
Eksploracja reguł asocjacyjnych
WSTĘP
Eksploracja danych to dziedzina obejmująca badanie narzędzi i technik wspomagających ludzi w inteligentnej analizie (eksploracji) gór danych. Eksploracja danych znalazła skuteczne zastosowania w wielu dziedzinach, w tym w sprzedaży i marketingu, identyfikacji przestępstw finansowych, zarządzaniu portfelem, diagnostyce medycznej, zarządzaniu procesami produkcyjnymi i poprawie opieki zdrowotnej itp. Techniki eksploracji danych można sklasyfikować jako techniki opisowe lub predykcyjne. Techniki opisowe podsumowują/charakteryzują ogólne właściwości danych, podczas gdy techniki predykcyjne konstruują model na podstawie danych historycznych i wykorzystują go do przewidywania niektórych cech przyszłych danych. Eksploracja reguł asocjacyjnych, analiza sekwencji i klasteryzacja to kluczowe opisowe techniki eksploracji danych, podczas gdy klasyfikacja i regresja to techniki predykcyjne. Celem tego artykułu jest wprowadzenie do problemu eksploracji reguł asocjacyjnych i opisanie niektórych podejść do rozwiązania tego problemu.
TŁO
Eksploracja reguł asocjacyjnych, jedna z podstawowych technik eksploracji danych, ma na celu wyodrębnienie interesujących korelacji, częstych wzorców lub struktur przyczynowych pomiędzy zestawami elementów w danych. Reguła asocjacyjna ma postać X → Y i wskazuje, że obecność elementów w poprzedniku reguły (X) implikuje obecność elementów w następniku reguły (Y). Na przykład reguła {PC, drukarka kolorowa} → {komputer stołowy} implikuje, że osoby, które kupują komputer PC (komputer osobisty) i drukarkę kolorową, mają również tendencję do kupowania komputera stołowego. Te skojarzenia nie są jednak oparte na inherentnych cechach domeny (jak w zależności funkcjonalnej), ale na współwystępowaniu elementów danych w zestawie danych. Tak więc eksploracja reguł asocjacyjnych jest techniką całkowicie sterowaną danymi. Reguły asocjacyjne zostały pomyślnie zastosowane w licznych aplikacjach, z których niektóre są wymienione poniżej:
1. Analiza rynku detalicznego: Odkrywanie reguł asocjacyjnych w danych detalicznych zostało zastosowane w domach towarowych do planowania powierzchni, planowania zapasów, ukierunkowanych kampanii marketingowych w celu zwiększenia świadomości produktu, promocji produktu i utrzymania klientów.
2. Analiza asocjacji sieciowych: Reguły asocjacyjne w eksploracji wykorzystania sieci były używane do rekomendowania powiązanych stron, odkrywania stron internetowych ze wspólnymi odniesieniami, stron internetowych z większością tych samych linków (lustrzanych) i predykcyjnego buforowania. Wiedza ta jest stosowana w celu ulepszenia projektu witryny internetowej i przyspieszenia wyszukiwania.
3. Odkrywanie powiązanych pojęć: Słowa lub zdania, które często pojawiają się razem w dokumentach, nazywane są powiązanymi pojęciami. Reguły asocjacyjne mogą być używane do odkrywania powiązanych pojęć, co dalej prowadzi do odkrycia splagiatowanego tekstu i rozwoju ontologii itp.
Problem eksploracji reguł asocjacyjnych (ARM) został wprowadzony przez Agrawala i inych. Duże bazy danych transakcji detalicznych zwane bazami danych koszyków rynkowych, które gromadzą się w domach towarowych, stanowiły motywację dla ARM. Koszyk odpowiada fizycznej transakcji detalicznej w domu towarowym i składa się z zestawu artykułów kupowanych przez klienta. Transakcje te są rejestrowane w bazie danych zwanej bazą danych transakcji. Celem jest analiza nawyków zakupowych klientów poprzez znalezienie powiązań między różnymi artykułami, które klienci umieszczają w swoich "koszykach zakupowych". Odkryte reguły asocjacyjne mogą być również wykorzystywane przez kierownictwo w celu zwiększenia skuteczności reklamy, marketingu, zarządzania zapasami i zmniejszenia powiązanych kosztów. Autorzy pracowali nad bazą danych transakcji boolowskich. Każdy rekord odpowiada koszykowi klienta i zawiera identyfikator transakcji (TID), szczegóły transakcji i listę artykułów zakupionych w ramach transakcji. Lista artykułów jest reprezentowana przez wektor boolowski, w którym jedynka oznacza obecność odpowiedniego artykułu w transakcji, a zero oznacza brak. Problemem znalezienia reguł asocjacyjnych jest znalezienie kolumn z często występującymi regułami w bazie danych boolowskich. Jednak większość algorytmów dla ARM używa formy bazy danych transakcyjnych pokazanej po prawej stronie. Poniżej podajemy matematyczną formułę problemu.
