
Sztuczna inteligencja i pomysły mechaniki statystycznej
WSTĘP
Odprawa ukazuje szeroki i głęboki stopień złożoności wymagany do uwzględnienia rzeczywistych czynników dyplomatycznych, informacyjnych, wojskowych i ekonomicznych (DIME) w celu propagowania/ewolucji idei w określonych populacjach. Otwarty umysł doszedłby do wniosku, że możliwe jest, że w przypadku wielu scenariuszy może być wymaganych wiele podejść od wielu decydentów. Jednakże w interesie wielu decydentów leży, aby w rzeczywistych obliczeniach w jak największym stopniu opierać się na tym samym modelu ogólnym. Wielu użytkowników musiałoby ufać, że zakodowany model będzie wierny przetwarzaniu danych wejściowych. Podobnie jak w przypadku scenariuszy DIME, wyrafinowany marketing konkurencyjny wymaga oceny reakcji populacji na nowe produkty. Wiele dużych instytucji finansowych prowadzi obecnie transakcje z prędkościami ledwo ograniczonymi prędkością światła. Umieszczają swoje serwery w pobliżu parkietów giełdowych, aby móc zamieniać notowania na zlecenia do realizacji w ciągu kilku milisekund. Oczywiście handel przy takich prędkościach wymaga zautomatyzowanych algorytmów do przetwarzania i podejmowania decyzji. Algorytmy te opierają się na informacjach "technicznych" pochodzących z informacji o cenie, wolumenie i notowaniach (Poziom II). Kolejną dużą przeszkodą w handlu automatycznym jest zwrot "podstawowe" informacje we wskaźnikach technicznych, np. w celu uwzględnienia nowych wiadomości politycznych i gospodarczych w takich algorytmach.
TŁO
Koncepcja "memów" jest przykładem podejścia do czynników DIME (Situngkir, 2004). Podejście memowe, wykorzystujące redukcjonistyczną filozofię ewolucji wśród genów, można rozsądnie skontrastować z podejściami podkreślającymi potrzebę uwzględnienia stosunkowo globalnych wpływów ewolucji. Na całym świecie prowadzonych jest wiele innych alternatywnych prac, o których należy przynajmniej pamiętać podczas opracowywania i testowania modeli ewolucji/propagowania idei w określonych populacjach: Badanie nad prostym algebraicznym modelem kształtowania opinii wykazało, że jedyne ostateczne opinie są ekstremalne. Badanie wpływu chaosu na kształtowanie się opinii, przeprowadzone przy użyciu prostego modelu algebraicznego, wykazało, że sprzeczne opinie mogą się utrzymywać i mieć kluczowe znaczenie w bliskich wyborach, aczkolwiek autorzy zwrócili uwagę na to, że większość rzeczywistych populacji prawdopodobnie nie popiera chaosu . Ograniczony przegląd prac w sieciach społecznościowych pokazuje, że istnieje mniej więcej tyle zjawisk do zbadania, ile dyscyplin jest gotowych zastosować swoje modele sieciowe.
Mechanika statystyczna interakcji kory nowej (SMNI)
Klasa algorytmów AI, która nie została jeszcze opracowana w tym kontekście, wykorzystuje informacje znane o prawdziwej korze nowej. Właściwe wydaje się oparcie podejścia do propagowania idei na jedynym, jak dotąd wykazanym systemie, który rozwija i pielęgnuje idee, tj. mózgu kory nowej. Proponowanym modelem oddolnym jest statystyczny mechaniczny model interakcji kory nowej, opracowany przez autora i pomyślnie przetestowany w opisie wskaźników pamięci krótkotrwałej (STM) i elektroencefalografii (EEG). Ideas by Statistical Mechanics (ISM) to ogólny program służący do modelowania ewolucji i propagowania idei/wzorców w populacjach podlegających interakcjom endogenicznym i egzogenicznym. ISM rozwija podzbiory aktywności makrokolumnnej wieloczynnikowych stochastycznych opisów zdefiniowanych populacji, z makrokolumnami zdefiniowanymi przez ich lokalne parametry w określonych regionach oraz ze sparametryzowanymi endogenicznymi powiązaniami międzyregionalnymi i egzogenicznymi zewnętrznymi. Parametry podzbiorów makrokolumn będą dopasowane do wzorców reprezentujących idee. Określone zostaną parametry interakcji zewnętrznych i międzyregionalnych, które sprzyjają lub utrudniają szerzenie tych idei. Dopasowanie takich układów nieliniowych wymaga zastosowania technik próbkowania. Podejście autora wykorzystuje wskazówki zawarte w jego statystycznej mechanice interakcji kory nowej (SMNI), opracowane w serii około 30 artykułów opublikowanych w latach 1981-2001. W artykułach tych poruszono także długotrwałe problemy związane z informacją mierzoną za pomocą elektroencefalografii (EEG) wynikającą z oddolnych lokalnych interakcji skupisk tysięcy do dziesiątek tysięcy neuronów oddziałujących za pośrednictwem włókien o krótkim zasięgu) lub odgórnych wpływów interakcji globalnych (za pośrednictwem włókien mielinowych dalekiego zasięgu). SMNI dokonuje tego poprzez uwzględnienie interakcji lokalnych i globalnych jako niezbędnych do opracowania obwodów kory nowej.
Mechanika statystyczna rynków finansowych (SMFM)
Narzędzia zarządzania ryzykiem finansowym, opracowane do przetwarzania skorelowanych systemów wielowymiarowych o różnych rozkładach niegaussowskich, przy użyciu nowoczesnej analizy kopuł, umożliwiają obliczenie korelacji w dobrej wierze oraz niepewności sukcesu i porażki. Od 1984 roku autor opublikował około 20 artykułów rozwijających statystyczną mechanikę rynków finansowych (SMFM), wiele z nich dostępnych jest na stronie http://www.ingber.com. Są one istotne dla ISM, aby właściwie radzić sobie z dystrybucjami w świecie rzeczywistym, które pojawiają się w tak różnorodnych kontekstach. Kopuły Gaussa opracowywane są w ramach projektu Trading in Risk Dimensions (TRD). Możliwe są inne rozkłady kopuł, np. rozkłady t-Studenta. Te alternatywne rozkłady mogą być dość powolne, ponieważ odwrotne transformacje zazwyczaj nie są tak szybkie, jak w przypadku obecnego rozkładu. Kopule są wymieniane jako ważny element zarządzania ryzykiem, który nie jest jeszcze powszechnie stosowany przez praktyków zarządzania ryzykiem.
Narzędzia do pobierania próbek
Nie należy mylić podejść obliczeniowych opracowanych w celu przetwarzania różnych podejść do modelowania zjawisk z modelami tych zjawisk. Na przykład podejście memowe dobrze nadaje się do schematu obliczeniowego w duchu algorytmów genetycznych (GA). Funkcję kosztu/celu opisującą zjawisko można oczywiście przetworzyć dowolną inną techniką pobierania próbek, taką jak symulowane wyżarzanie (SA). Jedno porównanie wykazało wyższość SA nad GA w zakresie funkcji kosztu/celu używanych w bazie danych GA. W badaniach tych wykorzystano bardzo szybkie symulowane wyżarzanie (VFSR), stworzone przez autora na potrzeby wojskowych badań symulacyjnych, które przekształciło się w symulowane wyżarzanie adaptacyjne (ASA) . Jednakże z doświadczenia autora wynika, że sztuka i nauka próbkowania złożonych systemów wymaga od badacza wiedzy specjalistycznej w zakresie dostrojenia oraz dobrych kodów, a GA lub SA prawdopodobnie równie dobrze poradziłyby sobie z funkcjami kosztów w tym badaniu. Jeśli nie ma analitycznych lub stosunkowo standardowych funkcji matematycznych dla wymaganych przekształceń, wówczas przekształcenia te muszą zostać wykonane jawnie numerycznie w kodzie, takim jak TRD. W takim razie opcja ASA_PARALLEL OPTIONS już istniejąca w ASA (opracowana w ramach projektu National Science Foundation Parallelizing ASA and PATHINT Project (PAPP) z 1994 r.) byłaby bardzo użyteczna do przyspieszenia obliczeń w czasie rzeczywistym (Ingber, 1993). Poniżej omówiono tylko kilka tematów istotnych dla ISM. Więcej szczegółów znajduje się w poprzednim raporcie.
SMNI I SMFM ZASTOSOWANE W SZTUCZNEJ INTELIGENCJI
Kora nowa ewoluowała, aby wykorzystywać minikolumny neuronów oddziałujące poprzez interakcje o krótkim zasięgu w makrokolumnach i oddziałujące poprzez interakcje o dalekim zasięgu w obszarach makrokolumn. Ta wspólna architektura przetwarza wzorce informacji w obrębie i pomiędzy różnymi obszarami kory czuciowej, ruchowej, kory skojarzeniowej itp. Dlatego też założeniem tego podejścia jest to, że jest to dobry model do opisu i analizy ewolucji/propagacji idei wśród określonych populacji. Istotne dla tego badania jest to, że przestrzenno-czasowy, krótkotrwały, warunkowy szum multiplikatywny (nieliniowy w dryfach i dyfuzjach) wielowymiarowy rozkład prawdopodobieństwa Gaussa-Markowa jest opracowany zgodnie z funkcją/fizjologią kory nowej. Takie rozkłady prawdopodobieństwa stanowią podstawowy wkład w zastosowane tutaj podejście. Model SMNI był pierwszym fizycznym zastosowaniem nieliniowego rachunku wielowymiarowego opracowanego przez innych fizyków matematycznych pod koniec lat 70. XX wieku w celu zdefiniowania mechaniki statystycznej wielowymiarowych nieliniowych układów nierównowagowych
Testy SMNI na STM i EEG
SMNI opiera się na interakcjach synaptycznych, interakcjach minikolumnowych, makrokolumnowych i regionalnych w korze nowej. Od 1981 roku opracowano serię artykułów SMNI modelujących kolumny i obszary kory nowej, obejmujące mm do cm tkanki. Większość tych artykułów wyraźnie zajmowała się obliczaniem właściwości STM i EEG skóry głowy, aby przetestować podstawowe sformułowanie tego podejścia. Modelowanie SMNI lokalnych interakcji mezokolumnowych (zbieżność i rozbieżność między interakcjami minikolumnowymi i makrokolumnowymi) przetestowano na zjawiskach STM. Modelowanie SMNI interakcji makrokolumnowych między regionami przetestowano na zjawiskach EEG.
SMNI Opis STM
Badania SMNI szczegółowo wykazały, że maksymalna liczba atraktorów znajduje się w fizycznej przestrzeni wyzwalania zarówno pobudzających, jak i hamujących wyładowań minikolumnowych, zgodnie z eksperymentalnie obserwowanymi możliwościami słuchowego i wizualnego STM, gdy mechanizm "centrujący" jest wymuszane przez przesunięcie szumu tła w interakcjach synaptycznych, zgodnie z obserwacjami eksperymentalnymi w warunkach uwagi selektywnej. Obliczenia te zostały dodatkowo poparte wysokorozdzielczą ewolucją krótkotrwałego propagatora prawdopodobieństwa warunkowego przy użyciu PATHINT. SMNI poprawnie obliczyło stabilność i czas trwania STM, zasadę pierwszeństwa kontra regułę aktualności, losowy dostęp do wspomnień w ciągu dziesiątych części sekundy, jak zaobserwowano, oraz zaobserwowaną regułę pojemności 7±2 pamięci słuchowej i zaobserwowaną regułę pojemności 4±2 pamięci wzrokowej . SMNI oblicza również, w jaki sposób wzorce STM (np. z danego regionu lub nawet zagregowane z wielu regionów) mogą być kodowane poprzez dynamiczną modyfikację parametrów synaptycznych (w zakresach obserwowanych eksperymentalnie) we wzorce pamięci długotrwałej (LTM)
SMNI Opis EEG
Wykorzystując siłę tej formalnej struktury, zestawy danych EEG i potencjalnych danych wywołanych z oddzielnego badania NIH, zebrane w celu zbadania genetycznych predyspozycji do alkoholizmu, dopasowano do modelu SMNI na siatce regionalnych elektrod w celu wyodrębnienia "sygnatur" mózgu STM. Każde miejsce elektrody było reprezentowane przez rozkład SMNI niezależnych stochastycznych zmiennych wypalania w skali makrokolumnowej, połączonych ze sobą obwodami dalekiego zasięgu z opóźnieniami odpowiednimi dla komunikacji długich włókien w korze nowej. Do wykonania dopasowań Lagrangianów o największej wiarygodności zdefiniowanych przez całki po ścieżkach wielowymiarowych prawdopodobieństw warunkowych wykorzystano globalny algorytm optymalizacji ASA. W ten sposób uzyskano kanoniczne wskaźniki pędu (CMI) dla indywidualnych danych EEG. Wskaźniki CMI zapewniają lepsze rozpoznawanie sygnału niż surowe dane i zostały z korzyścią wykorzystane jako korelaty stanów behawioralnych. Do szkolenia wykorzystano dane pochodzące z próby, a dane spoza próby wykorzystano do przetestowania tych dopasowań. Architekturę ISM modeluje się przy użyciu skal podobnych do tych stosowanych w przypadku lokalnej łączności STM i globalnej łączności EEG.
Ogólne mezoskopowe sieci neuronowe
SMNI zastosowano do równoległych ogólnych mezoskopowych sieci neuronowych (MNN) , dodając moc obliczeniową do podobnego paradygmatu zaproponowanego do rozpoznawania celu. "Uczenie się" odbywa się poprzez prezentację MNN danych i parametryzację danych pod kątem wypaleń lub wypaleń wieloczynnikowych. "Wagi", czyli współczynniki funkcji zapłonów pojawiające się w dryfach i dyfuzjach, są dopasowane do napływających danych, biorąc pod uwagę łączny "efektywny" Lagranżian (w tym logarytm preczynnika w rozkładzie prawdopodobieństwa) jako dynamiczną funkcję kosztu. Ten program dopasowywania współczynników w Lagrangianie wykorzystuje metody ASA. "Przewidywanie" trwa zaleta matematycznie równoważnej reprezentacji algorytmu całki po ścieżce Lagrangianu, tj. zestawu sprzężonych równań szybkości Langevina. Zgrubne oszacowanie deterministyczne w celu "przewidywania" ewolucji można zastosować przy użyciu najbardziej prawdopodobnej ścieżki, ale PATHINT był użyty. PATHINT, nawet gdy jest zrównoleglony, zazwyczaj może być zbyt wolny, aby "przewidywać" ewolucję tych systemów. Jednak PATHTREE jest znacznie szybszy.
Architektura dla wybranego modelu ISM
Głównym celem jest dostarczenie modelu komputerowego zawierającego następujące cechy: (1) Zdefiniowana zostanie przestrzeń wielu zmiennych, aby pomieścić populacje. (2) Zdefiniowana zostanie funkcja kosztu po zmiennych populacji w (1), aby wyraźnie zdefiniować wzorzec które można zidentyfikować jako Ideę. Bardzo ważną kwestią w tym projekcie jest opracowanie funkcji kosztów, a nie tylko tego, jak je dopasować czy przetworzyć. (3) Podzbiory populacji zostaną wykorzystane w celu dopasowania parametrów - np. współczynników zmiennych, powiązań z wzorcami itp. - pomysł, korzystając z funkcji kosztu w (2). (4) Połączenie ludności w (3) zostanie zapewnione z resztą populacji. Zostaną przeprowadzone badania w celu ustalenia, jaka endogenna łączność jest wymagana, aby zatrzymać lub promować rozprzestrzenianie się Idei na inne regiony populacji. (5) Zostaną wprowadzone siły zewnętrzne, np. działające tylko na określone regiony populacji, aby określić, w jaki sposób te siły zewnętrzne mogą powstrzymać lub sprzyjać rozprzestrzenianiu się Idei. Zastosowanie modelu SMNI Podejście polega na opracowaniu podzbiorów idei/aktywności makrokolumnowej wielowymiarowych opisów stochastycznych określonych populacji (rozsądnych, ale małych próbek populacji, np. 100-1000), z makrokolumnami zdefiniowanymi przez ich lokalne parametry w określonych regionach ( większe próbki populacji) oraz ze sparametryzowanymi, dalekosiężnymi powiązaniami międzyregionalnymi i zewnętrznymi. Parametry danego podzbioru makrokolumn zostaną dopasowane przy użyciu ASA do wzorców reprezentujących pomysły, podobnie jak w przypadku uzyskiwania stałych długoterminowych wzorców (LTM). Określone zostaną parametry interakcji zewnętrznych i międzyregionalnych, które sprzyjają lub hamują rozprzestrzenianie się tych Idei, poprzez określenie stopnia dopasowania i nakładania się rozkładów prawdopodobieństwa w stosunku do zaszczepionych makrokolumn. Oznacza to, że mogą być reprezentowane te same pomysły/wzorce w innych niż zasiane makrokolumnach poprzez lokalne zbiegi makrokolumn i wyładowań dalekiego zasięgu, podobnie jak STM, lub za pomocą różnych ustalonych na stałe zestawów parametrów LTM, które mogą obsługiwać te same lokalne wystrzeliwania w innych regionach (możliwe w systemach nieliniowych). SMNI oblicza również, w jaki sposób STM może być dynamicznie kodowany w LTM (Ingber, 1983). Próbki małych populacji w regionach zostaną pobrane w celu ustalenia, czy propagowane Pomysły istnieją w swojej przestrzeni wzorców, w której istniały przed interakcjami z zasianą populacją. SMNI wyprowadza funkcje nieliniowe jako argumenty rozkładów prawdopodobieństwa, prowadząc do wielu STM, np. 7 ± 2 dla pojemności pamięci słuchowej. Przeprowadzone zostaną pewne badania nieliniowych form funkcjonalnych innych niż te wyprowadzone dla SMNI, np. mających możliwości dziesiątek lub setek wzorów dla ISM.
Zastosowanie analizy TRD
Podejście to obejmuje zastosowanie metod analizy ryzyka portfela do takich systemów statystycznych, korygując dwa rodzaje błędów popełnianych w wielowymiarowych analizach ryzyka: (E1) Chociaż rozkłady branych pod uwagę zmiennych nie są gaussowskie (lub nie są testowane, aby zobaczyć, jak blisko są Gaussa), stosowane są standardowe obliczenia statystyczne właściwe tylko dla rozkładów Gaussa. (E2) Albo ignorowane są korelacje pomiędzy zmiennymi, albo błędy popełnione w (E1) - błędne założenie, że zmienne są gaussowskie - są spotęgowane poprzez obliczenie korelacji tak, jakby wszystkie zmienne były gaussowskie. Należy rozumieć, że każdy algorytm próbkowania przetwarzający ogromną liczbę stanów może znaleźć wiele zastosowań do zapisania wielu optimów podczas próbkowania. Niektóre algorytmy mogą oznaczyć te stany jako "mutacje" stanów optymalnych. Ważne jest, aby móc je uwzględnić w ostatecznych decyzjach, np. o zastosowaniu dodatkowych mierników wydajności specyficznych dla aplikacji. Doświadczenie z portfelami zarządzającymi ryzykiem pokazuje, że nie najlepiej jest uwzględnić wszystkie kryteria, łącząc je wszystkie w jedną funkcję kosztu, lecz należy raczej kierować się rozsądną oceną w odniesieniu do wielu etapów przetwarzania wstępnego i przetwarzania końcowego podczas przeprowadzania takiego pobierania próbek, np. dodawania dodatkowych metryki wydajności.
PRZYSZŁE TRENDY
Biorąc pod uwagę motywacje finansowe i polityczne do łączenia informacji omówionych we wstępie, nieuniknione jest opracowanie wielu algorytmów sztucznej inteligencji, a wiele obecnych algorytmów sztucznej inteligencji zostanie udoskonalonych, aby rozwiązać te problemy.
