Uzasadnienie i reprezentacja
Rozumowanie niemonotoniczne lub niemoŋliwe do uzasadnienia
Ci badacze AI zwani logikami, którzy preferują uŋywanie języków logicznych do reprezentowania wiedzy i stosowanie metod logicznych do rozumowania, uznają jeden problem ze zwykģą logiką; mianowicie jest monotoniczny. Oznacza to, ŋe zestaw logicznych wniosków, które moŋna wyciągnąæ z zestawu instrukcji logicznych, nie zmniejsza się, gdy do zestawu dodaje się więcej instrukcji. Gdyby moŋna byģo udowodniæ stwierdzenie z danej bazy wiedzy, moŋna by udowodniæ to samo stwierdzenie (z tym samym dowodem!), Gdy dodana jest większa wiedza. Jednak wydaje się, ŋe wiele ludzkich rozumowaņ nie dziaģa w ten sposób - fakt dobrze zauwaŋony (i doceniony) przez krytyków AI. Często dochodzimy do wniosku na podstawie faktów, które mamy, wraz z rozsądnymi zaģoŋeniami, a następnie musimy wycofaæ ten wniosek, gdy dowiadujemy się o nowym fakcie, który jest sprzeczny z zaģoŋeniami. Ten sposób rozumowania nazywany jest niemonotonicznym lub niemoŋliwym do zaakceptowania (co oznacza, ŋe "moŋna go uczyniæ lub uznaæ za niewaŋny"), poniewaŋ nowe fakty mogą wymagaæ wycofania czegoķ, co zostaģo wczeķniej zawarte. Moŋna nawet znaležæ przykģady niemonotonicznego rozumowania w opowieķciach dla dzieci. W "To dobrze! To žle!", autorstwa Margery Cuyler, maģy chģopie wzbija się wysoko w niebo, trzymając balon, który rodzice kupili mu w zoo. "Wow! Och, to dobrze" - opowiada historia. Balon pęka na gaģęzi wysokiego, kģującego drzewa. "Pop! Och, to žle" - kontynuuje historia. Chģopiec wpada do bģotnistej rzeki, wspina się na hipopotama i jedzie na brzeg. "Oh to dobrze." Historia toczy się w ten sposób - zmieniając w kóģko, czy jazda balonem okazuje się "dobra" czy "zģa". W sztucznej inteligencji (i innych dziedzinach informatyki) istniaģy juŋ pewne metody uzasadnienia. Na przykģad w języku rozwiązywania problemów PLANNER zaproponowanym przez Carla Hewitta, jeķli cel, powiedzmy G, nie mógģby zostaæ osiągnięty przez program, wówczas nie moŋna byģo twierdziæ, ŋe Not G (przy zaģoŋeniu, ŋe G byģo stwierdzeniem, ŋe program próbowaģ ustaliæ). Takie rozumowanie jest niemoŋliwe do uniknięcia, poniewaŋ jeķli póžniej do programu zostaną dodane dodatkowe instrukcje lub do jej bazy wiedzy, wówczas ustalenie G moŋe staæ się moŋliwe. Podobnie w języku programowania PROLOG, jeķli program nie mógģ udowodniæ instrukcji, to uznano ją za faģszywą. Wnioskowanie, ŋe coķ jest faģszywe, jeķli nie moŋna tego udowodniæ, nazywa się "negacją jako poraŋką". System planowania SRI, STRIPS, byģ takŋe rodzajem niemonotonicznego systemu wnioskowania. Zaģoŋenia dotyczące rzeczy "pozostających niezmienionych" po wykonaniu dziaģaņ byģy z pewnoķcią wģaķnie tym - zaģoŋeniami. Wnioski wyciągnięte po dokonaniu takich zaģoŋeņ mogą zostaæ odrzucone po dodaniu nowych informacji, których implikacje mogą negowaæ te zaģoŋenia. W ķwiecie baz danych zastosowano inną metodę niemoŋliwego do uzasadnienia. Bazy danych są uŋywane do kodowania szerokiej gamy informacji. Na przykģad firma moŋe mieæ bazę danych o swoich pracownikach. Moŋna zapytaæ o taką bazę danych, aby znaležæ wynagrodzenie pracownika, dziaģ, w którym on lub ona pracuje i tak dalej. Zaģóŋmy, ŋe próbujemy znaležæ w jednej z tych baz danych pracowników informacje o osobie, powiedzmy Jack Smith, której nazwiska nie ma w bazie danych. Moŋemy zatem rozsądnie dojķæ do wniosku, ŋe Pan Smith nie jest pracownikiem tej firmy i tak zrobiliby niektóre systemy baz danych. Wniosek ten byģby oparty na zaģoŋeniu, ŋe baza danych wymienia wszystkich pracowników tej firmy {przykģad tzw. Zaģoŋenia ķwiata zamkniętego (CWA). Oczywiķcie Jack Smith moŋe póžniej doģączyæ do firmy, a następnie jego nazwisko zostanie dodane do bazy danych. W tym czasie musielibyķmy cofnąæ wniosek, ŋe Jack Smith nie jest jednym z pracowników firmy; to kolejny przykģad niemoŋliwego do uzasadnienia rozumowania. Moŋecie sobie przypomnieæ, ŋe juŋ w 1964 r. System SIR Bertrama Raphaela zawieraģ styl niemoŋliwego do uzasadnienia, który nazwaģ "zasadą wyjątku". W SIR: ogólna informacja o wszystkich elementach zestawu zastosowanych do poszczególnych elementów {ale tylko przy braku bardziej szczegóģowych informacji o tych konkretnych elementach. Kilka schematów reprezentacji wiedzy AI przedstawia częķæ swojej wiedzy w "hierarchiach taksonomicznych", podobnie jak ten, którego uŋyģ Raphael, i uŋywa zasady wyjątku, która obecnie jest często nazywana "anulowaniem dziedziczenia" z niemoŋliwego do uzasadnienia. Na rysunku pokazano hierarchię taksonomiczną niektórych maszyn biurowych.
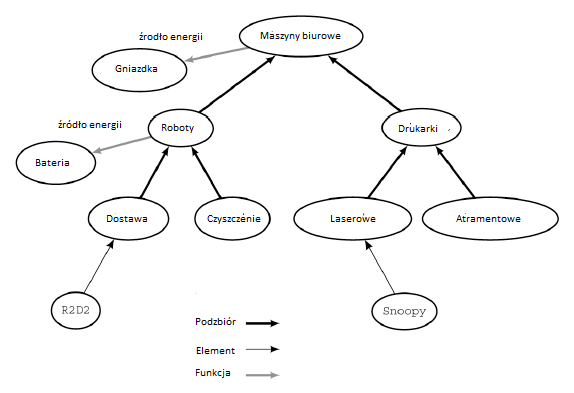
Program wykorzystujący tę hierarchię stwierdziģby, ŋe žródģem energii drukarki laserowej jest na przykģad gniazdko ķcienne, poniewaŋ ta wģaķciwoķæ jest dziedziczona z ogólnej klasy "maszyn biurowych". Jednak bardziej szczegóģowe informacje o žródle energii dla robotów zmusiģyby do wniosku, ŋe žródģem energii na przykģad dla R2D2 jest bateria, przesģaniająca dziedziczenie wģaķciwoķci ogólnej klasy maszyn biurowych. W latach 80. niektórzy z najbardziej kreatywnych badaczy AI stali się zafascynowani problemem niemoŋliwego do uzasadnienia rozumowania i przedstawiģ kilka nowych propozycji, jak to zrobiæ. Ich propozycjom towarzyszyģa wiele analiz teoretycznych porównujących i kontrastujących ze sobą róŋne podejķcia oraz tego, jak niektóre z nich moŋna uznaæ za specjalizacje lub uogólnienia innych. Kanadyjski badacz AI Raymond Reiter zaproponowaģ jedną z nowych metod. W najprostszej formie wykorzystuje specjalne reguģy wnioskowania, które pozwalają wyciągaæ wnioski z bazy wiedzy, jeķli speģniony jest okreķlony warunek i jeŋeli wnioskowi temu nie przeczy to, co zwykle moŋna wywnioskowaæ z tej bazy wiedzy. Specjalne reguģy wnioskowania Reitera nazywane są reguģami domyķlnymi, a jego system, który ich uŋywa, nazywa się logiką domyķlną. Jako przykģad jego zastosowania zaģóŋmy, ŋe mamy bazę wiedzy uŋywaną przez robota, która okreķla, do których pomieszczeņ w budynku biurowym moŋe wejķæ robot. Moŋemy mieæ reguģę, która mówi, ŋe w przypadku pomieszczeņ na drugim