MATEMATYCZNA FORMUŁA PROBLEMU ARM
Niech I = {i1, i2, …,in} oznacza zbiór elementów, a D oznacza bazę danych N transakcji. Transakcja T ∈ D jest podzbiorem I, tj. T ⊆ I i jest powiązana z unikalnym identyfikatorem TID. Zbiór elementów to kolekcja jednego lub większej liczby elementów. X jest zbiorem elementów, jeśli X ⊆ I. Mówi się, że transakcja zawiera zbiór elementów X, jeśli X ⊆ T. Zbiór k-elementów to zbiór elementów, który zawiera k elementów. Reguła asocjacji ma postać X → Y [wsparcie, pewność], gdzie X ⊂ I, Y ⊂ I, X ∩ Y = ∅, a wsparcie i pewność to metryki oceny reguł. Wsparcie zbioru elementów X to ułamek transakcji, które zawierają X. Oznacza ono prawdopodobieństwo, że transakcja zawiera X.
Wsparcie (X) = P(X) = Liczba transakcji zawierających X / Całkowita liczba transakcji w D
Wsparcie reguły X → Y w D wynosi "s", jeśli s% transakcji w D zawiera X ∪ Y i jest obliczane jako:
Wsparcie (X → Y) = P(X ∪ Y) = Liczba transakcji zawierających X ∪ Y / Całkowita liczba transakcji w D
Wsparcie wskazuje na stopień rozpowszechnienia reguły. Reguła o niskiej wartości wsparcia reprezentuje rzadkie zdarzenie. Pewność reguły mierzy jej siłę i dostarcza wskazówki co do niezawodności przewidywań dokonanych przez regułę. Reguła X → Y ma pewność "c" w D, jeśli c% transakcji w D, które zawierają X, zawiera również Y. Jest ona obliczana jako prawdopodobieństwo warunkowe, że Y występuje w transakcji, zakładając, że X jest obecne w tej samej transakcji, tj.
Pewność (X → Y) = P(Y/X) = P(X ∪ Y) / P(X)
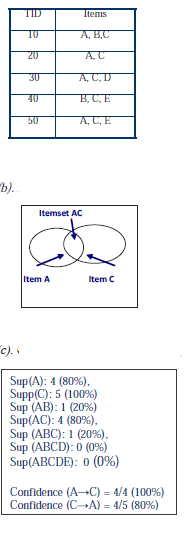
Przykład 1: Rozważ przykładową bazę danych przedstawioną na (a). Tutaj I = {A, B, C, D, E}. Rysunki (b) i (c) pokazują obliczenia wsparcia i pewności dla reguły. Przy n elementach w I, całkowita liczba możliwych reguł asocjacyjnych jest bardzo duża (O(3n)). Jednak większość tych reguł (skojarzeń) istniejących w D nie jest interesująca dla użytkownika. Miary ciekawości są stosowane w celu zmniejszenia liczby reguł odkrytych przez algorytmy. Najważniejszym kryterium ciekawości jest wysoka powszechność zarówno zestawów elementów, jak i reguł, która jest określana przez użytkownika jako minimalna wartość wsparcia. Zestaw elementów (reguła), którego wsparcie jest większe lub równe określonemu przez użytkownika minimalnemu progowi wsparcia (minsup), nazywa się Częstym zestawem elementów (regułą). Drugim kryterium ciekawości jest siła reguły. Reguła, której pewność jest większa niż określony przez użytkownika minimalny próg ufności (minconf), jest interesująca dla użytkownika. Pewność może jednak czasami być myląca. Na przykład, pewność reguły może być wysoka, nawet jeśli poprzednik i następnik reguły są niezależne. Podniesienie (nazywane również Zainteresowaniem) i Przekonanie reguły to inne powszechnie stosowane miary zainteresowania regułą. Należy zidentyfikować odpowiednią miarę siły reguły dla zastosowania.
