“Wspomóż rozwój naszego Bloga. Kliknij w Reklamę. Nic nie tracisz a zyskujesz naszą wdzięczność … oraz lepsze, ciekawsze TEKSTY. Dziękujemy”
Ta sekcja przeniesie nasze funkcje wykresów na wyższy poziom, ponieważ opracowujemy własny niestandardowy typ wykresu. Pakiet ggplot2 nie ma domyślnie możliwości tworzenia wykresów radarowych, więc opracujemy go sami w tej sekcji. Istnieją pakiety, które rozszerzają ggplot2 o możliwości wykresu radarowego (na przykład ggradar), ale pokażemy, jak stworzyć go samodzielnie od podstaw. Po przeczytaniu tej sekcji będziesz przygotowany do samodzielnego tworzenia złożonych wykresów.
Wykresy radarowe są nanoszone na kołowym obszarze roboczym i mogą pokazywać jednocześnie wiele wartości zmiennych. Tworzą kształt przypominający radar i są przydatne, jeśli chcesz porównać różne wartości zmiennych między różnymi obiektami. Czasami są one używane do wizualnego zrozumienia jak podobne lub różne są byty. Jeśli nie jesteś zaznajomiony z tego typu wykresami, na poniższej ilustracji pokazano jeden. W naszym przykładzie, zamiast mierzyć prędkość, trwałość, komfort, moc i przestrzeń, jak w tym przykładzie, zmierzymy trzy różne makroskładniki odżywcze dla pięciu największych klientów The Food Factory.
Funkcja grpah_radar() otrzymuje jako parametry ramkę danych data i zmienną, za pomocą której chcemy wyświetlać radary (w naszym przypadku CLIENT_ID). Po pierwsze, przekształca dane, których potrzebujemy, z formatu szerokiego na długi za pomocą funkcji gather(). Następnie tworzy etykiety, które będą używane na górze każdego wykresu radarowego, które pokazują zysk generowany przez każdy CLIENT_ID. Na koniec zwraca obiekt wykresu, który jest tworzony przez określenie makroskładników i wartości procentowych, dodanie grup warstw wielokątów, kolorów i wypełnień za pomocą CLIENT_ID oraz dostosowanie alpha (przezroczystość) i rozmiar linii, aby dobrze wyglądały.
Funkcja facet_wrap() służy do powtarzania tego samego wykresu dla każdego wystąpienia zmieej by w danych (w naszym przypadku CLIENT_ID). Ponieważ wymaga formuły, a my chcemy uogólniamy jego użycie, używamy kombinacji funkcji as.formula() i paste(). My także przekazujemy parametr nrow=1, aby mieć pewność, że otrzymamy pojedynczy wiersz wykresów. Usuwamy dowolne informacje legendy z funkcją guides(), wysyłając ciąg „none” do odpowiedniej legendy, zastosuj naszą funkcję coord_radar() i usuń etykiety osi:
grpah_radar <- function(datat, by) {
data <- tidyr :: gather(
datat, MARO, PERVCENTAGE, PROTEIN: FAT, factor_key TRUE)
datat$CLIENT_ID <- paste(
data$CLIENT_ID, „ ($”, data$PROFIT, „)” , sep = „ „
)
Return(
ggplot(data, aes (MACRO, PERCENTAGE)) +
geom_polygon(
aes_string(group = by , color = by, fill = by),
alpha = 0.4,
size = 2
) +
faet+wrap(as.formula(paste(„~”, by)) , nrow = 1) +
guides(color = „none”, fill = „none”) +
coord_radar() +
xlab(„”)+
ylab(„”)
)
}