WNIOSEK
Wydaje się właściwe oparcie podejścia do propagowania idei ogólnych na jedynym, jak dotąd wykazanym systemie, który rozwija i pielęgnuje idee, tj. mózgu kory nowej. Proponowanym modelem jest statystyczny mechaniczny model interakcji kory nowej, opracowany przez autora i pomyślnie przetestowany w opisie pamięci krótkotrwałej i wskaźników EEG, Ideas by Statistical Mechanics (ISM) . ISM rozwija podzbiory aktywności makrokolumnnej wieloczynnikowych stochastycznych opisów zdefiniowanych populacji, z makrokolumnami zdefiniowanymi przez ich lokalne parametry w określonych regionach oraz ze sparametryzowanymi endogenicznymi powiązaniami międzyregionalnymi i egzogenicznymi zewnętrznymi. Narzędzia zarządzania ryzykiem finansowym, opracowane do przetwarzania skorelowanych systemów wielowymiarowych o różnych rozkładach niegaussowskich przy użyciu nowoczesnej analizy kopuł, próbkowania ważności przy użyciu ASA, umożliwią obliczenie korelacji w dobrej wierze oraz niepewności sukcesu i porażki
Spacer AI od farmakokinetyki do marketingu
WSTĘP
Niniejsza praca ma na celu zapewnienie przeglądu praktycznych zastosowań metod sztucznej inteligencji (AI). Skupiamy się na wykorzystaniu metod uczenia maszynowego (ML) stosowanych raczej do rzeczywistych problemów niż problemów syntetycznych ze standardowym i kontrolowanym środowiskiem. W szczególności opiszemy następujące problemy w kolejnych sekcjach:
o Optymalizacja dawkowania erytropoetyny (EPO) u pacjentów z niedokrwistością przechodzących przewlekłą niewydolność nerek (CRF).
o Optymalizacja systemu rekomendacji dla użytkowników portalu internetowego dla obywateli.
o Optymalizacja kampanii marketingowej.
Wybór tych problemów wynika z ich trafności i heterogeniczności. Ta heterogeniczność pokazuje możliwości i wszechstronność metod ML w rozwiązywaniu rzeczywistych problemów w bardzo różnych dziedzinach wiedzy. W tej pracy zostaną omówione następujące metody:
o Sztuczne sieci neuronowe (ANN): Perceptron wielowarstwowy (MLP), sieć neuronowa o skończonej odpowiedzi impulsowej (FIR), sieć Elmana, mapy samoorganizujące (SOM) i adaptacyjna teoria rezonansu (ART).
o Inne algorytmy klastrowania: K-Means, algorytm maksymalizacji oczekiwań (EM), Fuzzy C-Means (FCM), algorytmy hierarchicznego klastrowania (HCA).
o Uogólniona autoregresyjna warunkowa heteroskedastyczność (GARCH).
o Regresja wektorów nośnych (SVR).
o Techniki filtrowania kolaboracyjnego.
o Metody uczenia się przez wzmacnianie (RL).
KONTEKST
Celem tej komunikacji jest podkreślenie możliwości metod ML w dostarczaniu praktycznych i skutecznych rozwiązań w trudnych zastosowaniach w świecie rzeczywistym. Aby praca była łatwa do odczytania, skupiamy się na każdej z trzech oddzielnych domen, a mianowicie farmakokinetyce (PK), systemach rekomendacji internetowych i marketingu
Farmakokinetyka
Systemy wspomagania podejmowania decyzji klinicznych wykorzystują metody sztucznej inteligencji (AI) od końca lat pięćdziesiątych. Niemniej jednak dopiero w latach dziewięćdziesiątych systemy wspomagania decyzji były rutynowo stosowane w praktyce klinicznej na znaczną skalę. W szczególności ANN były szeroko stosowane w zastosowaniach medycznych w ciągu ostatnich dwóch dekad. Jednym z pierwszych istotnych badań obejmujących ANN i monitorowanie leków terapeutycznych było. W tej pracy opracowano system ostrzegania o interakcjach leków oparty na ANN z komputerowym systemem wprowadzania danych medycznych w czasie rzeczywistym. Skupiając się na problemach bliższych rzeczywistym zastosowaniom, które zostaną opisane w następnej sekcji, istnieje również szereg niedawnych prac dotyczących wykorzystania ML do dostarczania leków w chorobie nerek. Na przykład porównanie niepożądanych reakcji na leki związane z nerkami pomiędzy rofekoksybem i celekoksybem, w oparciu o bazę danych bezpieczeństwa WHO/Uppsala Monitoring Centre. Nieproporcjonalność w związku pomiędzy konkretnym lekiem a niepożądanymi reakcjami na leki związanymi z nerkami została oceniona przy użyciu metody sieci neuronowej propagacji zaufania bayesowskiego. Badanie przewidywania dawkowania cyklosporyny u pacjentów po przeszczepie nerki przy użyciu sieci neuronowych i metod opartych na jądrze zostało przeprowadzone w Camps . Przeprowadzono analizę populacyjną farmakodynamiki u pacjentów z przewlekłą niewydolnością nerek przy użyciu sieci neuronowych. Takie modele pozwalają na dostosowanie schematu dawkowania. Wreszcie zaproponowano wykorzystanie sieci neuronowych do optymalizacji dawkowania EPO u pacjentów przechodzących niedokrwistość związaną z przewlekłą niewydolnością nerek.
Systemy rekomendacji internetowych
Systemy rekomendacji są szeroko stosowane w witrynach internetowych, w tym w Google. Głównym celem tych systemów jest rekomendowanie obiektów, którymi użytkownik może być zainteresowany. Zastosowano dwa główne podejścia: filtrowanie oparte na treści i filtrowanie grupowe , chociaż zaproponowano również inne rodzaje technik . Rekomendacje grupowe agregują oceny rekomendacji obiektów, znajdują podobieństwa użytkowników na podstawie ich ocen i na koniec dostarczają nowe rekomendacje na podstawie porównań między użytkownikami. Niektóre z najbardziej odpowiednich systemów wykorzystujących tę technikę to GroupLens/NetPerceptions i Recommender. Główną zaletą technik grupowych jest to, że są one niezależne od jakiejkolwiek czytelnej maszynowo reprezentacji obiektów i że dobrze sprawdzają się w przypadku złożonych obiektów, w których subiektywne osądy odpowiadają za znaczną część zmienności preferencji. Uczenie się oparte na treści jest stosowane, gdy przeszłe zachowanie użytkownika jest wiarygodnym wskaźnikiem jego przyszłego zachowania. Jest ono szczególnie odpowiednie w sytuacjach, w których użytkownicy mają tendencję do wykazywania idiosynkratycznych zachowań. Jednak takie podejście wymaga systemu zbierającego stosunkowo duże ilości danych od każdego użytkownika w celu umożliwienia sformułowania modelu statystycznego. Przykładami systemów tego typu są systemy rekomendacji tekstów, takie jak system filtrowania grup dyskusyjnych, NewsWeeder, który wykorzystuje słowa ze swoich tekstów jako funkcje.
Marketing
Najnowsze trendy marketingowe są bardziej skoncentrowane na utrzymaniu obecnych klientów i optymalizacji ich zachowań niż na pozyskiwaniu nowych. Z tego powodu marketing relacyjny koncentruje się na tym, co firma musi zrobić, aby osiągnąć ten cel. Relacje między firmą a jej klientami podążają za sekwencją systemu akcji-odpowiedzi, w którym klienci mogą modyfikować swoje zachowanie zgodnie z działaniami marketingowymi opracowanymi przez firmę. Opracowanie dobrej i zindywidualizowanej polityki nie jest łatwe, ponieważ należy wziąć pod uwagę wiele zmiennych. Aplikacje tego rodzaju można postrzegać jako problem łańcucha Markowa, w którym firma decyduje, jakie działanie podjąć, gdy znane są właściwości klienta w bieżącym stanie (czas t). Do rozwiązania tego zadania można wykorzystać uczenie się przez wzmacnianie (RL), ponieważ poprzednie aplikacje wykazały jego przydatność w tym obszarze. Zastosowano do analizy mailingu poprzez badanie, jak działanie w czasie t wpływa na działania w kolejnych czasach. Kilka algorytmów RL zostało przetestowanych pod kątem problemów mailingowych. RL zastosowano do optymalizacji marketingu wielokanałowego.
Systemy rekomendacji internetowych
Systemy rekomendacji są szeroko stosowane w witrynach internetowych, w tym w Google. Głównym celem tych systemów jest rekomendowanie obiektów, którymi użytkownik może być zainteresowany. Zastosowano dwa główne podejścia: filtrowanie oparte na treści i filtrowanie grupowe , chociaż zaproponowano również inne rodzaje technik . Rekomendacje grupowe agregują oceny rekomendacji obiektów, znajdują podobieństwa użytkowników na podstawie ich ocen i na koniec dostarczają nowe rekomendacje na podstawie porównań między użytkownikami. Niektóre z najbardziej odpowiednich systemów wykorzystujących tę technikę to GroupLens/NetPerceptions i Recommender. Główną zaletą technik grupowych jest to, że są one niezależne od jakiejkolwiek czytelnej maszynowo reprezentacji obiektów i że dobrze sprawdzają się w przypadku złożonych obiektów, w których subiektywne osądy odpowiadają za znaczną część zmienności preferencji. Uczenie się oparte na treści jest stosowane, gdy przeszłe zachowanie użytkownika jest wiarygodnym wskaźnikiem jego przyszłego zachowania. Jest ono szczególnie odpowiednie w sytuacjach, w których użytkownicy mają tendencję do wykazywania idiosynkratycznych zachowań. Jednak takie podejście wymaga systemu zbierającego stosunkowo duże ilości danych od każdego użytkownika w celu umożliwienia sformułowania modelu statystycznego. Przykładami systemów tego typu są systemy rekomendacji tekstów, takie jak system filtrowania grup dyskusyjnych, NewsWeeder, który wykorzystuje słowa ze swoich tekstów jako funkcje.
Marketing
Najnowsze trendy marketingowe są bardziej skoncentrowane na utrzymaniu obecnych klientów i optymalizacji ich zachowań niż na pozyskiwaniu nowych. Z tego powodu marketing relacyjny koncentruje się na tym, co firma musi zrobić, aby osiągnąć ten cel. Relacje między firmą a jej klientami podążają za sekwencją systemu akcji-odpowiedzi, w którym klienci mogą modyfikować swoje zachowanie zgodnie z działaniami marketingowymi opracowanymi przez firmę. Opracowanie dobrej i zindywidualizowanej polityki nie jest łatwe, ponieważ należy wziąć pod uwagę wiele zmiennych. Aplikacje tego rodzaju można postrzegać jako problem łańcucha Markowa, w którym firma decyduje, jakie działanie podjąć, gdy znane są właściwości klienta w bieżącym stanie (czas t). Do rozwiązania tego zadania można wykorzystać uczenie się przez wzmacnianie (RL), ponieważ poprzednie aplikacje wykazały jego przydatność w tym obszarze. RL zastosowano do analizy mailingu poprzez badanie, w jaki sposób działanie w czasie t wpływa na działania w kolejnych czasach. Kilka algorytmów RL zostało przetestowanych pod kątem problemów mailingowych. RL zostało użyte do optymalizacji marketingu wielokanałowego.
WKŁAD AI W APLIKACJE RZECZYWISTE
Poprzednia sekcja zawierała przegląd powiązanych prac. W tej sekcji skupimy się na pokazaniu doświadczenia autorów w używaniu AI do rozwiązywania rzeczywistych problemów. Aby pokazać wszechstronność metod AI, skupimy się na konkretnych zastosowaniach z trzech różnych dziedzin wiedzy, tych samych, które zostały omówione w poprzedniej sekcji.
Farmakokinetyka
Chociaż pracowaliśmy również nad innymi problemami farmakokinetycznymi, w tej pracy skupiamy się na być może najistotniejszym problemie, jakim jest optymalizacja dawek EPO u pacjentów w ramach programu hemodializy. Pacjenci cierpiący na CRF mają tendencję do cierpienia na towarzyszącą temu niedokrwistość. EPO jest leczeniem z wyboru w przypadku tego rodzaju niedokrwistości. Stosowanie tego leku znacznie zmniejszyło problemy sercowo-naczyniowe i konieczność wielokrotnych transfuzji. Jednak EPO jest drogie, co sprawia, że i tak kosztowny program CRF jest jeszcze bardziej kosztowny. Ponadto istnieją znaczne ryzyka związane z EPO, takie jak zakrzepy i zatory oraz problemy naczyniowe, jeśli poziom hemoglobiny (Hb) jest zbyt wysoki lub wzrasta zbyt szybko. W związku z tym optymalizacja dawkowania ma kluczowe znaczenie dla zapewnienia odpowiedniej farmakoterapii, a także rozsądnych kosztów leczenia. Modele populacyjne, szeroko stosowane przez badaczy z Farmakokinetyki, nie nadają się do rozwiązania tego problemu, ponieważ odpowiedź na leczenie EPO jest w dużym stopniu zależna od pacjenta. Te same dawki mogą mieć bardzo różne reakcje u różnych pacjentów, w szczególności u tak zwanych pacjentów opornych na EPO, którzy nie reagują na leczenie EPO, nawet po otrzymaniu dużych dawek. Dlatego lepiej jest skupić się na indywidualnym leczeniu. Nasze pierwsze podejście do tego problemu opierało się na przewidywaniu poziomu Hb przy określonej podanej dawce EPO. Chociaż ostatecznym celem jest indywidualizacja dawek EPO, nie przewidywaliśmy dawki EPO, ale poziom Hb. Powodem jest to, że predyktory EPO modelowałyby protokół lekarza, podczas gdy predyktory Hb modelują odpowiedź organizmu na leczenie, będąc tym samym bardziej "obiektywnym" podejściem. W szczególności zastosowano następujące modele: GARCH (Hamilton, 1994), MLP, sieć neuronowa FIR, rekurencyjna sieć neuronowa Elmana i SVR. Uzyskano dokładne modele predykcyjne, szczególnie przy użyciu ANN i SVR. Dynamiczne sieci neuronowe (tj. FIR i rekurencyjne) nie przewyższyły w szczególności statycznego MLP, prawdopodobnie ze względu na krótki czas trwania szeregu czasowego. Opracowano łatwą w użyciu aplikację programową, z której mogli korzystać lekarze, w której po wprowadzeniu danych pacjentów i określonej dawki EPO wyświetlano przewidywany poziom Hb na następny miesiąc. Chociaż modele predykcyjne były dokładne, zdaliśmy sobie sprawę, że to podejście do predykcji miało poważną wadę. Pomimo uzyskania dokładnych modeli, nie udało nam się jeszcze znaleźć prostego sposobu na przeniesienie wyodrębnionej wiedzy do codziennej praktyki klinicznej, ponieważ lekarze musieli "bawić się" różnymi dawkami, aby przeanalizować najlepsze rozwiązanie w celu osiągnięcia określonego poziomu Hb. Lepiej byłoby mieć automatyczny model, który sugeruje działania, które należy podjąć, aby osiągnąć docelowy zakres Hb, niż to "pośrednie" podejście. Ta refleksja skłoniła nas do zbadania nowych modeli i wpadliśmy na pomysł wykorzystania RL. Obecnie pracujemy nad tym tematem, ale już osiągnęliśmy obiecujące wyniki, znajdując zasady (sekwencję działań), które wydają się być lepsze od tych stosowanych w szpitalu, tj. istnieje większa liczba pacjentów w pożądanym docelowym poziomie Hb pod koniec leczenia.
Systemy rekomendacji internetowych
W tej podsekcji opisano zupełnie inne zastosowanie, a mianowicie rozwój systemów rekomendacji internetowych. Autorzy zaproponowali nowe podejście do rozwoju systemów rekomendacji opartych na filtrowaniu kolaboracyjnym, ale obejmujących również analizę wykonalności rekomendacji przy użyciu etapu predykcji. Podstawowym pomysłem było wykorzystanie algorytmów klastrowania w celu znalezienia grup podobnych użytkowników. Pod uwagę wzięto następujące algorytmy klastrowania: KMeans, FCM, HCA, algorytm EM, SOM i ART. Nowi użytkownicy zostali przypisani do jednej z grup znalezionych przez te algorytmy klastrowania, a następnie zostali oni poleceni za pomocą usług internetowych, do których zwykle uzyskiwali dostęp inni użytkownicy z tej samej grupy, ale do których nie uzyskali jeszcze dostępu ci nowi użytkownicy (w celu zmaksymalizowania użyteczności podejścia). Korzystając z kontrolowanych zestawów danych, badanie wykazało, że ART i SOM wykazały bardzo dobre zachowanie ze zestawami danych o bardzo różnych cechach, podczas gdy HCA i EM wykazały akceptowalne zachowanie pod warunkiem, że wymiarowość zestawu danych nie była zbyt wysoka, a nakładanie się było niewielkie. Algorytmy oparte na K-Means osiągnęły najbardziej ograniczony sukces w akceptacji oferowanych rekomendacji. Mimo że wykorzystanie RL zostało zbadane tylko w niewielkim stopniu, wydaje się, że jest to odpowiedni wybór dla tego problemu, ponieważ wewnętrzna dynamika problemu jest łatwo rozwiązywana przez RL, a ponadto interferencja między interfejsem rekomendacji a użytkownikiem może zostać zminimalizowana dzięki odpowiedniej definicji nagród
Marketing
Ostatnie zastosowanie, o którym zostanie wspomniane w tej komunikacji, jest związane z marketingiem. Jednym ze sposobów zwiększenia lojalności klientów jest zaoferowanie im możliwości otrzymania prezentów w wyniku zakupów w określonej firmie. Firma może przyznać wirtualne kredyty każdemu, kto kupi określone artykuły, zazwyczaj te, które firma jest zainteresowana promować. Po dokonaniu określonej liczby zakupów klienci mogą wymienić swoje wirtualne kredyty na prezenty oferowane przez firmę. Problem polega na ustaleniu odpowiedniej liczby wirtualnych kredytów dla każdego promowanego przedmiotu. Zgodnie z polityką firmy oczekuje się, że im wyższy przydział kredytów, tym wyższa kwota zakupów. Jednak zyski firmy są niższe, ponieważ kampania marketingowa dodaje firmie dodatkowych kosztów. Celem jest osiągnięcie kompromisu poprzez ustalenie optymalnej polityki. Zaproponowaliśmy podejście RL w celu optymalizacji tej kampanii marketingowej. Ta konkretna aplikacja, której cechy opisano poniżej, jest znacznie trudniejsza niż inne podejścia RL do marketingu wymienione w sekcji Tło. Wynika to zasadniczo z faktu, że istnieje wiele innych różnych działań, które można podjąć. Informacje wykorzystane w badaniu odpowiadają pięciu miesiącom kampanii, obejmującej 1 264 862 transakcje, 1 004 artykuły i 3 573 klientów. RL może radzić sobie z wewnętrzną dynamiką, a poza tym ma atrakcyjną zaletę, która jest w stanie zmaksymalizować tak zwaną długoterminową nagrodę. Jest to szczególnie istotne w tym zastosowaniu, ponieważ firma jest zainteresowana maksymalizacją zysków pod koniec kampanii, a klient, który nie generuje dużych zysków w pierwszych miesiącach kampanii, może jednak dokonać wielu dochodowych transakcji w przyszłości. Nasze pierwsze wyniki pokazały, że zyski przy użyciu polityki opartej na RL zamiast polityki stosowanej przez firmę do tej pory, mogą nawet podwoić długoterminowe zyski pod koniec kampanii .
WNIOSEK I PRZYSZŁE TRENDY
Niniejszy artykuł wykazał możliwości i wszechstronność różnych metod AI do zastosowania w rzeczywistych problemach, zilustrowanych trzema konkretnymi zastosowaniami w różnych domenach. Oczywiste jest, że metodologia jest ogólna i równie dobrze sprawdza się w wielu innych dziedzinach, pod warunkiem, że informacje zawarte w danych są wystarczająco bogate, aby wymagać nieliniowego modelowania i są w stanie obsługiwać wydajność predykcyjną, która ma wartość praktyczną. Jako kolejny przyszły trend należy podkreślić, że metody AI są coraz bardziej popularne w zastosowaniach biznesowych w ostatnich latach, rzucając wyzwanie klasycznym modelom biznesowym. W szczególnym przypadku RL potencjał komercyjny tej potężnej metodologii został znacząco niedoceniony, ponieważ jest ona stosowana niemal wyłącznie w robotyce. Uważamy, że jest to metodologia, która wciąż wymaga wykorzystania w wielu rzeczywistych zastosowaniach, jak pokazaliśmy w tym artykule.
Środowiska inteligencji otoczenia
WSTĘP
Trend w kierunku redukcji kosztów sprzętu i miniaturyzacji pozwala na włączanie urządzeń komputerowych do wielu obiektów i środowisk (systemy wbudowane). Inteligencja otoczenia (AmI) zajmuje się nowym światem, w którym urządzenia komputerowe są wszędzie rozproszone (wszechobecność), umożliwiając ludziom interakcję w środowiskach świata fizycznego w sposób inteligentny i dyskretny. Środowiska te powinny być świadome potrzeb ludzi, dostosowywać wymagania i prognozować zachowania. Środowiska AmI mogą być tak różnorodne, jak domy, biura, sale konferencyjne, szkoły, szpitale, centra kontroli, transport, atrakcje turystyczne, sklepy, instalacje sportowe i urządzenia muzyczne. Inteligencja otoczenia obejmuje wiele różnych dyscyplin, takich jak automatyzacja (czujniki, sterowanie i siłowniki), interakcja człowiek-maszyna i grafika komputerowa, komunikacja, wszechobecne przetwarzanie, systemy wbudowane i oczywiście sztuczna inteligencja. Celem badań nad sztuczną inteligencją jest wprowadzenie większej inteligencji do środowisk AmI, co pozwoli na lepsze wsparcie człowieka i dostęp do niezbędnej wiedzy, aby podejmować lepsze decyzje podczas interakcji z tymi środowiskami.
