
Komórkowe sieci neuronowe: Szczególna architektura obwodów, która posiada pewne kluczowe cechy sztucznych sieci neuronowych. Jej jednostki przetwarzania są rozmieszczone w siatce M×N. Podstawową jednostką sieci neuronowych komórkowych jest komórka, która zawiera liniowe i nieliniowe elementy obwodów. Każda komórka jest połączona tylko z sąsiednimi komórkami. Sąsiednie komórki mogą oddziaływać bezpośrednio na siebie, podczas gdy komórki niepołączone ze sobą bezpośrednio mogą wpływać na siebie pośrednio z powodu efektów propagacji ciągłej dynamiki czasu.
Wykrywanie defektów: Ekstrakcja informacji o obecności wystąpienia przypadku, w którym wymaganie nie jest spełnione w procesach przemysłowych. Celem wykrywania defektów jest wyróżnienie produktów, które są nieprawidłowe lub mają braki w funkcjonalności lub specyfikacjach.
Dopasowywanie obrazów: Ustalenie zgodności między każdą parą widocznych homologicznych punktów obrazu na danej parze obrazów, mające na celu ocenę nowości.
Kontrola przemysłowa: Analiza mająca na celu zapobieganie dotarciu niezadowalających produktów przemysłowych do klienta, w szczególności w sytuacjach, w których wadliwe produkty mogą spowodować obrażenia lub nawet zagrozić życiu.
Obszar zainteresowania: Wybrany podzbiór próbek w zestawie danych zidentyfikowanym w określonym celu. W przetwarzaniu obrazu obszar zainteresowania jest identyfikowany przez granice obiektu. Kodowanie Regionu Zainteresowania można osiągnąć, opierając jego wybór na:(a) wartości, która może lub nie może znajdować się poza normalnym zakresem występujących wartości; (b) czysto oddzielonych informacjach graficznych, takich jak elementy rysunkowe; (c) oddzielonych informacjach semantycznych, takich jak zestaw współrzędnych przestrzennych i/lub czasowych.
Sieci neuronowe komórkowe: Szczególna architektura obwodów, która posiada pewne kluczowe cechy sztucznych sieci neuronowych. Jej jednostki przetwarzające są rozmieszczone w siatce M×N. Podstawową jednostką sieci neuronowych komórkowych jest komórka, która zawiera liniowe i nieliniowe elementy obwodów. Każda komórka jest połączona tylko z sąsiednimi komórkami. Sąsiednie komórki mogą oddziaływać bezpośrednio ze sobą, podczas gdy komórki niepołączone bezpośrednio ze sobą mogą wpływać na siebie pośrednio z powodu efektów propagacji ciągłej dynamiki czasu.
Pamięć rozmyta asocjacyjna: Rodzaj pamięci adresowalnej treścią, w której przywołanie następuje poprawnie, jeśli dane wejściowe mieszczą się w określonym oknie składającym się z górnej i dolnej granicy przechowywanych wzorców. Pamięć rozmyta asocjacyjna jest identyfikowana przez macierz wartości rozmytych. Umożliwia mapowanie wejściowego zbioru rozmytego na wyjściowy zbiór rozmyty.
Rozciąganie histogramu: Proces punktowy, który obejmuje zastosowanie odpowiedniej funkcji transformacji do każdego piksela obrazu cyfrowego w celu redystrybucji informacji histogramu w kierunku skrajności zakresu poziomów szarości. Celem tej operacji jest zwiększenie kontrastu obrazów cyfrowych.
Dopasowywanie obrazów: Ustalenie korespondencji między każdą parą widocznych homologicznych punktów obrazu na danej parze obrazów, mające na celu ocenę nowości.
Główne głosowanie: Operacja mająca na celu podjęcie decyzji, czy sąsiedztwo piksela w obrazie cyfrowym zawiera więcej czarnych lub białych pikseli, czy też ich liczba jest równa. Efekt ten jest realizowany w dwóch krokach. Pierwszy z nich powoduje powstanie obrazu, w którym znak najbardziej prawego piksela odpowiada dominującemu kolorowi. Podczas drugiego kroku poziomy szarości najbardziej prawych pikseli są wprowadzane do wartości czarnych lub białych, w zależności od dominującego koloru, lub pozostają niezmienione w przeciwnym razie.
System czasu rzeczywistego: System, który musi spełniać wyraźne ograniczenia czasu reakcji, aby uniknąć awarii. Równoważnie, system czasu rzeczywistego to taki, którego logiczna poprawność opiera się zarówno na poprawności wyników, jak i ich terminowości. Ograniczenia terminowości lub terminy są na ogół odzwierciedleniem podstawowego kontrolowanego procesu fizycznego.
Region zainteresowania: Wybrany podzbiór próbek w zestawie danych zidentyfikowany dla określonego celu. W przetwarzaniu obrazu, region zainteresowania jest identyfikowany przez granice obiektu. Kodowanie regionu zainteresowania można osiągnąć, opierając jego wybór na: (a) wartości, która może lub nie może znajdować się poza normalnym zakresem występujących wartości; (b) czysto oddzielonych informacjach graficznych, takich jak elementy rysunkowe; (c) oddzielonych informacjach semantycznych, takich jak zestaw współrzędnych przestrzennych i/lub czasowych.