GÓRNICTWO REGUŁ ASOCJONOWANIA
Ponieważ reguła asocjacji jest implikacją między zestawami elementów, podejście siłowe do generowania reguł asocjacji wymaga zbadania relacji między wszystkimi możliwymi zestawami elementów. Taki proces zazwyczaj obejmowałby zliczanie współwystępowania wszystkich zestawów elementów w D i późniejsze generowanie z nich reguł. Dla n elementów istnieje 2n możliwych zestawów elementów, które należy zliczyć. Może to wymagać nie tylko zaporowej ilości pamięci, ale także złożonego indeksowania liczników. Ponieważ użytkownik jest zainteresowany tylko częstymi regułami, należy zliczyć tylko częste zestawy elementów przed wygenerowaniem reguł asocjacji. Tak więc problem eksploracji reguł asocjacji rozkłada się na dwie fazy:
Faza I: Odkrywanie częstych zestawów elementów
Faza II: Generowanie reguł z częstych zestawów elementów odkrytych w fazie I.
Różne algorytmy dla ARM różnią się pod względem podejścia do optymalizacji czasu i wymagań dotyczących pamięci masowej dla zliczania w pierwszej fazie. Pomimo zmniejszenia przestrzeni wyszukiwania poprzez narzucenie ograniczenia minsup, generowanie częstych zestawów elementów jest nadal procesem kosztownym obliczeniowo. Antymonotoniczna własność wsparcia jest ważnym narzędziem do dalszego zmniejszania przestrzeni wyszukiwania i jest używana w większości algorytmów reguł asocjacyjnych. Zgodnie z tą własnością, wsparcie zbioru elementów nigdy nie przekracza wsparcia żadnego z jego podzbiorów, tj. jeśli X jest zbiorem elementów, to dla każdego z jego podzbiorów Y, sup(X) ⇐ sup(Y). Ta własność sprawia, że zbiór częstych zbiorów elementów jest domknięty w dół. Zadanie generowania reguł jest trywialne, gdy zbiór częstych zbiorów elementów zostanie odkryty. Algorytm Apriori wykorzystuje podejście poziomowe do odkrywania częstych zbiorów elementów. Ten algorytm wykonuje wielokrotne skanowanie danych. Podczas każdego skanowania algorytm generuje i zlicza potencjalne częste zbiory elementów (kandydatów). Kandydujące zbiory elementów o rozmiarze k+1 są generowane przez łączenie częstych zbiorów elementów o rozmiarze k i są przycinane, wykorzystując antymonotoniczną własność. Pod koniec skanowania zestaw częstych zbiorów elementów jest potwierdzany. Strategia ta wiąże się z ogromnymi kosztami wejścia/wyjścia i zmotywowała szereg wariantów, które zmniejszają liczbę liczników (kandydatów) i skanów. Algorytm wzrostu FP wykorzystuje metodę wzrostu wzorca, aby uniknąć kosztownego procesu generowania i testowania kandydatów, dlatego jest uważany za ważny kamień milowy. Algorytm wykorzystuje opartą na drzewie strukturę danych w pamięci, zwaną FP-Tree, aby przechowywać bazę danych w formie skompresowanej. Dwa przebiegi są wykonywane po bazie danych w celu skonstruowania drzewa prefiksów, które jest następnie używane do generowania częstych wzorców. Zaproponowano również podejścia oparte na kratce w celu wydajnego odkrywania częstych zestawów elementów. Zadanie generowania reguł (faza II) z danych częstych zestawów elementów jest dość proste . Sprowadza się to do wyliczenia wszystkich podzbiorów częstego zestawu elementów i znalezienia stosunku wsparcia każdego zestawu elementów do wsparcia każdego z jego podzbiorów. Podzbiory, których stosunek jest większy niż minconf, kwalifikują się jako silne reguły i są zgłaszane użytkownikowi.
RODZAJE REGUŁ ASOCJONOWANIA
Popularność ARM doprowadziła do jego zastosowania w wielu typach danych i domenach aplikacji. W literaturze poświęconej eksploracji danych opisano kilka wyspecjalizowanych rodzajów reguł asocjacyjnych. Opisujemy tutaj niektóre z ważnych typów:
1. Reguły asocjacji ilościowej: Reguły asocjacji ilościowej wprowadziły pojęcie eksploracji asocjacji między atrybutami numerycznymi oprócz atrybutów kategorycznych. Reguły asocjacji ilościowej można wyprowadzić, mapując wartości atrybutów na zestaw kolejnych liczb całkowitych lub dzieląc je na przedziały. Przykład reguły asocjacji ilościowej:
Wiek (x, "30….39") ^ pensja (x, "42…48K.") → kupuje(x, "samochód") [1%, 75%]
2. Reguły asocjacji wielopoziomowej: Wiele aplikacji ma wrodzoną taksonomię (hierarchię pojęć) między elementami. W takich scenariuszach reguły asocjacji mogą być generowane na różnych poziomach taksonomii, aby uchwycić wiedzę na różnych poziomach abstrakcji. W miarę przesuwania się w dół hierarchii (od wartości uogólnionych do wyspecjalizowanych), wsparcie reguł maleje, a niektóre reguły mogą stać się nieciekawe. Jednak podczas wspinania się w górę hierarchii niektóre nowe reguły mogą stać się interesujące. Daje to początek regułom asocjacji wielopoziomowej , które uchwycą powiązania między elementami lub atrybutami na różnych poziomach abstrakcji, tj. na różnych poziomach hierarchii pojęć. Na przykład reguła {Brown Bread} → {Coke} uchwyca powiązania między elementami na różnych poziomach hierarchii pojęć. Reguły wielopoziomowe można eksplorować przy użyciu tych samych progów wsparcia lub różnych progów na różnych poziomach. Wybór odpowiedniego poziomu abstrakcji może mieć znaczący wpływ na użyteczność generowanej wiedzy. Kopanie na bardzo wysokim poziomie abstrakcji prawdopodobnie wygeneruje zbyt uogólnione reguły, które mogą nie być interesujące, podczas gdy kopanie na zbyt niskim poziomie abstrakcji może prowadzić do generowania wysoce specyficznych reguł.
3. Wielowymiarowe reguły asocjacyjne: Reguły asocjacyjne zasadniczo ujawniają powiązania wewnątrz rekordu. Jeśli powiązania istnieją między różnymi wartościami tego samego atrybutu (wymiaru), powiązanie nazywa się jednowymiarową regułą asocjacyjną, podczas gdy jeśli powiązania obejmują wiele wymiarów, powiązania nazywa się wielowymiarowymi regułami asocjacyjnymi. Na przykład następująca jednowymiarowa reguła zawiera koniunkcje zarówno w antecedencie, jak i w konsekwencji pojedynczego atrybutu "kupuje".
Kupuje (X, "mleko") i Kupuje (X, "masło") → Kupuje (X, "chleb")
Wielowymiarowe asocjacje zawierają dwa lub więcej predykatów, na przykład
Wiek (X, "19-25") i Zawód (X, "student") → Kupuje (X, "cola")
4. Reguły asocjacyjne w strumieniowaniu danych: Wspomniane typy reguł dotyczą statycznych repozytoriów danych. Jednak wydobywanie reguł ze strumieni danych jest znacznie bardziej złożone . Dziedzina ta jest stosunkowo nowa i stwarza dodatkowe wyzwania, takie jak charakterystyki danych jednokrotnego spojrzenia, ograniczona pamięć główna, ciągła aktualizacja danych i przetwarzanie online, aby móc podejmować decyzje w locie.
5. Eksploracja reguł asocjacyjnych z wieloma minimalnymi wsparciami: W dużych domach towarowych, w których liczba przedmiotów jest bardzo duża, użycie pojedynczego progu wsparcia czasami nie daje interesujących reguł. Ponieważ trendy zakupowe dla różnych przedmiotów często znacznie się różnią, zaleca się stosowanie różnych progów wsparcia dla różnych przedmiotów .
6. Negatywne reguły asocjacyjne: Typowe reguły asocjacyjne odkrywają korelacje między przedmiotami, które są kupowane podczas transakcji i są nazywane pozytywnymi regułami asocjacyjnymi. Negatywne reguły asocjacyjne odkrywają implikacje we wszystkich przedmiotach, niezależnie od tego, czy zostały kupione, czy nie. Negatywne reguły asocjacyjne są przydatne w analizie koszyka rynkowego w celu identyfikacji produktów, które są ze sobą sprzeczne lub się uzupełniają. Znaczenie negatywnych reguł asocjacyjnych zostało podkreślone u Brina, Wu i innych.