Funkcja coord_radar() nie jest funkcją wbudowaną w pakiecie ggplot i musimy ją sami zaprogramować. Wersja, z którą będziemy tutaj pracować, jest nieco zmodyfikowaną wersją coord_radar() znalezionego w Internecie, przypisanego najpierw Hadleyowi Wickhamowi. Wykorzystuje funkcję ggproto() do dziedziczenia i modyfikacji warstwy współrzędnych biegunowych w ggplot2, która otrzymuje parametry theta (kąt), r (promień), start (punkt początkowy), direction (czy używać jednostek dodatnich, czy ujemnych) i hack, który zwraca funkcję wymaganą przez parametr is_liear, tak aby jego wartość zawsze była TRUE. Gdybyśmy nie wysłali tego ostatniego hacka, otrzymalibyśmy okrągłe kształty, tak jak robimy to ze współrzędnymi biegunowymi podczas próby wykreślenia linii prostej. Poprzedni kod po prostu wybiera odpowiednią oś dla kąta, aby uzyskać kształt radaru:
coord_radar() <- function(theta = „x”, start = 0, diection =1 ) {
if (theta ==”x”) {
r <- „y”
} else {
r <- „x”
}
return (ggproto(
„CordRadar”,
CoordPolar,
theta = theta,
r=r,
start = start,
direction = sign(direction),
is_linear = function(coord) { return (TRUE) }
))
}
Funkcja ggproto() jest używana jako wewnętrzny system obiektów w pakiecie ggplot2 i została opracowana, aby uniknąć konieczności zmiany zbyt dużej części kodu podczas implementowania obiektów warstwowych. Nie zaleca się używania go, chyba że jest to absolutnie konieczne. Teraz, gdy mamy gotową funkcję wykresu, musimy się upewnić, że nasze dane są gotowe i poprawnie sformatowany. Aby to zrobić, tworzymy funkcję filter_datat() to, która filtruje dane i tworzy oczekiwaną strukturę. Funkcja otrzymuje jako parametry data, którego użyjemy, liczbę dni wstecz od bieżącej daty jako n_days, liczbę najlepszych wykonawców, które pokażemy jako n_top, oraz zmienną będziemy agregować przez aggregate_by.
Najpierw filtrujemy dane n dni wstecz, a następnie zachowujemy obserwacje tylko dla n_top wykonawców zgodnie ze zmienną aggregate_by .Gdy to robimy, odpowiednio aktualizujemy data. Następnie agregujemy dane dwukrotnie, raz o PRoFIT, a drugi raz o makroskładniki odżywcze (PROTEIN, CARBS i FAT) i odzyskujemy nazwę CLIENT_ID do ramki danych. W ten sposób powstają dwie ramki danych, aggr_profit i aggr_macros, z których każda agreguje odpowiednie zmienne dla każdej unikalnej CLIET_ID . Zauważ, że dzielimy ten proces na dwie niezależne części, ponieważ chcemy połączyć PROTEIN, ARBS i FAT z mean, aby uzyskać średnią preferencję dla każdego CLIENT_ID, ale jednocześnie chcemy zagregować PROFIT z sum, aby uzyskać całkowity zysk (a nie średni zysk) dla każdego CLIENT_ID. Na koniec łączymy dane z funkcją merge(), używając naszej zmiennej aggregate_by aby być indeksem, za pomocą którego łączymy dane, usuwamy kolumny reszt z ramki danych i zamów przez PROFIT:
filter_data <- function(data, n_days, _top, aggregate_by, static = TRUE) {
data <- filter_n_days_back(datat, n_days)
data <- filter_n_top(data, n_top, aggregate_by)
if (static) {
aggr_profit <_ aggregate (
data[, c(„PROFIT”, „PROFIT_RATIO”)],
list(data[, aggregate_by]),
sum
)
aggr_profit$CLIENT_ID <- aggr_profit$GROUP.1
aggr_macros <- aggregate(
data[, c(„PROTEI”, „CARBS”, „FAT”)].