KONTEKST
Ambient Intelligence (AmI) to koncepcja opracowana przez Grupę Doradczą ds. IST Komisji Europejskiej ISTAG (ISTAG, 2001)(ISTAG, 2002). ISTAG uważa, że konieczne jest holistyczne spojrzenie na Ambient Intelligence, biorąc pod uwagę nie tylko technologię, ale cały łańcuch dostaw innowacji od nauki do użytkownika końcowego, a także różne cechy środowiska akademickiego, przemysłowego i administracyjnego, które ułatwiają lub utrudniają realizację wizji AmI (ISTAG, 2003). Ze względu na dużą liczbę technologii zaangażowanych w koncepcję Ambient Intelligence możemy znaleźć kilka prac, które pojawiły się jeszcze przed wizją ISTAG, wskazujących na trendy Ambient Intelligence. Jeśli chodzi o sztuczną inteligencję (AI), Ambient Intelligence jest nowym znaczącym krokiem w ewolucji AI. AI ściśle kroczyło ramię w ramię z ewolucją informatyki i inżynierii. Budowa pierwszych sztucznych modeli neuronowych i sprzętu, z pracą Waltera Pittsa i Warrena McCullocka (Pitts & McCullock, 1943) oraz systemem SNARC Marvina Minsky′ego i Deana Edmondsa odpowiada pierwszemu krokowi. Inteligentne systemy komputerowe, takie jak system ekspercki MYCIN lub inteligentne systemy sieciowe, takie jak AUTHORIZER′S ASSISTANT używane przez American Express do autoryzacji transakcji, konsultujące kilka baz danych, są rodzajem systemów drugiego kroku AI. Od lat 80. inteligentni agenci i systemy wieloagentowe ustanowiły trzeci krok, prowadząc ostatnio do ontologii i sieci semantycznej. Od sprzętu do komputera, od komputera do sieci lokalnej, od sieci lokalnej do Internetu i od Internetu do sieci, sztuczna inteligencja była na poziomie najnowocześniejszych obliczeń, najczęściej trochę wyprzedzając granice technologii. Teraz centrum nie znajduje się już w sprzęcie, komputerze, ani nawet w sieci. Inteligencja musi zostać wprowadzona do naszych codziennych środowisk. Jesteśmy świadomi nacisku w kierunku Inteligentnych Domów, Inteligentnych Pojazdów, Inteligentnych Systemów Transportowych, Inteligentnych Systemów Produkcyjnych, a nawet Inteligentnych Miast. To jest powód, dla którego koncepcja Ambient Intelligence jest obecnie tak ważna. Ambient Intelligence nie jest możliwa bez Sztucznej Inteligencji. Z drugiej strony badacze AI muszą być świadomi potrzeby zintegrowania swoich technik z technikami innych społeczności naukowych (np. Automatyzacja, Grafika Komputerowa, Komunikacja). Ambient Intelligence to ogromne wyzwanie, wymagające większego wysiłku różnych społeczności naukowych. Istnieje wiele różnych koncepcji i technologii związanych z Ambient Intelligence. Ubiquitous Computing, Pervasive Computing, Embedded Systems i Context Awareness to najpopularniejsze z nich. Jednak te koncepcje różnią się od Ambient Intelligence. Koncepcja Ubiquitous Computing (UbiComp) została wprowadzona przez Marka Weisera podczas jego kadencji jako głównego technologa w Palo Alto Research Center (PARC). Ubiquitous Computing oznacza, że mamy dostęp do urządzeń obliczeniowych w dowolnym miejscu w sposób zintegrowany i spójny. Ubiquitous Computing był głównie napędzany przez społeczności naukowe zajmujące się urządzeniami komunikacyjnymi i komputerowymi, ale teraz obejmuje inne obszary badawcze. Ambient Intelligence różni się od Ubiquitous Computing, ponieważ czasami środowisko, w którym rozważa się Ambient Intelligence, jest po prostu lokalne. Inną różnicą jest to, że Ambient Intelligence kładzie większy nacisk na inteligencję niż Ubiquitous Computing. Jednak wszechobecność jest dziś rzeczywistą potrzebą, a systemy Ambient Intelligence biorą pod uwagę tę cechę. Koncepcja, która czasami jest postrzegana jako synonim Ubiquitous Computing, to Pervasive Computing. Według Teresy Dillon, Ubiquitous Computing najlepiej jest postrzegać jako podstawową strukturę, wbudowane systemy, sieci i wyświetlacze, które są niewidoczne i wszędzie, pozwalając nam na "podłączanie i odtwarzanie" urządzeń i narzędzi. Z drugiej strony, Pervasive Computing jest związane ze wszystkimi fizycznymi częściami naszego życia; telefonem komórkowym, komputerem przenośnym lub inteligentną kurtką. Embedded Systems oznacza, że urządzenia elektroniczne i komputerowe są osadzone w obecnych obiektach lub towarach. Obecnie towary, takie jak samochody, są wyposażone w mikroprocesory; to samo dotyczy pralek, lodówek i zabawek. Społeczność Embedded Systems jest bardziej napędzana przez społeczności naukowe zajmujące się elektroniką i automatyzacją. Obecne wysiłki zmierzają w kierunku włączenia urządzeń elektronicznych i komputerowych do najbardziej powszechnych i prostych przedmiotów, których używamy, takich jak meble lub lustra. Ambient Intelligence różni się od Embedded Systems, ponieważ urządzenia komputerowe mogą być wyraźnie widoczne w scenariuszach AmI. Istnieje jednak wyraźna tendencja do angażowania większej liczby systemów wbudowanych w Ambient Intelligence. Context Awareness oznacza, że system jest świadomy bieżącej sytuacji, z którą mamy do czynienia. Przykładem jest automatyczne wykrywanie bieżącej sytuacji w Centrum Kontroli. Czy mamy do czynienia z normalną sytuacją, czy też z sytuacją krytyczną, a nawet awarią? W tym Centrum Kontroli inteligentny procesor alarmowy będzie wykazywał różne wyniki w zależności od zidentyfikowanej sytuacji. Przemysł samochodowy inwestuje również w systemy Context Aware, takie jak wykrywanie niemal wypadków. Społeczność naukowa zajmująca się interakcją człowiek-komputer poświęca wiele uwagi Context Awareness. Context Awareness jest jedną z najbardziej pożądanych koncepcji do uwzględnienia w Ambient Intelligence, identyfikacja kontekstu jest ważna dla podjęcia decyzji o działaniu w sposób inteligentny. Istnieją różne poglądy na temat znaczenia innych koncepcji i technologii w dziedzinie Ambient Intelligence. Zwykle te różnice wynikają z podstawowej społeczności naukowej autorów. ISTAG widzi wymagania dotyczące badań technologicznych z różnych punktów widzenia (komponenty, integracja, system i użytkownik/osoba). W (ISTAG, 2003) wymienione są następujące komponenty otoczenia: inteligentne materiały; technologie MEMS i czujników; systemy wbudowane; wszechobecna komunikacja; technologia urządzeń wejścia/wyjścia; oprogramowanie adaptacyjne. W tym samym dokumencie ISTAG odnosi się do następujących komponentów inteligencji: zarządzanie i obsługa mediów; naturalna interakcja; inteligencja obliczeniowa; świadomość kontekstu; i obliczenia emocjonalne. Ostatnio inteligencja otoczenia otrzymuje znaczną uwagę ze strony społeczności sztucznej inteligencji. Możemy odnieść się do warsztatów poświęconych inteligencji otoczenia, zorganizowanych przez Juana Augusto i Daniela Shapiro na ECAI'2006 (Europejskiej Konferencji na temat Sztucznej Inteligencji) i IJCAI'2007 (Międzynarodowej Wspólnej Konferencji na temat Sztucznej Inteligencji), a także do numeru specjalnego poświęconego inteligencji otoczenia, koordynowanego przez Carlosa Ramosa, Juana Augusto i Daniela Shapiro, który ukaże się w numerze czasopisma IEEE Intelligent Systems z marca/kwietnia 2008 r. Istnieje wiele różnych koncepcji i technologii związanych z Ambient Intelligence. Ubiquitous Computing, Pervasive Computing, Embedded Systems i Context Awareness to najpopularniejsze z nich. Jednak te koncepcje różnią się od Ambient Intelligence. Koncepcja Ubiquitous Computing (UbiComp) została wprowadzona przez Marka Weisera podczas jego kadencji jako głównego technologa w Palo Alto Research Center (PARC). Ubiquitous Computing oznacza, że mamy dostęp do urządzeń obliczeniowych w dowolnym miejscu w sposób zintegrowany i spójny. Ubiquitous Computing był głównie napędzany przez społeczności naukowe zajmujące się urządzeniami komunikacyjnymi i komputerowymi, ale teraz obejmuje inne obszary badawcze. Ambient Intelligence różni się od Ubiquitous Computing, ponieważ czasami środowisko, w którym rozważa się Ambient Intelligence, jest po prostu lokalne. Inną różnicą jest to, że Ambient Intelligence kładzie większy nacisk na inteligencję niż Ubiquitous Computing. Jednak wszechobecność jest dziś rzeczywistą potrzebą, a systemy Ambient Intelligence biorą pod uwagę tę cechę. Koncepcja, która czasami jest postrzegana jako synonim Ubiquitous Computing, to Pervasive Computing. Według Teresy Dillon, Ubiquitous Computing najlepiej jest postrzegać jako podstawową strukturę, wbudowane systemy, sieci i wyświetlacze, które są niewidoczne i wszędzie, pozwalając nam na "podłączanie i odtwarzanie" urządzeń i narzędzi. Z drugiej strony, Pervasive Computing jest związane ze wszystkimi fizycznymi częściami naszego życia; telefonem komórkowym, komputerem przenośnym lub inteligentną kurtką. Embedded Systems oznacza, że urządzenia elektroniczne i komputerowe są osadzone w obecnych obiektach lub towarach. Obecnie towary, takie jak samochody, są wyposażone w mikroprocesory; to samo dotyczy pralek, lodówek i zabawek. Społeczność Embedded Systems jest bardziej napędzana przez społeczności naukowe zajmujące się elektroniką i automatyzacją. Obecne wysiłki zmierzają w kierunku włączenia urządzeń elektronicznych i komputerowych do najbardziej powszechnych i prostych przedmiotów, których używamy, takich jak meble lub lustra. Ambient Intelligence różni się od Embedded Systems, ponieważ urządzenia komputerowe mogą być wyraźnie widoczne w scenariuszach AmI. Istnieje jednak wyraźna tendencja do angażowania większej liczby systemów wbudowanych w Ambient Intelligence. Context Awareness oznacza, że system jest świadomy bieżącej sytuacji, z którą mamy do czynienia. Przykładem jest automatyczne wykrywanie bieżącej sytuacji w Centrum Kontroli. Czy mamy do czynienia z normalną sytuacją, czy też z sytuacją krytyczną, a nawet awarią? W tym Centrum Kontroli inteligentny procesor alarmowy będzie wykazywał różne wyniki w zależności od zidentyfikowanej sytuacji . Przemysł samochodowy inwestuje również w systemy Context Aware, takie jak wykrywanie niemal wypadków. Społeczność naukowa zajmująca się interakcją człowiek-komputer poświęca wiele uwagi Context Awareness. Context Awareness jest jedną z najbardziej pożądanych koncepcji do uwzględnienia w Ambient Intelligence, identyfikacja kontekstu jest ważna dla podjęcia decyzji o działaniu w sposób inteligentny. Istnieją różne poglądy na temat znaczenia innych koncepcji i technologii w dziedzinie Ambient Intelligence. Zwykle te różnice wynikają z podstawowej społeczności naukowej autorów. ISTAG widzi wymagania dotyczące badań technologicznych z różnych punktów widzenia (komponenty, integracja, system i użytkownik/osoba). W (ISTAG, 2003) wymienione są następujące komponenty otoczenia: inteligentne materiały; technologie MEMS i czujników; systemy wbudowane; wszechobecna komunikacja; technologia urządzeń wejścia/wyjścia; oprogramowanie adaptacyjne. W tym samym dokumencie ISTAG odnosi się do następujących komponentów inteligencji: zarządzanie i obsługa mediów; naturalna interakcja; inteligencja obliczeniowa; świadomość kontekstu; i obliczenia emocjonalne. Ostatnio inteligencja otoczenia otrzymuje znaczną uwagę ze strony społeczności sztucznej inteligencji. Możemy odnieść się do warsztatów poświęconych inteligencji otoczenia, zorganizowanych przez Juana Augusto i Daniela Shapiro na ECAI'2006 (Europejskiej Konferencji na temat Sztucznej Inteligencji) i IJCAI'2007 (Międzynarodowej Wspólnej Konferencji na temat Sztucznej Inteligencji), a także do numeru specjalnego poświęconego inteligencji otoczenia, koordynowanego przez Carlosa Ramosa, Juana Augusto i Daniela Shapiro, który ukaże się w numerze czasopisma IEEE Intelligent Systems z marca/kwietnia 2008 r.
PROTOTYPY I SYSTEMY INTELIGENTNEJ OTOCZENIA
Tutaj przeanalizujemy kilka przykładów prototypów i systemów inteligencji otoczenia, podzielonych ze względu na obszar zastosowań.
AmI at Home
Domotics to skonsolidowany obszar działalności. Po pierwszych doświadczeniach z Domotics w domach pojawił się trend nawiązywania do koncepcji Inteligentnego Domu. Jednak Domotics jest zbyt skoncentrowany na automatyce, dając użytkownikowi możliwość kontrolowania urządzeń domowych z dowolnego miejsca. Nadal jesteśmy daleko od prawdziwej Inteligencji Otoczenia w domach, przynajmniej na poziomie komercyjnym. W Wichert, Hellschimidt, 2006, znajduje się interesujący przykład w celach projektu EMBASSI, kobieta gestem nakazuje telewizorowi rozjaśnić, jednak telewizor jest już na najjaśniejszym poziomie, więc światła zmniejszają poziom, a okna się zamykają, pokazując przykład świadomości kontekstu w otoczeniu. Kilka organizacji przeprowadza eksperymenty w celu osiągnięcia koncepcji Inteligentnego Domu. Niektóre przykłady to HomeLab firmy Philips, MIT House_n, Georgia Tech Aware Home, Microsoft Concept Home i e2 Home firm Electrolux i Ericsson. AmI w pojazdach i transporcie Od czasu pierwszych doświadczeń z NAVLAB 1 (Thorpe, Herbert, Kanade, Shafer, 1988) Carnegie Mellon University opracowało kilka prototypów do autonomicznej jazdy i pomocy pojazdom. Ostatni z nich, NAVLAB 11, to autonomiczny Jeep. Większość firm z branży samochodowej prowadzi badania w obszarze inteligentnych pojazdów do różnych zadań, takich jak pomoc w parkowaniu lub wykrywanie kolizji. Innym przykładem zastosowania AmI jest powiązanie z transportem, a mianowicie w powiązaniu z inteligentnymi systemami transportowymi (ITS). Wspólny program ITS Departamentu Transportu USA zidentyfikował kilka obszarów zastosowań, a mianowicie: zarządzanie arteriami; zarządzanie autostradami; zarządzanie tranzytem; zarządzanie incydentami; zarządzanie pojawianiem się; płatności elektroniczne; informacje dla podróżnych; zarządzanie informacją; zapobieganie wypadkom i bezpieczeństwo; operacje drogowe i zarządzanie nimi; zarządzanie pogodą na drogach; operacje pojazdów komercyjnych; i transport intermodalny. We wszystkich tych obszarach zastosowań można stosować Ambient Intelligence.
AmI w opiece zdrowotnej i osobach starszych
Kilka badań wskazuje na starzenie się populacji w ciągu najbliższych dekad. Chociaż jest to dobry wynik wzrostu oczekiwanej długości życia, to również wiąże się z pewnymi problemami. Odsetek populacji z problemami zdrowotnymi wzrośnie i będzie bardzo trudno aby szpitale utrzymały wszystkich pacjentów. Nasze społeczeństwo stoi przed odpowiedzialnością za opiekę nad tymi ludźmi w najlepszy możliwy sposób społeczny i ekonomiczny. Istnieje więc wyraźne zainteresowanie stworzeniem urządzeń i środowisk Ambient Intelligence, umożliwiających śledzenie pacjentów w ich własnych domach lub w trakcie ich codziennego życia. Urządzenia wspomagające kontrolę medyczną mogą być osadzone w ubraniach, takich jak koszulki, zbierając informacje o parametrach życiowych z czujników (np. ciśnienie krwi, temperatura). Pacjenci będą monitorowani z dużej odległości. Otaczające środowisko, na przykład dom pacjenta, może być świadome wyników z danych klinicznych, a nawet wykonywać połączenia alarmowe w celu wezwania pogotowia ratunkowego. Na przykład możemy odnieść się do systemu IST Vivago (IST International Security Technology Oy, Helsinki, Finlandia), aktywnego systemu alarmów społecznych, który łączy inteligentne alarmy społeczne z ciągłym zdalnym monitorowaniem profilu aktywności użytkownika .
AmI w turystyce i dziedzictwie kulturowym
Turystyka i dziedzictwo kulturowe to dobre obszary zastosowań dla inteligencji otoczenia. Turystyka to rozwijająca się branża. W przeszłości turyści byli zadowoleni z wstępnie zdefiniowanych wycieczek, równych dla wszystkich ludzi. Istnieje jednak trend w dostosowywaniu i ta sama wycieczka może być pomyślana tak, aby dostosować się do turystów zgodnie z ich preferencjami. Przykładem takiego doświadczenia jest immersyjny post wycieczkowy. MEGA to przyjazny użytkownikowi wirtualny przewodnik, który pomaga odwiedzającym Parco Archeologico della Valle del Temple w Agrigento, obszarze archeologicznym ze starożytnymi greckimi świątyniami w Agrigento, położonym na Sycylii, we Włoszech. DALICA została wykorzystana do skonstruowania i aktualizacji profilu użytkownika odwiedzających Villa Adriana w Tivoli, niedaleko Rzymu, we Włoszech
AmI w pracy
Człowiek spędza dużo czasu w miejscach pracy, takich jak biura, sale konferencyjne, zakłady produkcyjne, centra sterowania. SPARSE to projekt pierwotnie stworzony w celu pomocy operatorom centrów sterowania systemami energetycznymi w diagnozowaniu i przywracaniu po incydentach. Jest to dobry przykład świadomości kontekstu, ponieważ opracowany system jest świadomy bieżącej sytuacji, działając w różny sposób w zależności od normalnej lub krytycznej sytuacji systemu energetycznego. System ten ewoluuje w kierunku ram inteligencji otoczenia stosowanych w centrach sterowania. Podejmowanie decyzji jest jedną z najważniejszych czynności człowieka. Obecnie decyzje oznaczają rozważenie wielu różnych punktów widzenia, więc decyzje są powszechnie podejmowane przez formalne lub nieformalne grupy osób. Grupy wymieniają się pomysłami lub angażują się w proces argumentacji i kontrargumentacji, negocjują, współpracują, współdziałają, a nawet omawiają techniki i/lub metodologie rozwiązywania problemów. Podejmowanie decyzji grupowych to aktywność społeczna, w której dyskusja i wyniki uwzględniają połączenie aspektów racjonalnych i emocjonalnych. ArgEmotionAgents to projekt w obszarze zastosowania AmbientIntelligence w argumentacji grupowej i wspomaganiu decyzji, uwzględniający aspekty emocjonalne i działający w Laboratory of Ambient Intelligence for Decision Support (LAID),, swego rodzaju Intelligent Decision Room. Ta praca ma również część obejmującą wsparcie wszechobecności. AmI w sporcie Sporty obejmują sportowców na wysokim poziomie i wielu innych praktyków. Wiele sportów uprawia się bez pomocy powiązanych urządzeń, co otwiera tutaj wyraźną okazję dla Ambient Intelligence do tworzenia urządzeń i środowisk wspomagających sport. FlyMaster NAV+ to asystent pilota na pokładzie samolotu (np. szybowanie, paralotniarstwo), wykorzystujący moduł FlyMaster F1 z dostępem do GPS i informacji sensorycznych. FlyMaster Avionics S.A., spółka spin-off, została utworzona w celu komercjalizacji tych produktów
PLATFORMY AMBIENT INTELLIGENCE
Niektóre firmy i instytucje akademickie inwestują w tworzenie platform generujących Ambient Intelligence. Projekt Endeavour jest rozwijany przez California University w Berkeley . Celem projektu jest określenie, zaprojektowanie i wdrożenie prototypów na skalę planety, samoorganizujących się i obejmujących adaptacyjne "Information Utility". Oxygen umożliwia wszechobecne obliczenia zorientowane na człowieka poprzez połączenie określonych technologii użytkownika i systemu. Projekt ten zapewnia technologie mowy i wizji, które umożliwiają nam komunikowanie się z Oxygen tak, jakbyśmy wchodzili w interakcję z inną osobą, oszczędzając wiele czasu i wysiłku. Projekt Portolano został opracowany na University of Washington i ma na celu stworzenie poligonu doświadczalnego do badań nad powstającą dziedziną niewidzialnych obliczeń. Niewidzialne obliczenia są możliwe dzięki urządzeniom tak wysoce zoptymalizowanym do konkretnych zadań, że dostosowują się do świata i wymagają od użytkowników niewielkiej wiedzy technicznej. Projekt EasyLiving Microsoft Research Vision Group odpowiada prototypowej architekturze i powiązanym technologiom do budowania inteligentnych środowisk. Celem EasyLiving jest ułatwienie interakcji ludzi z innymi ludźmi, z komputerem i z urządzeniami
TRENDY PRZYSZŁOŚCI
Ambient Intelligence zajmuje się futurystyczną koncepcją naszego życia. Większość praktycznych doświadczeń dotyczących Ambient Intelligence jest nadal w bardzo początkowej fazie, ze względu na niedawne pojawienie się tej koncepcji. Obecnie nie jest jasne, jaki jest podział między komputerem a
środowiskami. Jednak dla nowych pokoleń rzeczy będą bardziej przejrzyste, a środowiska z Ambient Intelligence będą szerzej akceptowane. W obszarze transportu AmI obejmie kilka aspektów. Pierwszy będzie związany z samym pojazdem. Kilka funkcji zacznie być dostępnych, takich jak automatyczna identyfikacja sytuacji (np. identyfikacja przedkolizyjna, identyfikacja warunków kierowcy). Inne aspekty będą związane z informacjami o ruchu drogowym. Obecnie urządzenia GPS są uogólnione, ale zajmują się informacjami statycznymi. Łączenie warunków ruchu drogowego online umożliwi kierowcy unikanie dróg z wypadkami. Technologia daje dobre kroki w kierunku automatycznej jazdy pojazdem. Jednak w niedalekiej przyszłości opracowany system będzie postrzegany bardziej jako asystenci kierowcy pomimo autonomicznych systemów jazdy. Innym obszarem, w którym AmI doświadczy silnego rozwoju, będzie obszar opieki zdrowotnej, zwłaszcza w opiece nad osobami starszymi. Pacjenci otrzymają to wsparcie, aby umożliwić bardziej autonomiczne życie w swoich domach. Jednak automatyczne pozyskiwanie sygnałów życiowych (np. ciśnienia krwi, temperatury) umożliwi automatyczne wykonywanie połączeń alarmowych, gdy zdrowie pacjenta będzie w znacznym stopniu zagrożone. Monitorowanie osoby będzie również wykonywane w jej/jego domu, próbując wykryć różnice w oczekiwanych sytuacjach i nawykach. Wsparcie domowe pozwoli osiągnąć normalne życie osobiste i rodzinne. Inteligentne domy staną się rzeczywistością. Mieszkańcy domów będą zwracać mniejszą uwagę na normalne aspekty zarządzania domem, na przykład na to, ile butelek czerwonego wina jest dostępnych na tygodniowe posiłki lub czy wszystkie składniki na ciasto są dostępne. Oczekuje się również AmI do wsparcia pracy. Systemy wspomagania decyzji będą zorientowane na środowiska pracy. Będzie to jasne w biurach, salach konferencyjnych, centrach obsługi telefonicznej, centrach kontroli i zakładach.
WNIOSEK
W tym artykule przedstawiono stan wiedzy w zakresie dziedziny inteligencji otoczenia. Po zapoznaniu się z historią koncepcji ustanowiliśmy pewne definicje powiązanych koncepcji i zilustrowaliśmy je kilkoma przykładami. Istnieje długa droga do przebycia, aby osiągnąć koncepcję inteligencji otoczenia, jednak w przyszłości koncepcja ta będzie określana jako jeden z kamieni milowych w rozwoju sztucznej inteligencji.
Sztuczna inteligencja i edukacja
WSTĘP
Rządy i instytucje stają w obliczu nowych wymagań szybko zmieniającego się społeczeństwa. Spośród wielu istotnych trendów należy wziąć pod uwagę kilka faktów : (1) wzrost liczby i rodzaju studentów; oraz (2) ograniczenia narzucone przez koszty edukacji i harmonogramy kursów. W przypadku pierwszego, potrzeba ciągłej aktualizacji wiedzy i kompetencji w zmieniającym się środowisku pracy wymaga rozwiązań uczenia się przez całe życie. Coraz większa liczba młodych dorosłych wraca do szkół, aby ukończyć studia podyplomowe lub uczestniczyć w programach podyplomowych, aby uzyskać specjalizację w określonej dziedzinie. W przypadku drugiego, ze względu na pojawienie się nowych typów studentów, pojawiają się ograniczenia budżetowe i konflikty w harmonogramie. Na przykład pracownicy i imigranci to istotne grupy, dla których koszty edukacji i harmonogramy niezgodne z pracą mogą być kluczowym czynnikiem decydującym o zapisaniu się na kurs lub rezygnacji z programu po zainwestowaniu w niego czasu i wysiłku. Aby rozwiązać potrzeby wynikające z tego kontekstu społecznego, należy zaproponować nowe podejścia edukacyjne: (1) ulepszyć i rozszerzyć kursy nauki online, co obniżyłoby koszty dla studentów i umożliwiło pokrycie potrzeb edukacyjnych większej liczby studentów oraz (2) zautomatyzować procesy uczenia się, a następnie obniżyć koszty dla nauczycieli i zapewnić bardziej spersonalizowane doświadczenie edukacyjne w dowolnym czasie i miejscu. W wyniku tego kontekstu w ostatniej dekadzie zaobserwowano rosnące zainteresowanie zastosowaniem technologii komputerowych w dziedzinie edukacji. W związku z tym paradygmaty dziedziny sztucznej inteligencji (AI) przyciągają szczególną uwagę, aby rozwiązać problemy wynikające z wprowadzenia komputerów jako zasobów pomocniczych różnych strategii uczenia się. W tym artykule dokonujemy przeglądu stanu wiedzy w zakresie stosowania technik sztucznej inteligencji w dziedzinie edukacji, koncentrując się na (1) najpopularniejszych narzędziach edukacyjnych opartych na AI oraz (2) najbardziej odpowiednich technikach AI stosowanych w rozwoju inteligentnych systemów edukacyjnych.
PRZYKŁADY NARZĘDZI EDUKACYJNYCH OPARTYCH NA AI
Dziedzina sztucznej inteligencji może wnieść interesujące rozwiązania do potrzeb domeny edukacyjnej . Poniżej przedstawiono typy systemów, które można zbudować w oparciu o techniki AI.
Inteligentne Systemy Tutoringu
Inteligentne Systemy Tutoringu to aplikacje, które zapewniają spersonalizowaną/adaptacyjną naukę bez interwencji nauczycieli. Składają się z trzech głównych komponentów: (1) wiedzy o treściach edukacyjnych, (2) wiedzy o uczniu i (3) wiedzy o procedurach i metodologiach uczenia się. Systemy te obiecują radykalnie zmienić naszą wizję nauki online. W przeciwieństwie do aplikacji e-learningowych opartych na hipertekście, które zapewniają uczniom pewną liczbę możliwości wyszukania prawidłowej odpowiedzi przed jej wyświetleniem, inteligentne systemy tutoringu działają jak trenerzy nie tylko po wprowadzeniu odpowiedzi, ale także oferują sugestie, gdy uczniowie mają wątpliwości lub są zablokowani w trakcie rozwiązywania problemu. W ten sposób pomoc kieruje procesem uczenia się, a nie tylko mówi, co jest poprawne, a co nie. Istnieje wiele przykładów inteligentnych systemów tutoringu, niektóre z nich opracowano na uniwersytetach jako projekty badawcze, a inne stworzono z myślą o celach biznesowych. Wśród pierwszych, popularnym przykładem są systemy Andes , opracowane pod kierownictwem Kurta VanLehna z University of Pittsburg. System odpowiada za kierowanie uczniami, gdy próbują oni rozwiązywać różne zestawy problemów i ćwiczeń. Gdy uczeń prosi o pomoc w trakcie wykonywania zadania, system albo udziela wskazówek, aby przejść dalej w kierunku rozwiązania, albo wskazuje, co było nie tak na jakimś wcześniejszym etapie. Andes został pomyślnie oceniony w ciągu 5 lat w Naval Academy of the United States i można go pobrać bezpłatnie. Innym istotnym systemem jest Cognitive Tutor, jest to kompleksowy program nauczania matematyki w szkołach średnich i program korepetycji oparty na komputerze opracowany przez Johna R. Andersona, profesora na Carnegie Mellon University. Cognitive Tutor jest przykładem tego, jak prototypy badawcze mogą ewoluować w rozwiązania komercyjne, jak to jest obecnie stosowane w 1500 szkołach w Stanach Zjednoczonych. Z punktu widzenia biznesu Read-On! jest prezentowany jako produkt, który uczy umiejętności czytania ze zrozumieniem dla dorosłych. Analizuje i diagnozuje konkretne niedobory i problemy każdego ucznia, a następnie dostosowuje proces uczenia się na podstawie tych cech. Zawiera narzędzie autorskie, które pozwala projektantom kursów dostosowywać treści kursów do różnych profili uczniów w szybki i elastyczny sposób.
Systemy automatycznej oceny
Systemy automatycznej oceny koncentrują się głównie na ocenie mocnych i słabych stron uczniów w różnych działaniach edukacyjnych za pomocą testów oceniających. W ten sposób systemy te nie tylko wykonują automatyczną korektę testu, ale także automatycznie uzyskują przydatne informacje o kompetencjach i umiejętnościach uzyskanych przez uczniów w trakcie procesu edukacyjnego. Wśród automatycznych systemów oceniania możemy wyróżnić ToL (Test On Line), z którego korzystają studenci fizyki na Politechnice w Mediolanie. System składa się z bazy danych testów, algorytmu doboru pytań i mechanizmu automatycznej oceny testów, który może być dodatkowo konfigurowany przez nauczycieli. CELLA (Comprehensive English Language Learning Assesment) to kolejny system, który ocenia kompetencje studentów w zakresie używania i rozumienia języka angielskiego. Aplikacja pokazuje postępy studentów i określa ich biegłość i stopień kompetencji w zakresie używania języków obcych. Jeśli chodzi o aplikacje komercyjne, Intellimetric to system internetowy, który umożliwia studentom przesyłanie swoich prac online. W ciągu kilku sekund wspomagany przez sztuczną inteligencję moduł oceniania automatycznie podaje ocenę pracy. Firma twierdzi, że niezawodność wynosi 99%, co oznacza, że w 99 procentach przypadków wyniki wyszukiwarki pokrywają się z wynikami podanymi przez nauczycieli.
Wspomagane komputerowo uczenie się współpracy
Środowiska wspomaganego komputerowo uczenia się współpracy mają na celu ułatwienie procesu uczenia się, zapewniając uczniom zarówno kontekst, jak i narzędzia do interakcji i pracy w sposób współpracy z kolegami z klasy. W systemach opartych na inteligencji współpraca jest zwykle realizowana przy pomocy agentów oprogramowania odpowiedzialnych za pośredniczenie i wspieranie interakcji uczniów w celu osiągnięcia proponowanych celów nauczania. Prototypy badawcze są odpowiednimi poligonami doświadczalnymi do udowadniania nowych pomysłów i koncepcji, aby zapewnić najlepsze strategie współpracy. System DEGREE, na przykład, umożliwia scharakteryzowanie zachowań grupowych, jak również indywidualnych zachowań osób je tworzących, na podstawie zestawu atrybutów lub tagów. Agent mediator wykorzystuje te atrybuty, które są wprowadzane przez uczniów, w celu zapewnienia rekomendacji i sugestii w celu poprawy interakcji wewnątrz każdej grupy . W dziedzinie biznesu istnieje wiele rozwiązań, chociaż nie oferują one inteligentnej mediacji ułatwiającej interakcje współpracy. System DEBBIE (DePauw Electronic Blackboard for Interactive Education) jest jednym z najpopularniejszych. Został pierwotnie opracowany na początku 2000 roku na Uniwersytecie DePauw, a później zarządzany przez firmę DyKnow, która została specjalnie stworzona, aby osiągać zyski z DEBBIE . Technologia, którą obecnie oferuje DyKnow, pozwala zarówno nauczycielom, jak i uczniom na natychmiastowe dzielenie się informacjami i pomysłami. Ostatecznym celem jest wspieranie zadań uczniów w klasie poprzez wyeliminowanie potrzeby wykonywania prostych zadań, takich jak na przykład tworzenie kopii zapasowych prezentacji nauczyciela. Uczniowie mogliby zatem bardziej skupić się na zrozumieniu, a także analizowaniu koncepcji przedstawionych przez nauczyciela.
Nauka oparta na grach
Nauka oparta na grach poważnych, termin ukuty w celu rozróżnienia gier zorientowanych na naukę, stosowanych w edukacji, od gier zorientowanych wyłącznie na rozrywkę, zajmuje się wykorzystaniem siły motywacyjnej i atrakcyjności gier w dziedzinie edukacji w celu poprawy satysfakcji i wyników uczniów podczas zdobywania nowej wiedzy i umiejętności. Ten rodzaj nauki pozwala na prowadzenie działań w złożonych środowiskach edukacyjnych, których nie dałoby się wdrożyć ze względu na ograniczenia budżetowe, czasowe, infrastrukturalne i bezpieczeństwa przy użyciu tradycyjnych zasobów. NetAid to instytucja, która opracowuje gry, aby uczyć koncepcji obywatelstwa globalnego i uwrażliwiać na walkę z ubóstwem. Jedna z jej pierwszych gier, wydana w 2002 roku, zwana NetAid World Class, polega na przyjęciu tożsamości prawdziwego dziecka mieszkającego w Indiach i rozwiązaniu prawdziwych problemów, z którymi borykają się biedne dzieci w tym regionie. W 2003 roku gra była używana przez 40 000 uczniów w różnych szkołach w Stanach Zjednoczonych. W biznesie i rozrywce istnieje wiele gier, które można wykorzystać do osiągnięcia celów edukacyjnych. Wśród najpopularniejszych jest Brain Training of Nintendo (Brain Training, 2007), który rzuca użytkownikowi wyzwanie poprawy jego kondycji umysłowej poprzez wykonywanie ćwiczeń pamięciowych, rozumowania i matematycznych. Ostatecznym celem jest osiągnięcie optymalnego wieku mózgowego po regularnym treningu.
TECHNIKI AI W EDUKACJI
Inteligentne systemy edukacyjne omówione powyżej opierają się na różnorodnych technikach sztucznej inteligencji. Najczęściej stosowane w dziedzinie edukacji to: (1) mechanizmy personalizacji oparte na modelach uczniów i grup, (2) inteligentni agenci i systemy oparte na agentach oraz (3) ontologie i techniki sieci semantycznej.
Mechanizmy personalizacji
Techniki personalizacji, które są podstawą inteligentnych systemów nauczania, obejmują tworzenie i wykorzystywanie modeli uczniów. Mówiąc ogólnie, modele te implikują konstrukcję jakościowej reprezentacji zachowań uczniów w kategoriach istniejącej wiedzy tła na temat domeny. Te reprezentacje mogą być dalej wykorzystywane w inteligentnych systemach nauczania, inteligentnych środowiskach edukacyjnych i do opracowywania autonomicznych inteligentnych agentów, którzy mogą współpracować z uczniami-ludźmi w trakcie procesu uczenia się. Wprowadzenie technik uczenia maszynowego ułatwia aktualizację i rozszerzanie pierwszych wersji modeli studentów w celu dostosowania ich do ewolucji każdego studenta, a także możliwych zmian i modyfikacji treści i działań edukacyjnych. Najpopularniejszymi technikami modelowania studentów są : modele nakładkowe i modele sieci bayesowskich. Pierwsza metoda polega na traktowaniu modelu studenta jako podzbioru wiedzy eksperta w dziedzinie, w której odbywa się nauka. W rzeczywistości stopień nauki jest mierzony w kategoriach porównania wiedzy nabytej i reprezentowanej w modelu studenta z tłem początkowo przechowywanym w modelu eksperta. Druga metoda zajmuje się reprezentacją procesu uczenia się jako sieci stanów wiedzy. Po zdefiniowaniu model powinien wnioskować, na podstawie interakcji tutor-uczeń, prawdopodobieństwo, że student znajdzie się w określonym stanie.
Inteligentni agenci i systemy oparte na agentach
Agenci oprogramowania są uważani za byty oprogramowania, takie jak programy oprogramowania lub roboty, które prezentują, w różnym stopniu, trzy główne atrybuty: autonomię, współpracę i uczenie się. Autonomia odnosi się do zasady, że agent może działać samodzielnie (działając i decydując o własnej reprezentacji świata). Współpraca odnosi się do zdolności do interakcji z innymi agentami za pośrednictwem pewnego języka komunikacji. Wreszcie, uczenie się jest niezbędne do reagowania lub interakcji ze środowiskiem zewnętrznym. Zespoły inteligentnych agentów budują systemy wieloagentowe (MAS). W tego typu systemach każdy agent ma albo niekompletne informacje, albo ograniczone możliwości rozwiązania danego problemu. Innym ważnym aspektem jest brak scentralizowanej kontroli globalnej; dlatego dane są rozproszone w całym systemie, a obliczenia są asynchroniczne (Sycara, 1998). Wiele ważnych zadań może być wykonywanych przez inteligentnych agentów w kontekście systemów edukacyjnych i uczących się : monitorowanie danych wejściowych, wyników i wyników aktywności wytworzonych przez uczniów; weryfikacja terminów podczas oddawania prac domowych i ćwiczeń; automatyczne odpowiadanie na pytania uczniów; automatyczne ocenianie testów i ankiet.
Ontologie i techniki sieci semantycznej
Ontologie mają na celu uchwycenie i przedstawienie wiedzy konsensualnej w sposób ogólny oraz mogą być ponownie wykorzystywane i udostępniane w aplikacjach oprogramowania . Ontologia składa się z pojęć lub klas i ich atrybutów, relacji między pojęciami, właściwości tych relacji oraz aksjomatów i reguł, które jawnie reprezentują wiedzę z określonej dziedziny. W dziedzinie edukacji zaproponowano kilka ontologii: (1) w celu opisania treści nauczania dokumentów technicznych , (2) w celu modelowania elementów wymaganych do projektowania, analizy i oceny interakcji między uczniami w uczeniu kooperatywnym wspomaganym komputerowo , (3) w celu określenia wiedzy potrzebnej do zdefiniowania nowych scenariuszy uczenia się kooperatywnego , (4) w celu sformalizowania semantyki obiektów nauczania opartych na standardach metadanych oraz (5) w celu opisania semantyki języków projektowania nauczania
PRZYSZŁE TRENDY
Następna generacja adaptacyjnych środowisk zintegruje agentów pedagogicznych, wzbogaconych o techniki eksploracji danych i uczenia maszynowego, zdolnych do zapewnienia diagnozy poznawczej uczniów, która pomoże określić stan procesu uczenia się, a następnie zoptymalizować wybór spersonalizowanych projektów uczenia się. Ponadto ulepszone modele uczniów, osób ułatwiających, zadań i procesów rozwiązywania problemów, w połączeniu z wykorzystaniem ontologii i silników rozumowania, ułatwią wykonywanie działań edukacyjnych na platformach online lub w tradycyjnych warunkach klasowych. Badania w tej dziedzinie są bardzo aktywne i stawiają sobie ambitne cele. W niektórych dekadach można by pomarzyć o środowiskach science fiction, w których uczniowie mieliby interfejsy mózgowe do bezpośredniej interakcji z inteligentnym asystentem, który pełniłby rolę nauczyciela z bezpośrednim połączeniem z obszarami mózgu odpowiedzialnymi za naukę.
WNIOSEK
W tym artykule dokonaliśmy przeglądu najnowocześniejszych rozwiązań w zakresie stosowania technik sztucznej inteligencji w dziedzinie edukacji. Podejścia AI wydają się obiecujące w zakresie poprawy jakości procesu uczenia się, a następnie zaspokojenia nowych wymagań szybko zmieniającego się społeczeństwa. Obecne systemy oparte na sztucznej inteligencji, takie jak inteligentne systemy nauczania, wspomagane komputerowo uczenie się grupowe i gry edukacyjne, udowodniły już możliwości stosowania technik sztucznej inteligencji. Przyszłe aplikacje ułatwią zarówno spersonalizowane style uczenia się, jak i pomogą nauczycielom i uczniom w tradycyjnych warunkach klasowych.
Sztuczna inteligencja i stabilność falochronu gruzowego
WSTĘP
Falochrony to konstrukcje przybrzeżne, które mają chronić basen portowy przed falami. Istnieją dwa główne typy: falochrony z gruzu kamiennego, składające się z różnych warstw kamieni lub kawałków betonu o różnych rozmiarach (ciężarach), tworzących porowaty kopiec; oraz falochrony pionowe, nieprzepuszczalne i monolityczne, zwykle składające się z betonowych kesonów. Niniejszy artykuł dotyczy falochronów z gruzu kamiennego. Typowy falochron z gruzu kamiennego składa się z warstwy pancernej, warstwy filtracyjnej i rdzenia. Aby falochron był stabilny, jednostki warstwy pancernej (kamienie lub kawałki betonu) nie mogą zostać usunięte przez działanie fal. Stabilność jest zasadniczo osiągana przez ciężar. Niektóre rodzaje elementów betonowych są w stanie osiągnąć wysoki stopień zazębienia, co przyczynia się do stabilności poprzez utrudnianie usuwania pojedynczej jednostki. Siły, które jednostka pancerna musi wytrzymać pod wpływem działania fal, zależą od hydrodynamiki na stoku falochronu, która jest niezwykle złożona ze względu na łamanie się fal i porowatą naturę konstrukcji. Do tej pory nie udało się uzyskać szczegółowego opisu przepływu i nie jest jasne, czy uda się to zrobić w przyszłości, biorąc pod uwagę występujące zjawiska turbulentne. Dlatego też natychmiastowa siła wywierana na jednostkę pancerną nie jest, przynajmniej na razie, możliwa do określenia za pomocą numerycznego modelu przepływu. Z tego powodu formuły empiryczne są stosowane w projektowaniu kopców gruzowych, skalibrowane na podstawie testów laboratoryjnych konstrukcji modelowych. Jednak formuły te nie mogą uwzględniać wszystkich aspektów wpływających na stabilność, głównie dlatego, że inherentna złożoność problemu nie nadaje się do prostego rozwiązania. W związku z tym formuły empiryczne są stosowane jako narzędzie wstępnego projektowania, a testy modelu fizycznego w korycie falowym konkretnego projektu w stosownych warunkach klimatu morskiego są rygorystyczne, z wyjątkiem mniejszych konstrukcji. Testy modelu fizycznego naturalnie integrują całą złożoność problemu. Ich wadą jest to, że są drogie i czasochłonne. W tym artykule sztuczne sieci neuronowe są trenowane i testowane za pomocą wyników testów stabilności przeprowadzonych na modelowym falochronie. Wykazano, że odtwarzają one bardzo dokładnie zachowanie modelu fizycznego w kanale falowym. Tak więc model ANN, jeśli jest trenowany i testowany z wystarczającą ilością danych, może być używany zamiast testów modelu fizycznego. Wirtualne laboratorium tego rodzaju pozwoli zaoszczędzić czas i pieniądze w porównaniu z konwencjonalną procedurą.
TŁO
Sztuczne sieci neuronowe są używane w zastosowaniach inżynierii lądowej od jakiegoś czasu, szczególnie w hydrologii ; niektóre zagadnienia inżynierii oceanicznej zostały również podjęte. Stabilność falochronu z gruzu kamiennego jest badana w pionierskiej pracy Mase , skupiającej się na konkretnym wzorze stabilności. Medina i inni trenują i testują sztuczną sieć neuronową przy użyciu danych dotyczących stabilności z sześciu laboratoriów. Dane wejściowe to względna wysokość fali, liczba Iribarrena i zmienna reprezentująca laboratorium. Kim i Park (2005) porównują różne modele ANN w analizie obracającej się wokół jednego empirycznego wzoru stabilności, podobnie jak Mase. Yagci i inni stosują różne rodzaje sieci neuronowych i logiki rozmytej, charakteryzując fale na podstawie ich wysokości, okresu i stromości.
MODEL FIZYCZNY I MODEL ANN
Sztuczne sieci neuronowe zostały wytrenowane i przetestowane na podstawie testów laboratoryjnych przeprowadzonych w korycie falowym laboratorium CITEEC na Uniwersytecie La Coru?a. Sekcja koryta ma 4 m szerokości i 0,8 m wysokości, a długość 33 m . Fale są generowane za pomocą łopatki tłokowej, sterowanej przez system aktywnej absorpcji (AWACS), który zapewnia, że fale odbite od modelu są pochłaniane przez łopatkę. Model przedstawia typowy falochron z trzech warstw gruzowiska na głębokości 15 m, zwieńczony na +9,00 m, w skali 1:30. Jego nachylenia wynoszą odpowiednio 1:1,50 i 1:1,25 po stronie morskiej i zawietrznej. Warstwa pancerza składa się z kolei z dwóch warstw kamieni o wadze W=69 g ±10%; te w górnej warstwie są pomalowane na niebiesko, czerwono i czarno zgodnie z poziomymi pasami, podczas gdy te w dolnej warstwie są pomalowane na biało, aby łatwo zidentyfikować po teście uszkodzone obszary, tj. obszary, w których górna warstwa została usunięta. Warstwa filtrująca składa się ze żwiru o medianie wielkości D50 = 15,11 mm i grubości 4 cm. Wreszcie rdzeń składa się z drobniejszego żwiru o D50 = 6,95 mm, D15 = 5,45 mm i D85 = 8,73 mm i porowatości n = 42%. Gęstość kamieni i żwiru wynosi ?r = 2700 kg/m3. Fale mierzono na sześciu różnych stacjach wzdłuż osi podłużnej lub osi x kanału. Przy początku x znajdującym się w położeniu spoczynkowym łopatki falowej, pierwszy falomierz, S1, znajdował się na x = 7,98 m. Grupa trzech czujników, S2, S3 i S4, została użyta do oddzielenia fali padającej i odbitej. Centralny falomierz, S3, został umieszczony na x=12,28 m, podczas gdy położenie pozostałych, S2 i S4, było zmieniane w zależności od okresu generowania fali każdego testu (Tabela 1). Inny falomierz, S5, został umieszczony 25 cm przed stopą falochronu modelowego, na x=13,47 m i 16 cm na prawo (patrząc z łopatki falochronu) od środkowej linii kanału, aby nie zakłócać nagrywania wideo testów. Na koniec falomierz (S6) został umieszczony na zawietrznej falochronu modelowego, na x=18,09 m. W testach stabilności użyto zarówno fal regularnych, jak i nieregularnych. Niniejszy artykuł dotyczy ośmiu testów fal regularnych, przeprowadzonych z czterema różnymi okresami fal. Głębokość wody w kanale była utrzymywana na stałym poziomie przez cały czas trwania testów (h=0,5 m). Każdy test składał się z szeregu przebiegów falowych o stałej wartości okresu fali T, powiązanej z liczbą falową k za pomocą
T = 2π[gktanh(kh)]1/2
gdzie g jest przyspieszeniem grawitacyjnym. Każdy przebieg fal składał się z 200 fal. W pierwszym przebiegu każdego testu wygenerowane fale miały wysokość modelu H=6 cm (odpowiadającą wysokości fali w prototypie Hp=1,80 m); w kolejnych przebiegach wysokość fali zwiększano o 1 cm (7 cm, 8 cm, 9 cm itd.), tak aby falochron modelowy był poddawany coraz bardziej energicznym falom. Cztery poziomy uszkodzeń zostały użyte do scharakteryzowania sytuacji stabilności falochronu modelowego po każdym przebiegu fali:
(0) Brak uszkodzeń. Żadne jednostki pancerne nie zostały przesunięte ze swoich pozycji.
(1) Inicjacja uszkodzeń. Pięć lub więcej jednostek pancernych zostało przemieszczonych.
(2) Uszkodzenia Iribarren. Przemieszczone jednostki pierwszej (zewnętrznej) warstwy pancerza pozostawiły odkryty obszar drugiej warstwy wystarczająco duży, aby fale mogły usunąć kamień.
(3) Rozpoczęcie zniszczenia. Pierwsza jednostka drugiej warstwy pancerza została usunięta przez działanie fal.
W miarę zwiększania wysokości fali w trakcie testu poziom uszkodzeń również wzrósł z początkowego "braku uszkodzeń" do "rozpoczęcia uszkodzenia", "uszkodzenia Iribarren" i ostatecznie "rozpoczęcia zniszczenia", w którym to momencie test został zakończony, a model przebudowany na potrzeby kolejnego testu. Liczba przebiegów fal w teście wahała się od 10 do 14. Powyższe poziomy uszkodzeń zapewniają dobrą półilościową ocenę stanu stabilności falochronu. Jednak następujący bezwymiarowy parametr uszkodzenia jest bardziej odpowiedni dla modelu sztucznej sieci neuronowej:
S=nD50/(1-p)b
gdzie D50 jest medianą wielkości kamieni pancerza, p jest porowatością warstwy pancerza, b jest szerokością falochronu modelowego, a n jest liczbą jednostek przemieszczonych po każdym przejściu fali. W tym przypadku D50 = 2,95 cm, p = 0,40 i b = 50 cm. Wysokość fali padającej została bezwymiarowa za pomocą wysokości fali o zerowym uszkodzeniu formuły SPM (1984),
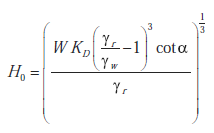
gdzie KD=4 to współczynnik stateczności, γw=1000 kg/m3 to gęstość wody (w testach laboratoryjnych zastosowano wodę słodką), a a to nachylenie falochronu. Przy tych wartościach H0 = 9,1 cm. Bezwymiarowa wysokość fali padającej jest podana przez
H* = H/H0
gdzie H oznacza wysokość fali padającej. Większość poprzednich zastosowań Sztucznych Sieci Neuronowych w Inżynierii Lądowej wykorzystuje wielowarstwowe sieci sprzężenia zwrotnego trenowane za pomocą algorytmu propagacji wstecznej, które również zostaną wykorzystane w tym badaniu; ich główną zaletą są ich zdolności generalizacyjne. Tak więc tego rodzaju sieci można użyć na przykład do przewidywania uszkodzeń pancerza, jakie model falochronu wytrzyma w określonych warunkach, nawet jeśli warunki te nie były dokładnie częścią zestawu danych, na którym trenowano sieć. Jednak parametry opisujące warunki (np. gr., wysokość fali i okres) muszą mieścić się w zakresach parametrów testów stabilności, na których trenowano sieć neuronową. W tym przypadku wyniki testów stabilności modelu falochronu z gruzowiska opisanego powyżej zostały wykorzystane do trenowania i testowania sztucznej sieci neuronowej. Osiem testów stabilności obejmowało 96 przebiegów fal. Dane wejściowe do sieci stanowiła bezwymiarowa wysokość fali (H*) i względna głębokość wody (kh) przebiegu fali, a dane wyjściowe - wynikowy bezwymiarowy parametr uszkodzenia (S). Dane z 49 przebiegów fal, odpowiadające czterem testom stabilności T20, T21, T22 i T23, zostały wykorzystane do trenowania sieci; podczas gdy dane z 46 przebiegów fal, odnoszące się do pozostałych czterech testów (T10, T11, T12 i T13) zostały wykorzystane do jej testowania. Ten rozkład danych zapewnił, że każdy z czterech okresów generowania fali był obecny zarówno w zestawach danych treningowych, jak i testowych. Najpierw sztuczna sieć neuronowa z 10 neuronami sigmoidalnymi w warstwie ukrytej i liniowej warstwie wyjściowej została wytrenowana i przetestowana 10 razy. Sieć neuronowa została wytrenowana za pomocą metody regularizacji bayesowskiej , o której wiadomo, że jest skuteczna w unikaniu nadmiernego dopasowania. Średnie wartości MSE wyniosły 0,2880 przy uwzględnieniu wszystkich danych, 0,2224 dla zestawu danych treningowych i 0,3593 dla zestawu danych testowych. Odchylenia standardowe wartości MSE wyniosły 5,9651x10-10, 9,0962x10-10 i 7,7356x10-10 odpowiednio dla całego zestawu danych, zestawu danych treningowych i zestawu danych testowych. Zwiększenie liczby jednostek neuronowych w warstwie ukrytej do 15 nie spowodowało żadnej znaczącej poprawy średnich wartości MSE (odpowiednio 0,2879, 0,2222 i 0,3593 dla wszystkich danych, zestawu danych treningowych i zestawu danych testowych), więc zachowano poprzednią sztuczną sieć neuronową z 10 neuronami w warstwie ukrytej. Poniższe wyniki odpowiadają przebiegowi treningowemu i testowemu tej sieci neuronowej z globalnym MSE wynoszącym 0,2513. Analiza regresji liniowej wskazuje, że dane sieci neuronowej bardzo dobrze pasują do danych eksperymentalnych w całym zakresie bezwymiarowego parametru uszkodzenia S. W efekcie współczynnik korelacji wynosi 0,983, a równanie najlepszego dopasowania liniowego, y = 0,938x ? 0,00229, jest bardzo zbliżone do równania linii przekątnej y = x . Wyniki uzyskane z zestawem danych treningowych (testy stabilności T20, T21, T22 i T23) wykazują doskonałą zgodność między modelem sieci neuronowej a modelem fizycznym. W trzech z czterech testów (T20, T22 i T23) dane sieci neuronowej naśladują pomiary na falochronie modelu niemal do perfekcji. W teście T21 model fizyczny doświadcza gwałtownego wzrostu poziomu uszkodzeń przy H* = 1,65, który jest lekko łagodzony przez model ANN. Wartość MSE wynosi 0,1441. Zestaw danych testowych obejmował również cztery testy stabilności (T10, T11, T12 i T13). Wrodzona trudność problemu jest widoczna w teście T11 , w którym bezwymiarowy parametr uszkodzeń (S) nie wzrasta w przebiegu fali przy H* = 1,54, ale nagle wzrasta o około 100% w następnym przebiegu fali przy H* = 1,65. Takie różnice między przebiegami fal są praktycznie niemożliwe do uchwycenia przez model ANN, biorąc pod uwagę, że dane wejściowe do modelu ANN albo zmieniają się tylko nieznacznie, w tym przypadku o mniej niż 7% (bezwymiarowa wysokość fali, H*), albo wcale się nie zmieniają (względna głębokość wody, kh). Należy pamiętać, że podczas obliczania uszkodzeń po danym przebiegu fali, sieć neuronowa ANN nie ma żadnych informacji o poziomie uszkodzeń przed przebiegiem fali, w przeciwieństwie do modelu fizycznego. Mimo to sieć neuronowa ANN działa dobrze, dając wartość MSE równą 0,3678 z zestawem danych testowych.
TRENDY NA PRZYSZŁOŚĆ
W tym badaniu wykorzystano wyniki testów stabilności przeprowadzonych na regularnych falach. Testy fal nieregularnych powinny być również analizowane za pomocą sztucznej inteligencji, a autorzy zamierzają to zrobić w przyszłości. Charakterystyka falochronu to kolejny ważny aspekt problemu. Sieć neuronowa ANN nie może ekstrapolować poza zakresy charakterystyk fal i falochronu, na których została wytrenowana. Testy stabilności wykorzystane w tym badaniu uwzględniały jeden model falochronu; należy przeprowadzić dalsze testy obejmujące modele fizyczne z innymi geometriami i materiałami. Po udowodnieniu potencjału sztucznych sieci neuronowych do modelowania zachowania falochronu z gruzowiska poddanego działaniu fal, można zbudować wirtualne laboratorium z wynikami tych testów.
WNIOSEK
Niniejszy artykuł pokazuje, że sztuczne sieci neuronowe są w stanie modelować zachowanie się falochronu z gruzu kamiennego w obliczu fal energetycznych. Jest to bardzo złożony problem z wielu powodów. Po pierwsze, hydrodynamika fal łamiących się na zboczu nie jest dobrze znana, tak bardzo, że szczegółowa charakterystyka ruchów cząstek wody nie jest możliwa w chwili obecnej i może pozostać taka w przyszłości ze względu na chaotyczną naturę zaangażowanych procesów. Po drugie, w przypadku falochronu z gruzu kamiennego problem jest dodatkowo złożony z powodu porowatej natury struktury, która powoduje złożoną interakcję fala-struktura, w której strumień energii przenoszony przez falę padającą jest rozprowadzany na następujące procesy: (i) odbicie fali; (ii) łamanie fali na zboczu; (iii) transmisja fali przez porowate medium; i (iv) rozpraszanie. Subtelna interakcja między wszystkimi tymi procesami oznacza, że nie można badać żadnego z nich bez uwzględnienia pozostałych. Po trzecie, samo porowate medium ma charakter stochastyczny: nie można powiedzieć, że dwa falochrony z gruzowiska są identyczne. Ta złożoność uniemożliwiała do tej pory opracowanie modelu numerycznego, który mógłby wiarygodnie analizować siły działające na jednostki warstwy pancerza, a tym samym sytuację stabilności falochronu. W konsekwencji testy modelu fizycznego są koniecznością, gdy przewiduje się dużą strukturę z gruzowiska. Pomimo trudności problemu, wykazano, że sztuczna sieć neuronowa użyta w tej pracy odtwarza bardzo dokładnie wyniki modelu fizycznego. Tak więc sztuczna sieć neuronowa może stanowić, po odpowiednim przeszkoleniu i walidacji, wirtualne laboratorium. Testowanie falochronu w tym wirtualnym laboratorium jest znacznie szybsze i znacznie tańsze niż testowanie fizycznego modelu tej samej struktury w laboratoryjnym korycie falowym.
Sztuczna inteligencja w wyszukiwaniu informacji
WSTĘP
W tym artykule opisano najbardziej znane podejścia do stosowania technologii sztucznej inteligencji w wyszukiwaniu informacji (IR). Wyszukiwanie informacji jest kluczową technologią w zarządzaniu wiedzą. Zajmuje się wyszukiwaniem informacji oraz reprezentacją, przechowywaniem i organizacją wiedzy. Wyszukiwanie informacji dotyczy procesów wyszukiwania, w których użytkownik musi zidentyfikować podzbiór informacji, który jest istotny dla jego potrzeb informacyjnych w ramach dużej ilości wiedzy. Poszukujący informacji formułuje zapytanie, próbując opisać swoje potrzeby informacyjne. Zapytanie jest porównywane z reprezentacjami dokumentów, które zostały wyodrębnione podczas fazy indeksowania. Reprezentacje dokumentów i zapytań są zazwyczaj dopasowywane przez funkcję podobieństwa, taką jak cosinus. Najbardziej podobne dokumenty są prezentowane użytkownikom, którzy mogą ocenić istotność w odniesieniu do swojego problemu (Belkin, 2000). Problem prawidłowego reprezentowania dokumentów i dopasowywania niedokładnych reprezentacji wkrótce doprowadził do zastosowania technik opracowanych w ramach sztucznej inteligencji do wyszukiwania informacji.
KONTEKST
Na początku informatyki wyszukiwanie informacji (IR) i sztuczna inteligencja (AI) rozwijały się równolegle. W latach 80. XX wieku zaczęły ze sobą współpracować, a termin inteligentne wyszukiwanie informacji został ukuty dla zastosowań AI w IR. W latach 90. XX wieku wyszukiwanie informacji przeszło od modeli wyszukiwania boolowskiego opartych na zbiorach do systemów rankingowych, takich jak model przestrzeni wektorowej i podejścia probabilistyczne. Te przybliżone systemy wnioskowania otworzyły drzwi dla bardziej inteligentnych komponentów o wartości dodanej. Duża liczba dokumentów tekstowych dostępnych w profesjonalnych bazach danych i w Internecie doprowadziła do zapotrzebowania na inteligentne metody wyszukiwania tekstu i do znacznych badań w tej dziedzinie. Potrzeba lepszego wstępnego przetwarzania w celu wyodrębnienia większej wiedzy z danych stała się ważnym sposobem na ulepszenie systemów. Gotowe podejścia obiecują gorsze wyniki niż systemy dostosowane do użytkowników, domeny i potrzeb informacyjnych. Obecnie większość technik opracowanych w AI została zastosowana w systemach wyszukiwania z większym lub mniejszym powodzeniem. Gdy dostępne są dane od użytkowników, systemy często wykorzystują uczenie maszynowe w celu optymalizacji swoich wyników.
Metody sztucznej inteligencji w wyszukiwaniu informacji
Metody sztucznej inteligencji są stosowane w całym standardowym procesie wyszukiwania informacji i w przypadku nowych usług o wartości dodanej. Pierwsza sekcja zawiera krótki przegląd wyszukiwania informacji. Następne sekcje są zorganizowane wzdłuż etapów procesu wyszukiwania i podają przykłady zastosowań.
Wyszukiwanie informacji
Wyszukiwanie informacji zajmuje się przechowywaniem i reprezentacją wiedzy oraz wyszukiwaniem informacji istotnych dla konkretnego problemu użytkownika. Poszukujący informacji formułuje zapytanie, próbując opisać swoje potrzeby informacyjne. Zapytanie jest porównywane z reprezentacjami dokumentów. Reprezentacje dokumentów i zapytań są zazwyczaj dopasowywane za pomocą funkcji podobieństwa, takiej jak współczynnik cosinusa lub Dice′a. Najbardziej podobne dokumenty są prezentowane użytkownikom, którzy mogą ocenić ich trafność w odniesieniu do swojego problemu. Indeksowanie zazwyczaj składa się z kilku faz. Po segmentacji słów usuwane są słowa pomijane. Te powszechne słowa, takie jak artykuły lub przyimki, same w sobie zawierają niewiele znaczenia i są ignorowane w reprezentacji dokumentu. Po drugie, formy słów są przekształcane w ich podstawową formę, rdzeń. Podczas fazy rdzeniowania, np. domy byłyby przekształcane w dom. W przypadku reprezentacji dokumentu różne formy słów zwykle nie są konieczne. Znaczenie słowa dla dokumentu może być różne. Niektóre słowa lepiej opisują treść dokumentu niż inne. Ta waga jest określana przez częstotliwość występowania tematu w tekście dokumentu. W wyszukiwaniu multimediów kontekst jest niezbędny do wyboru formy zapytania i reprezentacji dokumentu. Różne reprezentacje mediów mogą być dopasowywane do siebie lub mogą być konieczne transformacje (np. dopasowywanie terminów do obrazów lub wypowiedzi mówionych do dokumentów w tekście pisanym). Ponieważ wyszukiwanie informacji musi radzić sobie z niejasną wiedzą, dokładne metody przetwarzania nie są odpowiednie. Bardziej odpowiednie są niejasne modele wyszukiwania, takie jak model probabilistyczny. W ramach tych modeli terminy są dostarczane z wagami odpowiadającymi ich znaczeniu dla dokumentu. Te wagi odzwierciedlają różne poziomy istotności. Wynikiem obecnych systemów wyszukiwania informacji są zazwyczaj posortowane listy dokumentów, w których najlepsze wyniki są bardziej prawdopodobne, że będą istotne według systemu. W niektórych podejściach użytkownik może ocenić zwrócone mu dokumenty i powiedzieć systemom, które z nich są dla niego istotne. Następnie system sortuje zestaw wyników. Dokumenty, które zawierają wiele słów obecnych w odpowiednich dokumentach, są wyżej klasyfikowane. Wiadomo, że ten proces sprzężenia zwrotnego istotności znacznie poprawia wydajność. Sprzężenie zwrotne istotności jest również interesującym zastosowaniem uczenia maszynowego. Na podstawie decyzji człowieka, krok optymalizacji można modelować za pomocą kilku podejść, np. z przybliżonymi zestawami. W środowiskach internetowych kliknięcie jest często interpretowane jako niejawny pozytywny osąd istotności.
Zaawansowane modele reprezentacji
Aby reprezentować dokumenty w języku naturalnym, należy przeanalizować ich zawartość. Jest to trudne zadanie dla systemów komputerowych. Solidna analiza semantyczna dla dużych zbiorów tekstów lub nawet obiektów multimedialnych nie została jeszcze opracowana. Dlatego dokumenty tekstowe są reprezentowane przez terminy języka naturalnego głównie bez kontekstu składniowego lub semantycznego. Jest to często określane jako podejście bag-of-words. Te słowa kluczowe lub terminy mogą tylko niedoskonale reprezentować obiekt, ponieważ ich kontekst i relacje z innymi terminami są tracone. Jednak poczyniono duże postępy, a systemy analizy semantycznej stają się konkurencyjne. Zaawansowana analiza składniowa i semantyczna do solidnego przetwarzania danych masowych została wyprowadzona z lingwistyki obliczeniowej. W przypadku wiedzy specyficznej dla aplikacji i domeny, stosuje się inne podejście w celu ulepszenia reprezentacji dokumentów. Schemat reprezentacji jest wzbogacany poprzez wykorzystanie wiedzy o koncepcjach domeny
Dopasowanie między zapytaniem a dokumentem
Po wyprowadzeniu reprezentacji kluczowym aspektem systemu wyszukiwania informacji jest obliczenie podobieństwa między zapytaniem a reprezentacją dokumentu. Większość systemów wykorzystuje matematyczne funkcje podobieństwa, takie jak cosinus. Decyzja dotycząca konkretnej funkcji opiera się na heurystyce lub ocenach empirycznych. Kilka podejść wykorzystuje uczenie maszynowe do długoterminowej optymalizacji dopasowania między terminem a dokumentem. Np. jedno podejście stosuje algorytm genetyczny w celu dostosowania funkcji ważenia do zbioru (Almeida i in., 2007). Sieci neuronowe były szeroko stosowane w IR. Do zadań wyszukiwania zastosowano kilka architektur sieciowych, najczęściej używane są tak zwane sieci aktywacji rozprzestrzeniania. Sieci aktywacji rozprzestrzeniania są prostymi sieciami w stylu Hopfielda, jednak nie wykorzystują reguły uczenia się sieci Hopfielda. Zazwyczaj składają się z dwóch warstw reprezentujących terminy i dokumenty. Wagi połączeń między warstwami są dwukierunkowe i początkowo ustawione zgodnie z wynikami tradycyjnych algorytmów indeksowania i ważenia. Neurony odpowiadające terminom zapytania użytkownika są aktywowane w warstwie terminów, a aktywacja rozprzestrzenia się wzdłuż wag do warstwy dokumentu i z powrotem. Aktywacja reprezentuje istotność lub zainteresowanie i dociera do potencjalnie istotnych terminów i dokumentów. Najbardziej aktywowane dokumenty są prezentowane użytkownikowi jako wynik. Dokładniejsze przyjrzenie się modelom ujawnia, że bardzo przypominają one tradycyjny model przestrzeni wektorowej wyszukiwania informacji. Dopiero po drugim kroku asocjacyjna natura procesu rozprzestrzeniania aktywacji prowadzi do wyników innych niż model przestrzeni wektorowej. Sieci rozprzestrzeniania aktywacji pomyślnie przetestowane przy użyciu danych masowych nie wykorzystują tej asocjacyjnej właściwości. W niektórych systemach proces jest zatrzymywany po zaledwie jednym kroku z warstwy terminów do warstwy dokumentów, podczas gdy inne wykonują jeszcze jeden krok wstecz do warstwy terminów, aby ułatwić naukę. Zapytania w systemach wyszukiwania informacji są zwykle krótkie i zawierają niewiele słów. Dłuższe zapytania mają większe prawdopodobieństwo osiągnięcia dobrych wyników. W konsekwencji systemy próbują dodać dobre terminy do zapytania wprowadzonego przez użytkownika. Zastosowano kilka technik. Terminy te są pobierane z dokumentów o najwyższej randze lub używane są terminy podobne do oryginalnych. Inna technika polega na użyciu terminów z dokumentów z tej samej kategorii. W tym celu stosuje się algorytmy klasyfikacyjne z uczenia maszynowego. Analiza linków stosuje dobrze znane miary z analizy bibliometrycznej do sieci Web. Liczba linków wskazujących na stronę internetową jest używana jako wskaźnik jej jakości. PageRank przypisuje wartość autorytetu każdej stronie internetowej, która jest przede wszystkim funkcją jej linków zwrotnych. Ponadto zakłada, że linki ze stron o wysokim autorytecie powinny być wyżej ważone i powinny skutkować wyższym autorytetem dla strony odbierającej. Aby uwzględnić różne wartości, które każda strona musi rozdysponować, algorytm jest wykonywany iteracyjnie, aż wynik będzie zbieżny. Podejścia uczenia maszynowego uzupełniają analizę linków. Decyzje ludzi dotyczące jakości stron internetowych służą do określania cech projektowych tych stron, które są dobrymi wskaźnikami ich jakości. Modele uczenia maszynowego są stosowane do określania jakości stron, które nie zostały jeszcze ocenione. Uczenie się od użytkowników było ważną strategią ulepszania systemów. Oprócz treści, metody sztucznej inteligencji zostały wykorzystane do ulepszania interfejsu użytkownika.
Komponenty o wartości dodanej dla interfejsów użytkownika
Kilku badaczy wdrożyło systemy wyszukiwania informacji oparte na samoorganizującej się mapie Kohonena (SOM), modelu sieci neuronowej do nienadzorowanej klasyfikacji. Zapewniają one asocjacyjny interfejs użytkownika, w którym sąsiedztwo dokumentów wyraża relację semantyczną. Implementacje dla dużych zbiorów można testować w Internecie. SOM składa się z zazwyczaj dwuwymiarowej siatki neuronów, z których każdy jest powiązany z wektorem wag. Dokumenty wejściowe są klasyfikowane według podobieństwa między wzorcem wejściowym a wektorami wag, a algorytm dostosowuje wagi zwycięskiego neuronu i jego sąsiada. W ten sposób sąsiednie klastry mają duże podobieństwo. Aplikacje wyszukiwania informacji SOM klasyfikują dokumenty i przypisują dominujący termin jako nazwę klastra. W przypadku rzeczywistych zbiorów na dużą skalę jedna dwuwymiarowa siatka nie jest wystarczająca. Byłaby ona albo zbyt duża, albo każdy węzeł zawierałby w konsekwencji zbyt wiele dokumentów. Żadna z nich nie byłaby pomocna dla użytkowników, dlatego przyjęto architekturę warstwową. Najwyższa warstwa składa się z węzłów, które reprezentują klastry dokumentów. Dokumenty tych węzłów są ponownie analizowane przez SOM. Dla użytkownika system składa się z kilku dwuwymiarowych map terminów, w których podobne terminy znajdują się blisko siebie. Po wybraniu jednego węzła może on dotrzeć do innego dwuwymiarowego SOM. Paradygmat wyszukiwania informacji dla SOM polega na przeglądaniu i nawigowaniu między warstwami map. SOM wydaje się być bardzo naturalną wizualizacją. Jednak podejście SOM ma pewne poważne wady.
• Interfejs do interakcji z kilkoma warstwami map sprawia, że system jest trudny do przeglądania.
• Użytkownicy dużych zbiorów tekstów potrzebują przede wszystkim mechanizmów wyszukiwania, których sam SOM nie oferuje.
• Podobieństwo zbioru dokumentów jest zredukowane do dwóch wymiarów, pomijając wiele potencjalnie interesujących aspektów.
• SOM lepiej rozwija swoje zalety dla interakcji człowiek-komputer w przypadku małej liczby dokumentów. Bardzo zachęcającym zastosowaniem byłoby klasteryzacja zestawu wyników. Neurony zmieściłyby się na jednym ekranie, liczba wyrazów byłaby ograniczona, a zatem redukcja do dwóch wymiarów nie pominęłaby tak wielu aspektów.
Klasyfikacja i personalizacja użytkownika
Adaptacyjne podejścia do wyszukiwania informacji mają na celu dostosowanie wyników systemu do jednego użytkownika oraz jego zainteresowań i preferencji. Najpopularniejszy schemat reprezentacji opiera się na schemacie reprezentacji używanym w wyszukiwaniu informacji, w którym macierz dokumentu-terminu przechowuje ważność lub wagę każdego terminu dla każdego dokumentu. Gdy termin pojawia się w dokumencie, ta waga powinna być inna niż zero. Zainteresowanie użytkownika może być również przechowywane jak dokument. Wówczas zainteresowanie jest wektorem terminów. Mogą to być terminy, które użytkownik wprowadził lub wybrał w interfejsie użytkownika lub które system wyodrębnił z dokumentów, którymi użytkownik wykazał zainteresowanie, przeglądając je lub pobierając. Przykładem takiego systemu jest UCAIR, który można zainstalować jako wtyczkę do przeglądarki. UCAIR opiera się na standardowej wyszukiwarce internetowej w celu uzyskania wyniku wyszukiwania i podstawowego rankingu. Ten ranking jest obecnie modyfikowany przez ponowne klasyfikowanie dokumentów na podstawie niejawnych informacji zwrotnych i zapisanego profilu zainteresowań użytkownika. Większość systemów wykorzystuje tę metodę przechowywania zainteresowania użytkownika w wektorze terminów. Jednak ta metoda ma kilka wad. Profil zainteresowań może nie być stabilny, a użytkownik może mieć różnorodne rozbieżne zainteresowania pracą i wypoczynkiem, które są wymieszane w jednym profilu. Zaawansowane techniki indywidualizacji personalizują podstawowe funkcje systemu. Wyniki badań empirycznych wykazały, że sprzężenie zwrotne trafności jest skuteczną techniką poprawy jakości wyszukiwania. Metody uczenia się wyszukiwania informacji muszą rozszerzać zakres efektów sprzężenia zwrotnego trafności poza modyfikację zapytania, aby osiągnąć długoterminową adaptację do subiektywnego punktu widzenia użytkownika. Sama zmiana zapytania często skutkuje poprawą jakości; jednak informacje są tracone po bieżącej sesji. Niektóre systemy zmieniają reprezentację dokumentu zgodnie z informacją zwrotną trafności. W metaforze przestrzeni wektorowej odpowiednie dokumenty są przesuwane w kierunku reprezentacji zapytania. To podejście również obejmuje pewne problemy. Ponieważ tylko ułamek dokumentów jest objęty modyfikacjami, podstawowe dane z procesu indeksowania są zmieniane w nieco heterogeniczny stan. Oryginalny wynik indeksowania nie jest już dostępny. Z pewnością ta technika jest niewystarczająca w przypadku podejść fuzyjnych, w których łączy się kilka metod wyszukiwania. W tym przypadku kilka podstawowych reprezentacji musiałoby zostać zmienionych zgodnie z wpływem odpowiednich metod na odpowiednie dokumenty. Indeksy są zazwyczaj heterogeniczne, co często uważa się za zaletę podejść fuzyjnych. Konsekwencją byłoby duże przeciążenie obliczeniowe. Podejście MIMOR (Multiple Indexing and Method-Object Relations) nie polega na zmianach dokumentu ani reprezentacji zapytania podczas przetwarzania informacji zwrotnej o trafności w celu personalizacji. Zamiast tego koncentruje się na centralnym aspekcie funkcji wyszukiwania, obliczaniu podobieństwa między dokumentem a zapytaniem. Podobnie jak inne metody fuzji, MIMOR akceptuje wynik poszczególnych systemów wyszukiwania, jak z czarnej skrzynki. Wyniki te są łączone za pomocą kombinacji liniowej, która jest przechowywana podczas wielu sesji. Wagi systemów ulegają zmianie w wyniku uczenia się. Dostosowują się one zgodnie z informacjami zwrotnymi o trafności dostarczanymi przez użytkowników i tworzą długoterminowy model do wykorzystania w przyszłości. W ten sposób MIMOR uczy się, które systemy odniosły sukces w przeszłości
PRZYSZŁE TRENDY
Systemy wyszukiwania informacji są stosowane w coraz bardziej złożonych i zróżnicowanych środowiskach. Przeszukiwanie poczty e-mail, zbiorów społecznościowych i innych określonych domen stwarza nowe wyzwania, które prowadzą do innowacyjnych systemów. Te aplikacje wyszukiwania wymagają dokładnej i zorientowanej na użytkownika oceny. Nowe środki oceny i standaryzowane zbiory testów są niezbędne do uzyskania wiarygodnych wyników oceny. W adaptacji użytkownika systemy rekomendacji są ważnym trendem dla przyszłych ulepszeń. Systemy rekomendacji należy postrzegać w kontekście aplikacji społecznościowych. Twórcy systemów stają w obliczu wzrostu treści generowanych przez użytkowników, co umożliwia nowe metody rozumowania. Można się spodziewać, że nowe aplikacje, takie jak odpowiadanie na pytania, polegające na bardziej inteligentnym przetwarzaniu, zdobędą większy udział w rynku w niedalekiej przyszłości
WNIOSEK
Zarządzanie wiedzą ma ogromne znaczenie dla społeczeństwa informacyjnego. Dokumenty napisane w języku naturalnym zawierają znaczną część dostępnej wiedzy. W związku z tym wyszukiwanie ma kluczowe znaczenie dla sukcesu systemów zarządzania wiedzą. Technologie AI są szeroko stosowane w systemach wyszukiwania. Wykorzystanie wiedzy w bardziej efektywny sposób jest głównym obszarem badań. Ponadto zorientowane na użytkownika systemy wartości dodanej wymagają inteligentnego przetwarzania i uczenia maszynowego w wielu formach. Ważnym przyszłym trendem dla metod AI w IR będzie adaptacja metod wyszukiwania do kontekstu. Uczenie maszynowe można stosować w celu znalezienia zoptymalizowanych funkcji dla kolekcji lub zapytań.
Sztuczna inteligencja w komputerowo wspomaganej diagnostyce
WSTĘP
Specjaliści z dziedziny radiologii medycznej są bezpośrednio zależni od procesu podejmowania decyzji w swoich codziennych czynnościach. Proces ten opiera się głównie na analizie dużej ilości informacji uzyskanych w celu oceny obrazów radiograficznych. Niektóre badania wykazują dużą pojemność sztucznych sieci neuronowych (ANN) w systemach wspomagających diagnostykę, głównie w zastosowaniach jako klasyfikacja wzorców. Celem tego artykułu jest przedstawienie rozwoju systemu opartego na ANN, weryfikującego jego zachowanie jako narzędzia ekstrakcji cech i redukcji wymiarowości, do rozpoznawania i charakteryzowania wzorców, do późniejszej klasyfikacji wzorców normalnych i nieprawidłowych.
KONTEKST
Diagnostyka wspomagana komputerowo (CAD) jest uważana za jeden z głównych obszarów badań obrazów medycznych i diagnostyki radiologicznej. Według Gigera "W przyszłości prawdopodobne jest, że wszystkie obrazy medyczne będą miały jakąś formę wykonanej CAD, aby skorzystać na wynikach i opiece nad pacjentem". Diagnoza radiologa jest zazwyczaj oparta na jakościowej interpretacji analizowanych danych, na które może wpływać i być szkodliwa przez wiele czynników, takich jak niska jakość obrazu, zmęczenie wzroku, rozproszenie, nakładanie się struktur, między innymi. Ponadto ludzie mają ograniczenia w zdolnościach wzrokowych, co może utrudniać analizę obrazu medycznego, głównie w wykrywaniu określonych prezentowanych wzorców . Badania wykazują, że gdy analiza jest przeprowadzana przez dwóch radiologów, czułość diagnozy znacznie wzrasta. W tym kierunku CAD może być używany jako drugi specjalista, gdy dostarcza komputerowi odpowiedź jako drugą opinię. Wiele prac analizuje wydajność radiologa przed wykorzystaniem systemów CAD, od których oddzielamy badania Jiang i iinni oraz Fenton i inni. W rozwoju systemów CAD zwykle stosuje się techniki z dwóch obszarów obliczeniowych: Computer Vision i Artificial Intelligence. Z obszaru Computer Vision stosuje się techniki przetwarzania obrazu w celu ulepszenia, segmentacji i ekstrakcji cech. Celem ulepszenia jest poprawa obrazu, aby uczynić go bardziej odpowiednim dla konkretnego zastosowania. W zastosowaniach z cyfrowymi obrazami medycznymi, ulepszenie jest ważne, aby ułatwić analizę wizualną ze strony specjalisty. Segmentacja to etap, w którym obraz jest dzielony na części lub obiekty składowe . Wynikiem segmentacji jest zbiór obiektów, które można analizować i kwantyfikować indywidualnie, reprezentując określone cechy oryginalnego obrazu. Ostatnim etapem przetwarzania obrazu jest ekstrakcja cech, która zasadniczo obejmuje kwantyfikowanie elementów, które składają się na segmentowane obiekty oryginalnego obrazu, takie jak rozmiar, kontrast i forma. Po zakończeniu tej pierwszej części skwantyfikowane atrybuty są wykorzystywane do klasyfikacji struktur zidentyfikowanych na obrazie, zwykle przy użyciu metod sztucznej inteligencji. Według Kononenko wykorzystanie sztucznej inteligencji we wsparciu diagnozy jest wydajne, umożliwiając złożoną analizę danych o prostej i bezpośredniej formie. Wiele metod i technik sztucznej inteligencji można zastosować na tym etapie, zwykle w celu zidentyfikowania i oddzielenia wzorców na odrębne grupy, na przykład wzorce normalne i nieprawidłowe. Według Kahna Jr (1994) wśród głównych technik można wymienić: rozumowanie oparte na regułach, sztuczne sieci neuronowe, sieci bayesowskie, rozumowanie oparte na przypadkach. Do nich można dodać metody statystyczne, algorytmy genetyczne i drzewa decyzyjne. Problemem, który dotyka większości zastosowań rozpoznawania wzorców, jest wymiarowość danych. Wymiarowość jest związana z liczbą atrybutów, które reprezentują wzorzec, czyli wymiarem przestrzeni wyszukiwania. Gdy przestrzeń ta zawiera tylko najbardziej istotne atrybuty, proces klasyfikacji jest szybszy i zużywa niewiele zasobów przetwarzania , a także pozwala na większą precyzję klasyfikatora. W problemach przetwarzania obrazów medycznych akcentowane jest znaczenie redukcji wymiarowości; dlatego normalnie obrazy, które mają być przetwarzane, składają się z bardzo dużej liczby pikseli, używanych jako podstawowe atrybuty w klasyfikacji. Ekstrakcja cech jest powszechnym podejściem do przeprowadzenia redukcji wymiarowości. Ogólnie rzecz biorąc, algorytm ekstrakcji tworzy nowy zestaw atrybutów z przekształceń lub kombinacji oryginalnego zestawu. Niektóre metody są badane w celu promowania ekstrakcji cech, a w konsekwencji redukcji wymiarowości, takie jak metody statystyczne, metody oparte na teorii sygnałów i sztuczne sieci neuronowe. Jako przykład wykorzystania sztucznych sieci neuronowych we wsparciu diagnostyki medycznej możemy przytoczyć badania Papadopoulosa i inni oraz André & Rangayan (2006).