PRZYSZŁE TRENDY
Chociaż analiza asocjacji będzie nadal oddziaływać na różne sfery naukowe i biznesowe za pośrednictwem baz danych opieki zdrowotnej, baz danych finansowych, baz danych przestrzennych, baz danych multimedialnych i baz danych szeregów czasowych itp., badamy rolę górnictwa reguł asocjacyjnych w niektórych obiecujących zastosowaniach.
Business Intelligence (BI): BI przekształca surowe dane w spersonalizowaną inteligencję w celu zwiększenia zadowolenia klientów, lojalności i rentowności produktów. Integruje dane z wielu źródeł w całej firmie, analizuje je i działa szybko na podstawie wyników, co prowadzi do przewagi konkurencyjnej i terminowego wdrażania rozwiązań. Analiza asocjacji jest jednym z podstawowych narzędzi wspierających BI. W sektorze detalicznym analiza asocjacji stanowi podstawę analizy danych punktu sprzedaży, analizy koszyka rynkowego, optymalizacji zarządzania zasobami i przestrzenią. W sektorze bankowym BI wykorzystuje badanie asocjacji do przeprowadzania analizy ryzyka kredytowego, wykrywania oszustw i zatrzymywania klientów. Firmy kredytowe korzystają z wykrywania oszustw, monitorowania wzorców zakupów, oceniania wiarygodności klientów i analizowania sprzedaży krzyżowej.
Eksploracja danych strumieniowych: W przeciwieństwie do danych w tradycyjnych statycznych bazach danych, strumień danych jest uporządkowaną sekwencją elementów, która jest ciągła, nieograniczona, zwykle występuje z dużą prędkością i ma rozkład danych, który zmienia się w czasie. Wraz ze wzrostem liczby aplikacji w strumieniach danych eksploracyjnych, rośnie potrzeba przeprowadzania eksploracji reguł asocjacyjnych w danych strumieniowych. Reguły asocjacyjne są wykorzystywane do szacowania brakujących danych w strumieniach danych generowanych przez czujniki i szacowania częstotliwości strumieni pakietów internetowych. Eksploracja reguł asocjacyjnych jest również przydatna do monitorowania przepływów produkcyjnych w celu przewidywania awarii lub generowania raportów na podstawie strumieni dzienników internetowych. Bioinformatyka: Asocjacje są wykorzystywane w bazach danych bioinformatycznych do identyfikacji współwystępujących sekwencji genów. Są również wykorzystywane do wykrywania mutacji genów. Gen to segment cząsteczki DNA, który zawiera wszystkie informacje wymagane do syntezy produktu. Każda zmiana w sekwencji DNA genu (na przykład: insercja, usunięcie, insercja/usunięcie, złożona i wielokrotna substytucja) jest określana jako mutacja genu. Odkrycie interesujących relacji asocjacyjnych wśród ogromnej liczby mutacji genów jest ważne, ponieważ może pomóc w ustaleniu przyczyny mutacji w nowotworach i chorobach.
WNIOSEK
Eksploracja reguł asocjacyjnych jest ważną techniką eksploracji danych, która została wprowadzona w celu opisania powiązań wewnątrz rekordów w bazach danych transakcyjnych. Jednak zarówno środowisko akademickie, jak i przemysł uznały tę technologię za rentowną i odnoszącą sukcesy ze względu na jej prostotę, łatwość zrozumienia i szerokie zastosowanie. Ponad dekadę później technologia ta nadal obiecuje być siłą napędową dla niektórych nowych, wymagających zastosowań. Nie ma wątpliwości, że eksploracja reguł asocjacyjnych została uznana za jeden z najważniejszych wkładów społeczności baz danych w KDD. W tym artykule wprowadziliśmy pojęcie reguł asocjacyjnych, ich zastosowania i przedstawiliśmy ich matematyczną formułę. Przedstawiliśmy również główne kamienie milowe w historii rozwoju reguł asocjacyjnych. Omówiono również ogólną strategię eksploracji, powiązane problemy, takie jak ogrom przestrzeni wyszukiwania i miary ciekawości. Na koniec opisano różne typy reguł asocjacyjnych.
Powrót