list(data[, aggregate_by]),
mean
)
aggr_macrso$CLIENT_ID <- aggr_macros$Group.1
data<- merge(aggr_profit, aggr>maros, by = aggregate_by)
drop_columns <- c(„Group.1.x”, „Group.1.y”, „PROFIT_RATIO”)
data <- datat[, !(names(data) %i% drop_olumns0}
data <- data[order(-datat%PROFIT), ]
}
return(data)
}
Jeśli uważnie czytasz kod, być może zauważyłeś szczegół, o którym nie wspomnieliśmy, użycie zmiennej PROFIT_RATIO w agregacji, nawet jeśli nie używamy jej później w funkcji . Przyczyną włączenia PROFIT_RATIO do obliczeń aggregate() jest efekt uboczny, jaki wywołuje. Podczas określania dwóch lub więcej zmiennych w danych dla funkcji aggregate(), wynik wraca z rzeczywistymi nazwami kolumn ramki danych w wynikowej ramce danych aggr_profit. Jeśli określimy tylko PROFIT samodzielnie, wynik będzie miał kolumnę o nazwie x zamiast PROFIT, jak widzieliśmy i używaliśmy w poprzednim kodzie w. Jest to łatwy sposób na uniknięcie zmiany nazw zmiennych. Moim zdaniem funkcja aggregate() powinna zawsze zwracać oryginalne nazwy ramek danych, ale tak nie jest, więc musimy to obejść. Pamiętaj o tej użyteczności podczas programowania dla innych. Aby zobaczyć, jak faktycznie filtrujemy daty, zajrzyj do funkcji filter_n_days)back(). Jak widać, jako parametr otrzymujemy data, który chcemy przefiltrować, oraz liczbę dni, które chcemy zachować wstecz jako n. Jeśli n jest NULL, co oznacza, że użytkownik nie chciał filtrować danych wstecz, to po prostu zwracamy to samo data, które otrzymaliśmy. Jeśli otrzymasz liczbę w ciągu n, otrzymamy aktualną datę i odejmiemy od niej dni za pomocą Sys_Date()-n To proste odejmowanie odbywa się automatycznie z dniami jako jednostkami dzięki technice zwanej przeciążaniem operatora. Na koniec po prostu zachowujemy te daty, które są co najmniej datą n_days_back (kolejne użycie techniki przeciążania operatorów, która pozwala nam porównywać daty). Funkcja filter_n_top() to ta, którą utworzyliśmy wcześniej dla kodu wykresów pudełkowych:
filter_n_days_bak <- function(data,) {
if (is.null(n)) {
return(datat)
}
n_days_baks <- SYs.Date() –
return(data[data[, „DATE”] .= n_days_back, ])
}
Nasza funkcja filter_data() jest sama w sobie bardzo przydatna. Na przykład możemy łatwo pokazać średnie makroskładniki odżywcze dla 5 najlepszych klientów w ciągu ostatnich 30 dni, wykonując:
filter_data(sales, 30, 5, „CLIENT_ID”)
#> CLIENT_ID PROFIT PROTEIN CARBS FAT
#> 2 BAWHQ69720 74,298 0,3855850 0,3050690 0,3093460
#> 3 CFWSY56410 73,378 0,4732115 0,3460788 0,1807097
#> 4 CQNQB52245 61,468 0,1544217 0,3274938 0,5180846
#> 1 AHTSR81362 58,252 0,3301151 0,3326516 0,3372332
#> 5 VJAQG30905 53,104 0,2056474 0,5909554 0,2033972
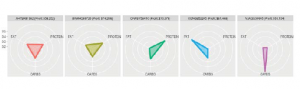
Po zainwestowaniu w stworzenie odpowiedniej funkcji wykresu jesteśmy teraz w stanie łatwo tworzyć własne wykresy radarowe. Na przykład możemy łatwo utworzyć odpowiedni wykres radarowy dla danych, które właśnie pokazaliśmy wcześniej, za pomocą:
graph_radar(filter_data(sales, 30, 5, „CLIENT_ID”), „CLIENT_ID”)
Poniższy obraz przedstawia poprzednie polecenie: