Trzy funkcje read.table(), read.csv() i read.delim() są zasadniczo tą samą funkcją, różniącą się jedynie domyślnymi wartościami argumentu sep i nagłówkiem argumentu. Podobnie jak w przypadku funkcji scan(), argument sep podaje symbol używany do oddzielania wartości danych w pliku i może być dowolną wartością jednobajtową. Nagłówek argumentu przyjmuje wartości logiczne i mówi funkcji, czy odczytać nagłówek z pierwszej linii, czy nie. Te trzy funkcje importują dane z pliku, w którym plik jest w postaci macierzy lub z wartości argumentu tekstowego. Jeśli dane pochodzą z pliku, lokalizacja pliku jest wprowadzana jako pierwsza w wywołaniu w cudzysłowie. Lokalizacja pliku może być względna w stosunku do obszaru roboczego lub bezwzględna, w tym adresy URL. Aby wyszukać plik, wprowadź file.choose() jako nazwę w cudzysłowie, na przykład read.table (file.choose()). Oto przykład z cytowaną nazwą:
> read.table(“test2.txt”)
V1 V2 V3 V4
1 one 3 5 7
2 two 4 6 8
Zauważ, że kolumny nie muszą być w tym samym trybie. Tutaj plik test2.txt zawiera dane znakowe i numeryczne i znajduje się w tym samym folderze co obszar roboczy języka R. Jeśli nie wszystkie wiersze w pliku mają taką samą długość, domyślnie funkcja zwróci błąd. Argument fill jest argumentem logicznym i mówi R, aby wypełnił wiersze, które mają mniej elementów niż inne wiersze. Na przykład:
> read.table(“test4.txt”, fill=T)
V1 V2 V3 V4
1 one 3 5 7
2 two 4 6 NA
Tutaj test4.txt brakuje ostatniego elementu drugiego wiersza. R wypełnia element NA. Jeśli tekst argumentu jest używany do wejścia do tabeli, koniec wiersza jest oznaczony \ n. Na przykład:
> read.table(text=”1 2 3 4 \n 2 3 4 5″)
V1 V2 V3 V4
1 1 2 3 4
2 2 3 4 5
Dla read.table() domyślną wartością sep jest biały znak, a domyślną wartością nagłówka jest FALSE. Dla read.csv() domyślną wartością sep jest przecinek, a domyślną wartością nagłówka jest TRUE. Dla read.delim() domyślną wartością sep jest tabulator – który w R jest wprowadzany jako \ t – a domyślną wartością nagłówka jest PRAWDA. (Istnieją dwie inne powiązane funkcje, read.csv2 () i read.delim2 (), które są przeznaczone do użytku w Europie i mają dec, styl punktu dziesiętnego, ustawiony na “, ” i, dla read.csv2( ), zestaw sep równy;.) Trzy funkcje tworzą ramkę danych z danych, więc tryby elementów wystarczy zachować spójność w kolumnach. Jeśli kolumna zawiera dane znakowe, to domyślnie kolumna jest konwertowana na współczynnik. Ustawienie argumentu as.is na TRUE spowoduje konwersję na znak. Na przykład:
> read.table(“test3.txt”, sep=”,”)
V1 V2 V3 V4
1 one 1 3 4
2 1 four 3 2
> class(read.table(“test3.txt”, sep=”,”)[,1])
[1] “factor”
> class(read.table(“test3.txt”, sep=”,”)[,3])
[1] “integer”
> read.table(“test3.txt”, sep=”,”, as.is=T)
V1 V2 V3 V4
1 one 1 3 4
2 1 four 3 2
> class(read.table(“test.txt3″, sep=”,”, as.is=T)[,1])
[1] “character”
> class(read.table(“test.txt3″, sep=”,”, as.is=T)[,3])
[1] “integer”