GŁÓWNY TEMAT ARTYKUŁU
W tym artykule przedstawiamy również propozycję wykorzystania sztucznej inteligencji na etapie ekstrakcji cech, zastępując tradycyjne techniki przetwarzania obrazu. Tradycyjnie ekstrakcja cech jest przeprowadzana na podstawie technik statystycznych lub spektralnych, które skutkują na przykład teksturą lub atrybutami geometrycznymi. Po uzyskaniu tych atrybutów techniki sztucznej inteligencji są stosowane w klasyfikacji wzorców. Nasza propozycja to wykorzystanie ANN również do ekstrakcji cech.
Ekstrakcja cech za pomocą ANN
Ekstrakcja cech za pomocą sztucznych sieci neuronowych działa zasadniczo jako wybór cech, które reprezentują oryginalny zestaw danych. Ten wybór cech jest związany z procesem, w którym zestaw danych jest przekształcany w przestrzeń cech, która teoretycznie dokładnie opisuje te same informacje, co oryginalna przestrzeń danych. Jednak transformacja jest projektowana w taki sposób, że zestaw danych jest reprezentowany przez zredukowaną efektywną cechę, zachowując większość wewnętrznych informacji danych, to znaczy oryginalny zestaw danych cierpi na znaczną redukcję wymiarowości. Redukcja wymiarowości jest niezwykle użyteczna w aplikacjach, które obejmują przetwarzanie obrazu cyfrowego, które zazwyczaj zależą od bardzo dużej liczby punktów danych do manipulowania. Podsumowując, ekstrakcja cech za pomocą sieci neuronowych przekształca oryginalny zestaw pikseli w mapę o zmniejszonych wymiarach, która reprezentuje oryginalny obraz bez znaczącej utraty informacji. Do tej funkcji zazwyczaj stosuje się samoorganizujące się sieci neuronowe, takie jak na przykład samoorganizująca się mapa Kohonena (SOM). Samoorganizująca się mapa wyszukuje sposoby przekształcenia jednego określonego wzoru w dwuwymiarową mapę, zgodnie z pewnym porządkiem topologicznym. Elementy tworzące mapę są rozmieszczone w jednej warstwie, tworząc siatkę
Wszystkie elementy siatki odbierają sygnał wejściowy wszystkich zmiennych, powiązanych z ich odpowiednimi wagami. Obliczenie jego wartości wyjściowej jest przeprowadzane przez jedną określoną funkcję, na podstawie wag połączeń, i służy do identyfikacji zwycięskiego elementu. Matematycznie każdy element siatki jest reprezentowany przez wektor złożony z wag połączeń, o tym samym wymiarze przestrzeni wejściowej, to znaczy, że liczba elementów tworzących wektor odpowiada liczbie zmiennych wejściowych problemu.
Metodologia
Jako przykład zastosowania opracowano samoorganizującą się sieć neuronową do ekstrakcji cech obrazów radiogramów klatki piersiowej, obiektywizującą charakterystykę wzorców prawidłowych i nieprawidłowych. Każdy oryginalny obraz został podzielony na 12 części, mając za podstawę podział anatomiczny zwykle stosowany w diagnostyce radiologa. Każda część składa się z około 250 000 pikseli. Przy użyciu proponowanej samouczącej się sieci uzyskano redukcję tylko dla 240 reprezentatywnych elementów, z zadowalającymi wynikami w końcowej klasyfikacji wzorca.
PRZYSZŁE TRENDY
Opracowane badanie pokazuje możliwości zastosowania samouczących się sieci w ekstrakcji cech i redukcji wymiarowości; jednak w tym celu można również wykorzystać inne typy sieci neuronowych. Należy przeprowadzić nowe badania w celu porównania wyników i adekwatności metodologii.
WNIOSEK
Wkład technologii informacyjnej jest niezaprzeczalny jako narzędzie wspomagające podejmowanie decyzji medycznych. Sztuczna inteligencja przedstawia się jako świetne źródło ważnych technik, które należy wykorzystać w tym kierunku. Można udowodnić, że technika sztucznych sieci neuronowych podkreśla swoją dużą wszechstronność i solidność, zapewniając wystarczająco zadowalające wyniki, gdy jest dobrze stosowana i wdrażana. Wykorzystanie automatycznego systemu analizy obrazu może pomóc radiologowi, gdy jest używany jako narzędzie "drugiej opinii" lub drugiego odczytu, w analizie możliwych niedokładnych przypadków. Obserwuje się również, że wykorzystanie proponowanej metodologii stanowi znaczący zysk w przetwarzaniu obrazu radiogramów klatki piersiowej ze względu na jej szczególne cechy.
Sztuczne sieci neuronowe i modelowanie poznawcze
WSTĘP
W czasach swojej świetności sztuczne sieci neuronowe obiecywały radykalnie nowe podejście do modelowania poznawczego. Podejście koneksjonistyczne dało początek wielu wpływowym i kontrowersyjnym modelom poznawczym. W tym artykule rozważamy główne cechy podejścia, przyglądamy się czynnikom prowadzącym do jego entuzjastycznego przyjęcia i omawiamy, w jakim stopniu różni się ono od wcześniejszych modeli obliczeniowych. Koneksjonistyczne modele poznawcze wywarły znaczący wpływ na badanie umysłu. Jednak koneksjonizm nie jest już w szczytowym okresie. Zostaną zidentyfikowane możliwe powody spadku jego popularności, a także podjęta zostanie próba określenia jego prawdopodobnej przyszłości. Rozwój modeli koneksjonistycznych datuje się od publikacji w 1986 r. przez Rumelharta i McClellanda, zredagowanej pracy zawierającej zbiór koneksjonistycznych modeli poznania, z których każdy był trenowany przez ekspozycję na próbki wymaganych zadań. Te tomy wyznaczyły program dla koneksjonistycznych modelarzy poznawczych i zaoferowały metodologię, która następnie stała się standardem. Koneksjonistyczne modele poznawcze zostały od tego czasu opracowane w dziedzinach obejmujących wyszukiwanie pamięci i tworzenie kategorii, a także (w języku) rozpoznawanie fonemów, rozpoznawanie słów, percepcję mowy, nabytą dysleksję, nabywanie języka oraz (w wizji) wykrywanie krawędzi, rozpoznawanie obiektów i kształtów. Ponad dwadzieścia lat później wpływ tej pracy jest nadal widoczny.
KONTEKST
Model wymowy słów Seidenberga i McClellanda (1989) jest dobrze znanym przykładem koneksjonistycznym. Użyli oni propagacji wstecznej do wytrenowania trójwarstwowej sieci w celu odwzorowania reprezentacji ortograficznej słów i niesłów na rozproszoną reprezentację fonologiczną i reprezentację wyjściową ortograficzną. Twierdzi się, że model ten dobrze pasuje do danych eksperymentalnych pochodzących od ludzi. Ludzie mogą szybko podejmować decyzje, czy ciąg liter jest słowem, czy nie (w zadaniu decyzyjnym leksykalnym) i mogą łatwo wymawiać zarówno słowa, jak i niesłowa. Czas potrzebny na wykonanie obu czynności zależy od wielu czynników, w tym częstotliwości występowania słów w języku i regularności ich pisowni. Wytrenowana sztuczna sieć neuronowa wyprowadza zarówno reprezentację fonologiczną, jak i ortograficzną swojego wejścia. Reprezentacja fonologiczna jest traktowana jako równoważna wymawianiu słowa lub niesłowa. Reprezentacja ortograficzna i stopień, w jakim powiela ona oryginalne dane wejściowe, są uważane za równoważne zadaniu decyzji leksykalnej. Model czasu przeszłego również miał duży wpływ. Model ten odzwierciedla kilka aspektów uczenia się końcówek czasowników przez człowieka. Został wytrenowany na przykładach formy rdzenia słowa jako danych wejściowych i formy czasu przeszłego jako danych wyjściowych. Każde dane wejściowe i wyjściowe były reprezentowane jako zestaw kontekstowo zależnych cech fonologicznych, kodowanych i dekodowanych za pomocą stałej sieci kodera/dekodera. Celem modelu było symulowanie sekwencji przypominających etapy uczenia się czasu przeszłego, jakie wykazują ludzie. Małe dzieci najpierw poprawnie uczą się czasu przeszłego kilku czasowników, zarówno regularnych (np. looked), jak i nieregularnych (np. went lub came). Na etapie 2 często zachowują się tak, jakby wywnioskowały ogólną regułę tworzenia czasu przeszłego (dodając -ed do tematu czasownika). Często jednak nadmiernie uogólniają tę regułę i dodają -ed do czasowników nieregularnych (np. comed). Istnieje stopniowe przejście do etapu końcowego, w którym uczą się produkować poprawną formę czasu przeszłego zarówno regularnych, jak i wyjątków. W ten sposób ich wydajność wykazuje funkcję w kształcie litery U dla czasowników nieregularnych (na początku poprawne, potem często błędne, potem znowu poprawne). Model był trenowany etapami na 506 angielskich czasownikach. Najpierw trenowano go na 10 czasownikach o wysokiej częstotliwości (regularnych i nieregularnych). Następnie wprowadzono czasowniki o średniej częstotliwości (głównie regularne) i trenowano je przez szereg epok. Spadek wydajności czasowników nieregularnych nastąpił wkrótce po wprowadzeniu czasowników o średniej częstotliwości - spadek, po którym nastąpiła stopniowa poprawa, która przypominała krzywą w kształcie litery U występującą w wydajności człowieka.
MOCNE STRONY I OGRANICZENIA KONEKSYJNEGO MODELOWANIA POZNAWCZEGO
Opisane powyżej modele wykazują pięć typowych cech koneksjonistycznych modeli poznania: (i) dostarczają opisu, który jest powiązany i inspirowany operacjami mózgu; (ii) mogą być używane zarówno do modelowania procesów umysłowych, jak i do symulowania rzeczywistego zaangażowanego zachowania; (iii) mogą zapewnić "dobre dopasowanie" do danych z eksperymentów psychologicznych; (iv) model i jego dopasowanie do danych są osiągane bez wyraźnego programowania i (v) często dostarczają nowych opisów danych. Omawiamy te cechy po kolei. Po pierwsze, istnieje idea, że koneksjonistyczny model poznawczy jest inspirowany i powiązany ze sposobem, w jaki działa mózg. Koneksjonizm opiera się zarówno na domniemanym działaniu układu nerwowego, jak i na rozproszonym obliczeniu. Jednostki podobne do neuronów są połączone za pomocą ważonych połączeń w sposób przypominający połączenia synaptyczne między neuronami w mózgu. Te ważone połączenia przechwytują wiedzę o systemie; można je uzyskać analitycznie lub poprzez "trening" systemu
za pomocą powtarzających się prezentacji przykładów treningu wejścia-wyjścia. Duże zainteresowanie modelami koneksjonistycznymi poznania wynikało z tego, że oferowały one nowe wyjaśnienie sposobu, w jaki wiedza była reprezentowana w mózgu. Na przykład zachowanie modelu uczenia się czasu przeszłego można opisać w kategoriach przestrzegania reguł - ale jego podstawowy mechanizm nie zawiera żadnych wyraźnych reguł. Wiedza o tworzeniu czasu przeszłego jest rozłożona na wagi w sieci. Zainteresowanie obliczeniami przypominającymi mózg było podsycane przez rosnące niezadowolenie z klasycznego podejścia przetwarzania symbolicznego do modelowania umysłu i jego relacji z mózgiem. Chociaż teorie manipulacji symbolami mogłyby wyjaśnić wiele aspektów ludzkiego poznania, istniały obawy co do tego, w jaki sposób takie symbole mogłyby być nauczone i reprezentowane w mózgu. Funkcjonalizm wyraźnie nalegał, że szczegóły dotyczące tego, w jaki sposób inteligencja i rozumowanie były faktycznie wdrażane, są nieistotne. Obawy
dotyczące manipulacji bezsensownymi, nieuzasadnionymi symbolami są zilustrowane eksperymentem myślowym Searle′a "Chinese Room" (1980). Koneksjonizm, przeciwnie, oferował podejście oparte na uczeniu się, w niewielkim stopniu wykorzystywał symbole i był związany ze sposobem, w jaki działał mózg. Można argumentować, że jednym z głównych wkładów koneksjonizmu w badanie i rozumienie umysłu było opracowanie wspólnego słownictwa między osobami zainteresowanymi poznaniem a osobami zainteresowanymi badaniem mózgu. Druga i trzecia cecha odnoszą się do sposobu, w jaki sztuczne sieci neuronowe mogą zarówno zapewnić model procesu poznawczego, jak i symulować zadanie oraz zapewnić dobre dopasowanie do danych empirycznych. W psychologii poznawczej nacisk kładziono na budowanie modeli, które mogłyby uwzględniać wyniki empiryczne uzyskane na ludziach, ale które nie uwzględniały symulacji zadań eksperymentalnych. Z kolei w sztucznej inteligencji opracowano modele, które wykonywały zadania w sposób przypominający zachowanie człowieka, ale które w niewielkim stopniu uwzględniały szczegółowe dowody psychologiczne. Jednakże, podobnie jak w dwóch opisanych tutaj modelach, modele koneksjonistyczne symulowały wykonywanie zadań przez człowieka i były w stanie dopasować dane z badań psychologicznych. Czwartą cechą jest osiągnięcie modelu i dopasowanie do danych bez wyraźnego ręcznego programowania. Można to korzystnie porównać z metodologią programowania symbolicznego sztucznej inteligencji, w której model jest programowany krok po kroku, pozostawiając miejsce na doraźne modyfikacje i prowizorki. Piątą cechą jest możliwość dostarczenia nowego wyjaśnienia danych. W swoim modelu wymowy słów Seidenberg i McClelland wykazali, że ich sztuczna sieć neuronowa dostarczyła zintegrowane (pojedynczy mechanizm) wyjaśnienie danych zarówno dla słów regularnych, jak i wyjątków, podczas gdy wcześniej stare konwencje modelowania poznawczego wymuszały wyjaśnienie w kategoriach podwójnej ścieżki. Podobnie, model czasu przeszłego został sformułowany jako wyzwanie dla opisów opartych na regułach: chociaż wydajność dzieci można opisać w kategoriach reguł, twierdzono, że model wykazał, że to samo zachowanie można wyjaśnić za pomocą podstawowego mechanizmu, który nie używa wyraźnych reguł. W czasach świetności twierdzenia koneksjonizmu o nowych wyjaśnieniach pobudzały wiele debat. Odbyło się również wiele dyskusji na temat tego, w jakim stopniu koneksjonizm może zapewnić adekwatne wyjaśnienie wyższych procesów umysłowych. Fodor i Pylyshyn (1988) przeprowadzili atak na reprezentacyjną adekwatność koneksjonizmu. Koneksjoniści odpowiedzieli, a w pracach takich jak van Gelder (1990) argumentowano, że nie tylko mogliby przedstawić opis procesów wrażliwych na strukturę leżących u podstaw języka ludzkiego, ale że koneksjonizm zrobił to w nowatorski sposób: eliminacyjne stanowisko koneksjonistyczne. Teraz, gdy kurz opadł, modele koneksjonistyczne nie wydają się tak radykalnie różne od innych podejść do modelowania, jak kiedyś przypuszczano. Uważano, że jedną z ich mocnych stron jest zdolność do modelowania procesów umysłowych, symulowania zachowań i zapewniania dobrego dopasowania do danych z eksperymentów psychologicznych bez wyraźnego zaprogramowania do tego. Jednak obecnie istnieje większa świadomość, że decyzje dotyczące czynników, takich jak architektura sieci, forma, jaką przyjmą jej reprezentacje, a nawet interpretacja jej danych wejściowych i wyjściowych, są równoznaczne z formą programowania pośredniego lub ekstensjonalnego. Kontrola treści i prezentacji próbki szkoleniowej jest ważnym aspektem programowania ekstensjonalnego. Kiedy Pinker i Prince (1988) skrytykowali model czasu przeszłego, ważnym elementem ich krytyki było to, że eksperymentatorzy nierealistycznie dostosowali środowisko do wytworzenia wymaganych wyników, a wyniki były artefaktem danych treningowych. Chociaż wyniki wskazywały na krzywą w kształcie litery U w tempie nabywania, jak to ma miejsce u dzieci, Pinker i Prince argumentowali, że ta krzywa wystąpiła tylko dlatego, że sieć była narażona na czasowniki w nierealistycznie ustrukturyzowanej kolejności. Dalsze badania w dużej mierze odpowiedziały na tę krytykę, ale nadal jest tak, że wybór danych wejściowych i kontrola sposobu, w jaki są one prezentowane sieci, wpływają na to, czego sieć się uczy. Podobny argument można wysunąć w odniesieniu do wyboru reprezentacji danych wejściowych. Podsumowując: toczyła się debata na temat nowości koneksjonizmu i jego zdolności do uwzględniania przetwarzania poznawczego wyższego poziomu. Istnieje jednak powszechne uznanie, że podejście to wniosło trwały wkład, wskazując, w jaki sposób procesy poznawcze można wdrożyć na poziomie neuronów. Mimo to podejście koneksjonistyczne do modelowania poznawczego nie jest już tak popularne, jak kiedyś. Poniżej rozważono możliwe powody:
• Trudne wyzwania: Możliwym powodem spadku popularności sztucznych sieci neuronowych jest to, że jak sugeruje Elman, "dotarliśmy do punktu, w którym łatwe cele zostały zidentyfikowane, ale trudniejsze problemy pozostają". Trudne wyzwania, którym należy sprostać, obejmują pomysł skalowania modeli w celu uwzględnienia szerszego zakresu zjawisk i budowania modeli, które mogą uwzględniać więcej niż jedno zachowanie.
• Większe zrozumienie: W wyniku naszego większego zrozumienia działania i inherentnych ograniczeń sztucznych sieci neuronowych, część ich atrakcyjności zniknęła wraz z ich tajemnicą. Stały się one częścią arsenału metod statystycznych do rozpoznawania wzorców, a większość ostatnich badań nad sztucznymi sieciami neuronowymi skupiała się bardziej na pytaniach o to, czy najlepszy poziom generalizacji został osiągnięty efektywnie, niż na modelowaniu poznania.