Reguła asocjacji: Reguła asocjacji jest implikacją postaci X →Y, gdzie X ⊂ I, Y ⊂ I i X ∩Y = ∅, I oznacza zbiór elementów.
Eksploracja danych: Ekstrakcja interesujących, nietrywialnych, niejawnych, wcześniej nieznanych i potencjalnie przydatnych informacji lub wzorców z danych w dużych bazach danych.
Koncepcja formalna: Kontekst formalny K = (G,M,I) składa się z dwóch zbiorów G (obiekty) i M (atrybuty) oraz relacji I między G i M. Dla zbioru A ⊆ G obiektów A′={meM | gIm dla wszystkich geA} (zbiór wszystkich atrybutów wspólnych dla obiektów w A). Odpowiednio, dla zbioru B atrybutów definiujemy B′ = {geG | gIm dla wszystkich meB} (zbiór obiektów wspólnych dla atrybutów w B). Formalną koncepcją kontekstu (G, M, I) jest para (A, B) z A?G, B?M, A'=B i B'=A A nazywane jest zakresem, a B jest intencją koncepcji (A, B).
Częsty zamknięty zestaw elementów: Zestaw elementów X jest zamkniętym zestawem elementów, jeśli nie istnieje zestaw elementów X′ taki, że:
i. X′ jest właściwym nadzbiór X,
ii. Każda transakcja zawierająca X zawiera również X′. Zamknięty zestaw elementów X jest częsty, jeśli jego wsparcie przekracza dany próg wsparcia.
Połączenie Galois: Niech D = (O, I, R) będzie kontekstem eksploracji danych, gdzie O i I są skończonymi zbiorami obiektów (transakcji) i elementów. R ⊆ O x I jest relacją binarną między obiektami i elementami. Dla O ⊆ O, i I ⊆ I, definiujemy jak pokazano w Załączniku C. f(O) kojarzy z O elementy wspólne dla wszystkich obiektów o ∈ O, a g(I) kojarzy z I obiekty powiązane ze wszystkimi elementami i ∈ I. Para zastosowań (f,g) jest połączeniem Galois pomiędzy zbiorem potęgowym O (tj. 2O) a zbiorem potęgowym I (tj. 2I). Operatory h = f o g w 2I i h′ = g o f w 2o są operatorami domknięcia Galois. Zbiór elementów C ⊆ I z D jest domkniętym zbiorem elementów wtedy i tylko wtedy, gdy h(C) = C.
Generator zbioru elementów: Generator p domkniętego zbioru elementów c jest jednym z najmniejszych zbiorów elementów, takim że h(p) = c.
Reguły asocjacji nieredundantnej : Niech Ri oznacza regułę X1i → X2i, gdzie X1,X2 ⊆ I. Reguła R1 jest bardziej ogólna niż reguła R2, pod warunkiem, że R2 można wygenerować, dodając dodatkowe elementy do poprzednika lub następnika R1. Reguły mające takie samo wsparcie i pewność jak reguły bardziej ogólne są regułami asocjacji redundantnej. Pozostałe reguły są regułami nieredundantnymi.
Atak siłowy: Wyczerpująca technika kryptoanalityczna, która przeszukuje całą przestrzeń kluczy w celu znalezienia poprawnego klucza.
Tekst kandydacki: Tekst uzyskany przez zastosowanie algorytmu deszyfrującego w tekście zaszyfrowanym przy użyciu pewnego klucza k ∈ K. Jeśli k jest poprawnym kluczem (lub kluczem równoważnym) K, to tekst kandydacki jest prawidłowym tekstem jawnym x, w przeciwnym razie jest tekstem zaszyfrowanym przez połączenie dk (eK(x)).
Szyfrogram: Zaszyfrowany tekst, ciąg liter alfabetu C danego kryptosystemu przy użyciu danego klucza K ∈ K.…
Klasyczny szyfr: Klasyczny system szyfru to pięciokrotność (P, C, K, E, D), gdzie P, C, definiują alfabet tekstu jawnego i szyfrogramu, K jest zbiorem możliwych kluczy, a dla każdego K ∈ K istnieje algorytm szyfrowania eK ∈ E i odpowiadający mu algorytm deszyfrowania dK ∈ D taki, że dK (eK(x)) = x dla każdego wejścia x ∈ P i K ∈ K….
Kryptoanaliza: Jest to proces próby odszyfrowania danego szyfrogramu i/lub znalezienia klucza bez znajomości klucza lub z jego częściową znajomością. Jest to również obszar badawczy badający techniki kryptoanalizy.
Przestrzeń kluczy: Zbiór wszystkich możliwych kluczy dla danego szyfrogramu. Przestrzeń kluczy może być ograniczona do podprzestrzeni całego K przez pewną wcześniejszą wiedzę. Tekst jawny: Niezaszyfrowany tekst, ciąg liter z alfabetu P danego kryptosystemu.
Filtr tekstów jawnych: Algorytm lub predykat używany do określania, które teksty nie są prawidłowymi tekstami jawnymi. Filtr idealnych tekstów jawnych nigdy nie zwraca odpowiedzi NIEPOPRAWNEJ dla poprawnego tekstu jawnego.
Funkcja punktacji: Funkcja punktacji jest używana do oceny przydatności tekstu kandydata do klucza k ∈ K. Idealna funkcja punktacji ma ekstremum globalne w poprawnym tekście jawnym, tj. gdy k = K.