Możesz zobaczyć różnicę między brakiem ustawienia as.is a ustawieniem as.is na TRUE. Plik test3.txt jest plikiem w tym samym folderze co obszar roboczy, ma postać macierzową i zawiera dane zarówno w postaci znaków, jak i liczb całkowitych. Te trzy funkcje mogą odczytywać niektóre typy danych atomowych: logiczne, numeryczne, złożone i znakowe. Ze strony pomocy języka R dla trzech funkcji, R odczytuje dane jako dane znakowe, a następnie konwertuje ze znaku na jedną z klas logicznych, całkowitych, numerycznych, zespolonych lub współczynników. Jak wspomniano powyżej, jeśli as.is ma wartość TRUE, kolumny zawierające dane znakowe nie są konwertowane na współczynniki, ale zachowują znak klasy. Argument as.is można również wprowadzić jako wektor logiczny z wartością dla każdej kolumny. Można również wprowadzić krótszy wektor, z wartościami cyklicznymi w kolumnach. Argument colClasses ręcznie ustawia klasę każdej kolumny i może być używany zamiast as.is, aby utrzymać kolumnę w trybie znakowym. Możliwe wartości klas kolumn to NA, NULL, logiczne, całkowite, numeryczne, zespolone, nieprzetworzone, znakowe, współczynniki, Date lub POSIXct. Wartości są cytowane, z wyjątkiem NA i NULL, i są wprowadzane jako wektor. Wartości będą się zmieniać. Jeśli wartość to NA, nastąpi normalna konwersja. W przeciwnym razie, jeśli to możliwe, elementy kolumny są przekształcane do klasy wymienionej dla kolumny. Na przykład:
> read.table(“test2.txt”, colClasses=c(“character”,”factor”,NA,NA))
V1 V2 V3 V4
1 one 3 5 7
2 two 4 6 8
> class(read.table(“test2.txt”, colClasses=c(“character”,”factor”,NA,NA))
[,1])
[1] “character”
> class(read.table(“test2.txt”, colClasses=c(“character”,”factor”,NA,NA))
[,2])
[1] “factor”
> class(read.table(“test2.txt”, colClasses=c(“character”,”factor”,NA,NA))
[,3])
[1] “integer”
Argumenty row.names i col.names służą do nadawania nazw wierszom i kolumnom data.frame.
W przypadku row.names argumentem może być wektor znakowy o długości równej liczbie wierszy w data.frame; argument może być liczbą całkowitą określającą, która kolumna w data.frame ma być używana jako nazwy wierszy; lub argument może być wartością znakową zawierającą nazwę kolumny, która ma być używana jako nazwy wierszy. Nazwy wierszy nie zmieniają się. W przypadku nazw kolumn argumentem jest wektor znakowy nazw kolumn. Wektor musi mieć taką samą długość, jak liczba kolumn. Jeśli nazwy kolumn nie są określone, a nagłówek ma wartość FALSE, wówczas kolumny otrzymują nazwy V1, V2,…, Vn, gdzie n to numer ostatniej kolumny. Jeśli nagłówek ma wartość TRUE, a pierwsza kolumna nie ma nazwy, podczas gdy reszta kolumn ma, to R ustawia pierwszą kolumnę jako nazwy wierszy. Oto kilka przykładów:
Do macierzy
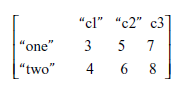
który jest plikiem test5.txt, przykładem jest
> read.table(“test5.txt”, header=T)
c1 c2 c3
one 3 5 7
two 4 6 8
Zauważ, że nagłówek ma wartość PRAWDA, aw pierwszej kolumnie jest o jeden wiersz mniej. W przypadku macierzy składającej się z dwóch drugich wierszy test5.txt, zwanych test6.txt, mamy następujący przykład:
> read.table(“test6.txt”, col.names=c(“c1″,”c2″,”c3″,”c4”), row.names=2)
c1 c3 c4
3 one 5 7
4 two 6 8
Cztery nazwy są przypisane do czterech kolumn, a następnie druga kolumna jest używana do nazw wierszy, podczas gdy inne kolumny zachowują przypisane nazwy. Istnieje kilka innych argumentów dla funkcji read.table (), read.csv () i read.delim (). Pełny opis funkcji można znaleźć, wpisując? Read.table w wierszu polecenia R.