piętrze, jeķli nie moŋna udowodniæ, ŋe robot nie moŋe wejķæ do pokoju, moŋna dojķæ do wniosku, ŋe robot moŋe wejķæ do tego pokoju. Ponownie, rozumowanie jest nie do przyjęcia, poniewaŋ ktoķ moŋe póžniej dodaæ do bazy wiedzy fakt, który pozwala wnioskowaæ, ŋe do pokoju na drugim piętrze nie moŋna wejķæ. John McCarthy, pomysģodawca wniosku, ŋe wiedza powinna byæ zakodowana jako logiczne stwierdzenia, byģ równieŋ zaniepokojony problemem niemonotonicznoķci. Aby poradziæ sobie z tym problemem, zaproponowaģ metodę o nazwie opis. Opis jest raczej trudny do wyjaķnienia bez uŋycia logicznego ŋargonu. Zasadniczo jego wersja zwana "orzeczeniem obwodowym" (tylko jedna z kilku wersji opisu) obejmuje ograniczenie (a więc "opisanie") zbioru bytów, które sprawiają, ŋe predykaty są prawdziwe tylko do tych, które moŋna udowodniæ, ŋe są prawdziwe. Na przykģad, jeķli mamy bazę wiedzy, która zawiera takie stwierdzenia jak Tall (John) i Tall (Frank), a takŋe wiele innych faktów, moŋemy ograniczyæ (jeķli chcemy) predykat Tall. Takie postępowanie pozwala nam stwierdziæ: Wysoki (Susy), jeķli Wysoki (Susy) nie jest logicznie implikowany przez bazę wiedzy. Jedną z motywacji zainteresowania McCarthy'ego niemonotonicznym rozumowaniem byģa moŋliwoķæ, ŋe będzie to klucz do rozwiązania problemu ramowego. Przypomnij sobie, ŋe problem z ramką dotyczy trudnoķci w przedstawieniu, które rzeczy się zmieniają, a które nie zmieniają się po podjęciu dziaģania (np. Przez robota). Jednym z podejķæ jest przyjęcie takiego zaģoŋenia jeķli orzeczenie opisujące jakiķ stan ķwiata nie jest wspomniane w opisie dziaģania (w tym warunków wstępnych i efektów dziaģania), wówczas orzeczenie to nie jest zmieniane przez dziaģanie. To zaģoŋenie jest niemonotoniczne, poniewaŋ póžniejsze (lub bardziej szczegóģowe) informacje mogą sugerowaæ, ŋe nie wymieniony predykat rzeczywiķcie zostaģ zmieniony. Niektóre wczesne próby rozwiązania problemu z ramą za pomocą niemonotonicznego wnioskowania napotkaģy róŋne trudnoķci techniczne (które są zbyt techniczne, aby się tym zajmowaæ), ale prace byģy kontynuowane. Niedawny artykuģ twierdziģ, ŋe "Problem z ramą w pierwotnym brzmieniu zostaģ rozwiązany za pomocą podejķæ Shanahana i Thielschera oraz ŋe przynajmniej logiczny rozdziaģ Problemu z ramą zostaģ zamknięty" .(Dwie wspomniane osoby to Murray Shanahan z Imperial College, Londyn i Michael Thielscher z Uniwersytetu Technicznego w Drežnie.) Byæ moŋe nie zauwaŋyģeķ, ŋe wiele propozycji niemonotonicznego rozumowania jest raczej podobnych, ale istnieje wiele subtelnych róŋnic technicznych. Są nawet inne propozycje, o których nie wspomniaģem, w tym logiki autoepistemiczne, logiki niemonotoniczne, rozumowanie uprowadzające, systemy utrzymywania prawdy oraz metody oparte na teorii prawdopodobieņstwa. Tę obfitoķæ niemoŋliwych do uzasadnienia metod wnioskowania moŋna prawdopodobnie przypisaæ kreatywnoķci i matematycznemu wyrafinowaniu wielu zaangaŋowanych badaczy AI i ich bystroķci umiejętnoķci dostrzegania i próbowania wymykania się ograniczeniom wzajemnych propozycji.