Istnieje również większa wiedza na temat ograniczeń sztucznych sieci neuronowych, takich jak problem "katastrofalnej interferencji" związanej z propagacją wsteczną. Propagacja wsteczna działa imponująco, gdy wszystkie dane treningowe są prezentowane sieci w każdym cyklu treningowym, ale jej wyniki są mniej imponujące, gdy takie szkolenie jest przeprowadzane sekwencyjnie, a sieć jest w pełni trenowana na jednym zestawie elementów przed trenowaniem na nowym zestawie. Nowo nauczone informacje często kolidują z wcześniej nauczonymi informacjami i je nadpisują. Na przykład McCloskey i Cohen użyli propagacji wstecznej do trenowania sieci na problemie arytmetycznym dodawania + 1 (np. 1+1, 2+1,
, 9+1). Odkryli, że gdy kontynuowali trenowanie tej samej sieci, aby dodać 2 do danej liczby, "zapomniała", jak dodać 1. Sekwencyjne trenowanie w tej formie skutkuje katastrofalną interferencją. Sharkey i Sharkey wykazali, że można uniknąć problemu, jeśli zestaw treningowy jest wystarczająco reprezentatywny dla funkcji bazowej lub istnieje wystarczająco dużo sekwencyjnych zestawów treningowych. W kontekście tego przykładu, jeśli funkcja, której należy się nauczyć, to zarówno + 1, jak i + 2, wówczas zestawy treningowe zawierające wystarczającą liczbę przykładów każdej z nich mogą doprowadzić do uczenia się sieci, aby dodać 1 lub 2 do danej liczby. Jednak odbywa się to kosztem możliwości rozróżniania elementów, które zostały nauczone, od tych, które nie zostały nauczone. Ten przykład jest związany z innym ograniczeniem sztucznych sieci neuronowych: ich niezdolnością do ekstrapolacji poza ich zestaw treningowy. Chociaż ludzie mogą łatwo pojąć ideę dodania jednego do dowolnej danej liczby, nie jest tak łatwo nauczyć sieć ekstrapolacji poza dane, na których jest trenowana. Twierdzono , że ta niezdolność sztucznych sieci neuronowych trenowanych przy użyciu propagacji wstecznej do generalizacji poza ich przestrzeń treningową stanowi poważne ograniczenie mocy sieci koneksjonistycznych: ważne, ponieważ ludzie mogą łatwo generalizować uniwersalne relacje na nieznane przypadki. Oczywiste jest, że istnieją pewne aspekty poznania, szczególnie te związane z wyższymi zdolnościami ludzkimi, takimi jak zdolności rozumowania i planowania, które są trudniejsze do uchwycenia w modelach koneksjonistycznych.
• Zmiana epoki: Obecnie obserwuje się wzrost zainteresowania bardziej szczegółowym modelowaniem funkcji mózgu i towarzyszące temu niezadowolenie z prostoty modeli poznawczych, które często składały się z "niewielkiej liczby neuronów połączonych w trzech rzędach" (Hawkins, 2004). Podobnie, istnieje większa niecierpliwość w związku z naciskiem w koneksjonizmie na biologicznie nieprawdopodobny algorytm uczenia się metodą propagacji wstecznej. Jednocześnie wzrasta świadomość roli, jaką ciało odgrywa w poznaniu, oraz relacji między ciałem, mózgiem i środowiskiem (np. Clark, 1999). Tradycyjne modele koneksjonistyczne nie pasują łatwo do nowego nacisku na poznanie ucieleśnione
TRENDY NA PRZYSZŁOŚĆ
Jednym z oczekiwanych trendów na przyszłość będzie skupienie się na trudnych wyzwaniach. Prawdopodobne jest, że badania zbadają, w jaki sposób modele izolowanych procesów, takich jak nauka czasu przeszłego czasowników, mogą pasować do bardziej ogólnych opisów uczenia się języka i poznania. Istnieją dalsze pytania dotyczące rozwojowego pochodzenia wielu aspektów poznania oraz pochodzenia i postępu zaburzeń rozwojowych. Koneksjonistyczne modelowanie poznawcze prawdopodobnie zmieni się w odpowiedzi na nowy zeitgest. Prawdopodobnym scenariuszem jest to, że sztuczne sieci neuronowe będą nadal wykorzystywane do modelowania poznawczego, ale nie wyłącznie, jak wcześniej. Nadal będą stanowić część hybrydowych podejść do poznania, w połączeniu z metodami symbolicznymi. Podobnie, sztuczne sieci neuronowe mogą być używane w połączeniu z algorytmami ewolucyjnymi, aby tworzyć podstawę adaptacyjnych odpowiedzi na środowisko. Zamiast trenować sztuczne sieci neuronowe, można je dostosowywać za pomocą metod ewolucyjnych i wykorzystywać jako podstawę dla kontrolerów robotycznych (np. Nolfi i Floreano, 2000). Takie zmiany zapewnią przyszłość modelowaniu koneksjonistycznemu i pobudzą nowy zestaw pytań dotyczących pojawiania się poznania w odpowiedzi na interakcję organizmu ze środowiskiem.
WNIOSEK
W tym artykule opisaliśmy dwa przełomowe modele poznawcze koneksjonistyczne i rozważyliśmy ich charakterystyczne cechy. Nakreśliliśmy debaty na temat nowości i wystarczalności koneksjonizmu do modelowania poznania i argumentowaliśmy, że pod pewnymi względami podejście to dzieli cechy z podejściami modelowania, które je poprzedzały. Zidentyfikowano powody stopniowego zaniku zainteresowania koneksjonizmem i omówiono możliwe przyszłości. Koneksjonizm wywarł silny wpływ na modelowanie poznawcze i chociaż jego związek z mózgiem nie jest już postrzegany jako silny, dostarczył wskazówek, w jaki sposób procesy poznawcze można uwzględnić w mózgu. Twierdzi się tutaj, że chociaż podejście to nie jest już wszechobecne, nadal będzie stanowić ważny składnik przyszłych modeli poznawczych, ponieważ uwzględniają one interakcje między myślą, mózgiem i środowiskiem.
Sztuczne sieci neuronowo-glejowe
WSTĘP
Ponad 50 lat temu stworzono systemy koneksjonistyczne (CS) w celu przetwarzania informacji w komputerach, takich jak mózg ludzki. Od tego czasu systemy te znacznie się rozwinęły i obecnie pozwalają nam rozwiązywać złożone problemy w wielu dyscyplinach (klasyfikacja, klasteryzacja, regresja itp.). Jednak ten postęp nie jest wystarczający. Istnieje nadal wiele ograniczeń, gdy te systemy są używane. Większość ulepszeń uzyskano na dwa różne sposoby. Wielu badaczy preferowało konstrukcję sztucznych sieci neuronowych (ANN) opartych na modelach matematycznych z różnymi równaniami, które kierują ich funkcjonowaniem. W przeciwnym razie inni badacze udawali, że jak najbardziej możliwe jest stworzenie podobnych systemów do mózgu ludzkiego. Systemy zawarte w tym artykule powstały w wyniku drugiego sposobu badania. Wprowadzono CS, które udają, że imitują sieci neuronów glejowych mózgu. Systemy te nazywane są sztucznymi sieciami neuronów glejowych (ANGN). Te CS nie są zbudowane tylko z neuronów, ale również z elementów, które imitują neurony glejowe, zwanych astrocytami (Araque, 1999). Te systemy, które mają hybrydowe szkolenie, wykazały skuteczność w rozwiązywaniu problemów klasyfikacji za pomocą całkowicie połączonych sieci wielowarstwowych typu feed-forward, bez propagacji wstecznej i połączeń bocznych.
TŁO
ANNS lub CSS naśladują biologiczne sieci neuronowe, ponieważ nie wymagają programowania zadań, ale uogólniają i uczą się z doświadczenia. Obecne ANN są składane przez zestaw bardzo prostych elementów przetwarzania (PE), które naśladują neurony biologiczne i pewną liczbę połączeń między nimi. Do tej pory naukowcy, którzy udają, że naśladują mózg, starali się reprezentować w Anns, jakie znaczenie mają neurony w układzie nerwowym (NS). Jednak w ciągu ostatnich dziesięcioleci badanie wzrosły . Co ciekawe w polu neuronauki i coraz bardziej złożone obwody nerwowe, a także w systemie glejowym (GS), są uważnie obserwowane. Znaczenie funkcji GS prowadzi badaczy do myślenia, że ich udział w przetwarzaniu informacji w NS jest znacznie bardziej istotny niż wcześniej zakładano. W takim przypadku przydatne może być zintegrowanie z sztucznymi modelami inne elementy, które nie są neuronami. Od późnych lat 80. zastosowanie innowacyjnych i starannie rozwiniętych technik komórkowych i fizjologicznych (takich jak plastr-clamp, fluorescencyjne obrazy jonowe, mikroskopia konfokalna i biologia molekularna) do badań glejowych wbierało klasycznej idei, że astrocyty jedynie zapewniają strukturalne i Wsparcie troficzne dla neuronów i sugeruje, że te pierwiastki odgrywają bardziej aktywną rolę w fizjologii ośrodkowego układu nerwowego. Nowe odkrycia ujawniają teraz, że glej jest ściśle powiązany z aktywną kontrolą aktywności nerwowej i biorą udział w regulacji neurotransmisji synaptycznej . Obfite dowody sugerują istnienie dwukierunkowej komunikacji między astrocytami i neuronami oraz ważną aktywną rolę astrocytów w fizjologii NS . Dowody te doprowadziły do propozycji nowej koncepcji fizjologii synaptycznej, trójstronnej synapsy, która składa się z trzech elementów funkcjonalnych: elementów presynaptycznych i postsynaptycznych oraz otaczających astrocytów. Komunikacja między tymi trzema elementami ma bardzo złożone cechy, które wydają się bardziej niezawodnie odzwierciedlać złożoność przetwarzania informacji między elementami NS. Tak więc nie ma wątpliwości co do istnienia komunikacji między astrocytami i neuronami. Aby zrozumieć motywy tej odwrotnej sygnalizacji, musimy znać różnice i podobieństwa między ich właściwościami. Zaledwie dekadę temu absurdalne byłoby sugerowanie, że te dwa typy komórek mają bardzo podobne funkcje; Teraz zdajemy sobie sprawę, że podobieństwa uderzają z perspektywy sygnalizacji chemicznej. Oba typy komórek otrzymują wejścia chemiczne, które mają wpływ na receptory jonotropowe i metabotropowe. Po tej integracji oba typy komórek wysyłają sygnały do swoich sąsiadów poprzez uwalnianie transmitoracji chemicznych. Zarówno sygnalizacja neuronu do neuronu, jak i sygnalizacja neuron-naistrocyt pokazują właściwości plastyczne, które zależą od aktywności. Główną różnicą między astrocytami i neuronami jest to, że wiele neuronów rozszerza swoje aksony na duże odległości i prowadzi potencjały czynnościowe o krótkim czasie trwania z dużą prędkością, podczas gdy astrocyty nie wykazują żadnej pobudliwości elektrycznej, ale prowadzą skoki wapnia o długim czasie (dziesiątki sekund) ponad przesadnie) krótkie odległości i przy niskiej prędkości. Szybka sygnalizacja i funkcje wejściowe/wyjściowe w centralnych NS, które wymagają prędkości, wydają się należeć do domeny neuronowej. Ale co dzieje się z wolniejszymi zdarzeniami, takimi jak indukcja wspomnień i inne procesy abstrakcyjne, takie jak procesy myślowe? Czy sygnalizacja między astrocytami przyczynia się do ich kontroli? Dopóki nie ma odpowiedzi na te pytania, badania muszą kontynuować; Obecne prace oferują nowe sposoby rozwoju poprzez wykorzystanie technik sztucznej inteligencji (AI). Dlatego nie tylko udaje się, że poprawia CSS zawierające pierwiastki naśladujące astrocyty, ale ma również na celu skorzystanie z neuronauki w badaniu obwodów mózgu od innego punktu widzenia, AI. Najnowsze prace w tym obszarze są prezentowane przez Porto i inni.
GŁÓWNY TEMAT ARTYKUŁU
Wszystkie możliwości projektowe, zarówno w odniesieniu do architektury, jak i procesu szkolenia sieci neuronowej, są zasadniczo ukierunkowane na minimalizację poziomu błędu lub skrócenie czasu uczenia się systemu. W związku z tym w procesie optymalizacji mechanizmu, w przypadku sieci neuronowej, musimy znaleźć rozwiązanie dla wielu parametrów elementów i połączeń między nimi. Biorąc pod uwagę możliwe przyszłe ulepszenia, które optymalizują sieć neuronową pod kątem minimalnego błędu i minimalnego czasu szkolenia, nasze modele będą obwodami mózgowymi, w których udział elementów GS jest kluczowy dla przetwarzania informacji. Aby zaprojektować integrację tych elementów w sieci neuronowej i opracować metodę uczenia się dla powstałej sieci neuronowej, która pozwoli nam sprawdzić, czy w tych systemach występuje poprawa, przeanalizowaliśmy główne istniejące metody szkoleniowe, które zostaną wykorzystane do opracowania. Przeanalizowaliśmy metody szkolenia bez nadzoru i szkolenia z nadzorem oraz inne metody, które wykorzystują lub łączą niektóre z ich cech i uzupełniają analizę: szkolenie przez wzmocnienie, szkolenie hybrydowe i szkolenie ewolucyjne. Obserwowane ograniczenia. Kilka eksperymentów z ANN wykazało istnienie konfliktów między funkcjonowaniem CS a biologicznymi sieciami neuronowymi, ze względu na stosowanie metod, które nie odzwierciedlały rzeczywistości. Na przykład w przypadku wielowarstwowego perceptronu, który jest prostym CS, połączenia synaptyczne między PE mają wagi, które mogą być pobudzające lub hamujące, podczas gdy w naturalnym NS to neurony wydają się reprezentować te funkcje, a nie połączenia; ostatnie badania wskazują, że komórki GS, a konkretniej astrocyty, również odgrywają ważną rolę. Inne ograniczenie dotyczy algorytmu uczenia się znanego jako "propagacja wsteczna", co oznacza, że zmiana wartości połączeń wymaga wstecznej transmisji sygnału błędu w ANN. Tradycyjnie zakładano, że takie zachowanie jest niemożliwe w naturalnym neuronie, który zgodnie z teorią "polaryzacji dynamicznej" Ramóna y Cajala (1911) nie jest w stanie skutecznie przekazywać informacji odwrotnie przez akson aż do osiągnięcia somy komórkowej; nowe badania wykazały jednak, że neurony mogą przesyłać informacje do neuronów presynaptycznych w określonych warunkach, albo za pomocą istniejących mechanizmów w dendrytach, albo za pośrednictwem różnych interwencji komórek glejowych, takich jak astrocyty. Jeśli uczenie się jest nadzorowane, oznacza to istnienie "instruktora", co w kontekście mózgu oznacza zbiór neuronów, które zachowują się inaczej niż pozostałe, aby kierować procesem. Obecnie istnienie tego typu neuronów jest biologicznie niewytłumaczalne, ale GS wydaje się być silnie implikowane w tej orientacji i może być elementem, który konfiguruje instruktora, który do tej pory nie był brany pod uwagę. W tym kontekście niniejsze badanie analizuje, w jakim stopniu najnowsze odkrycia w dziedzinie neuronauki (Araque i in., 2001; Perea i Araque, 2002) przyczyniają się do powstania tych sieci: odkryć wynikających z aktywności mózgu w obszarach uważanych za zaangażowane w uczenie się i przetwarzanie informacji
Sztuczne sieci neuronów glejowych
Wielu badaczy wykorzystało obecny potencjał komputerów i wydajność modeli obliczeniowych do opracowania "biologicznych" modeli obliczeniowych i lepszego zrozumienia struktury i zachowania neuronów piramidalnych, o których uważa się, że biorą udział w procesach uczenia się i pamięci , oraz astrocytów . Modele te pozwoliły lepiej zrozumieć przyczyny i czynniki zaangażowane w specyficzne funkcjonowanie obwodów biologicznych. Niniejsza praca wykorzysta te nowe spostrzeżenia do postępu w dziedzinie nauk komputerowych, a konkretniej w dziedzinie sztucznej inteligencji. Przedstawiamy ANGN, które obejmują zarówno sztuczne neurony, jak i elementy sterujące przetwarzaniem, które reprezentują astrocyty, a których funkcjonowanie jest zgodne z krokami, które zostały pomyślnie zastosowane w konstrukcji i użytkowaniu CS: projektowanie, szkolenie, testowanie i wykonywanie. Ponadto, ponieważ badania obliczeniowe uczenia się za pomocą ANN zaczynają zmierzać w kierunku ewolucyjnych metod obliczeniowych, połączymy optymalizację w modyfikacji wag (zgodnie z wynikami modeli biologicznych) z wykorzystaniem algorytmów genetycznych (GA), aby znaleźć najlepsze rozwiązanie dla danego problemu. Ta technika ewolucyjna okazała się bardzo skuteczna w fazie szkolenia CS, ponieważ pomaga dostosować CS do optymalnego rozwiązania zgodnie z danymi wejściowymi, które trafiają do systemu i danymi wyjściowymi, które system musi wytworzyć. To zjawisko adaptacji ma miejsce w mózgu dzięki plastyczności jego elementów i może być częściowo kontrolowane przez GS; z tego powodu uważamy GA za część "sztucznego gleju". Rezultatem tej kombinacji jest hybrydowa metoda uczenia się (Porto, 2004). Projektowanie ANGN jest zorientowane na problemy klasyfikacyjne, które są rozwiązywane za pomocą prostych sieci, tj. sieci wielowarstwowych, chociaż przyszłe badania mogą doprowadzić do zaprojektowania modeli w bardziej złożonych sieciach. Wydaje się logicznym podejściem rozpoczęcie projektowania tych nowych modeli od prostych ANN i zorientowanie najnowszych odkryć dotyczących astrocytów i neuronów piramidalnych w przetwarzaniu informacji na ich wykorzystanie w sieciach klasyfikacyjnych, ponieważ kontrola wzmocnienia lub osłabienia połączeń w mózgu jest związana z adaptacją lub plastycznością połączeń, co prowadzi do generowania sposobów aktywacji. Proces ten może zatem poprawić klasyfikację wzorców i ich rozpoznawanie przez ANGN. Szczegółowy opis funkcjonowania ANGN i wyników z tymi systemami można znaleźć w Porto i inni
PRZYSZŁE TRENDY
Ciągle analizujemy inne możliwości modyfikacji synaptycznych w oparciu o zachowanie mózgu, aby zastosować je w nowych CS, które mogą rozwiązywać proste problemy przy użyciu prostych architektur. Ponadto, biorąc pod uwagę, że udowodniono, że gleje działają na złożone obwody mózgowe i że im bardziej mózg danej osoby się rozwinął, tym więcej gleju ma ona w swoim układzie nerwowym (zgodnie z tym, co Cajal powiedział sto lat temu (Ramón y Cajal, 1911), stosujemy zaobserwowane zachowanie mózgu do bardziej złożonych architektur sieciowych. Szczególnie po sprawdzeniu, że bardziej złożona architektura sieciowa osiągnęła lepsze wyniki w przedstawionym tutaj problemie. Z tego samego powodu zamierzamy przeanalizować, w jaki sposób nowe CS rozwiązują złożone problemy, na przykład te związane z przetwarzaniem czasu, w których całkowicie lub częściowo rekurencyjne sieci odgrywałyby rolę. Sieci te mogłyby łączyć swoje funkcjonowanie z tym nowym zachowaniem.
WNIOSEK
W tym artykule przedstawiono CS złożone ze sztucznych neuronów i sztucznych komórek glejowych. Projekt sztucznych modeli nie miał na celu uzyskania idealnej kopii naturalnego modelu, ale szeregu zachowań, których ostateczne funkcjonowanie jest do niego maksymalnie zbliżone. Niemniej jednak bliskie podobieństwo między nimi jest niezbędne do poprawy wyników i może skutkować bardziej "inteligentnymi" zachowaniami. Modyfikacje synaptyczne wprowadzone w CS i oparte na modelowanych procesach mózgowych wzmacniają trening wielowarstwowych architektur. Musimy pamiętać, że innowacja istniejących modeli ANN w kierunku rozwoju nowych architektur jest uwarunkowana potrzebą zintegrowania nowych parametrów z algorytmami uczenia się, aby mogły one dostosowywać swoje wartości. Nowe parametry, które zapewniają modelom elementów procesu ANN nowe funkcjonalności, są trudniejsze do zdobycia niż optymalizacje najczęściej używanych algorytmów, które zwiększają obliczenia i zasadniczo działają po stronie obliczeniowej algorytmu. ANGN integrują nowe elementy i dzięki metodzie hybrydowej podejście to nie komplikuje procesu treningu. Badania z tymi ANGN przynoszą korzyści AI, ponieważ mogą poprawić możliwości przetwarzania informacji, co pozwoliłoby nam poradzić sobie z szerszym zakresem problemów. Co więcej, pośrednio przyniosło to korzyści Neuroscience, ponieważ eksperymenty z modelami obliczeniowymi, które symulują obwody mózgowe, torują drogę trudnym eksperymentom przeprowadzanym w laboratoriach, a także dostarczają nowych pomysłów na badania
Powrót