Uzasadnienie jakoķciowe
Wielu z was prawdopodobnie uczestniczyģo w kursach fizyki, w liceum, na studiach lub w obu. Zadaniem fizyki jest budowanie teorii ķwiata fizycznego, a teorie te są zwykle formuģowane przy uŋyciu matematyki. Na przykģad wzór F = Ma wiąŋe siģę F dziaģającą na obiekt z masą obiektu M i jego przyspieszeniem a. Wiele wzorów matematycznych opisujących procesy fizyczne jest bardziej zģoŋonych. Na przykģad do obliczenia prędkoķci fali wodnej moŋna uŋyæ następującego "równania falowego":

Inŋynierowie mogą na przykģad uŋyæ go do przewidzenia, kiedy szczyt fali przejdzie przez okreķlony punkt. My, ludzie, jesteķmy w stanie przewidzieæ, z przydatnymi dokģadnoķciami, przyszģy przebieg wielu procesów fizycznych, których zwykle doķwiadczamy. Na przykģad, gdy ludzie bawią się w fale oceanu na plaŋy, zwykle są w stanie przewidzieæ, kiedy nadejdzie szczyt fali, aby mogli skoczyæ w czasie. Czy nasze mózgi uŋywają czegoķ takiego jak pokazane równanie, aby dokonaæ takiej prognozy? Prawdopodobnie nie. Zamiast tego, na podstawie powtarzalnych doķwiadczeņ uczą się rutynowe przewidywanie prowadzenia odpowiednich dziaģaņ. Są one częķcią tego, co psychologowie nazywają "wiedzą proceduralną". Oprócz dziaģania w sposób automatyczny i efektywny, wykorzystując wiedzę proceduralną zawartą w naszych róŋnych umiejętnoķciach motorycznych, moŋemy równieŋ skģadaæ deklaratywne stwierdzenia przewidujące, co stanie się w pewnych sytuacjach. Na przykģad surfer spoglądający na nadchodzące fale moŋe powiedzieæ przyjacielowi: "Wež następną falę; to będzie duŋa". Najwyražniej mamy jakąķ ģatwoķæ do reprezentowania i wykorzystywania "jakoķciowej wiedzy" na temat procesów fizycznych - wiedzy, która nie jest ani częķcią naszej procedury \ pamięci mięķniowej, ani teŋ nie jest reprezentowana w naszych mózgach za pomocą skomplikowanych wzorów matematycznych. Mógģbym podaæ kilka przykģadów. Skąd to wiemy kiedy przewrócimy szklankę wody na stóģ, woda ostatecznie dojdzie do krawędzi stoģu i rozleje się OFF? Skąd wiemy, ŋe jeķli uģoŋymy cięŋkie pudģa na lekkich, delikatnych pudģach, delikatne pudģa mogą się zapaķæ? Skąd wiemy, ŋe jeķli dotrzemy do celu nieco szybciej, dotrzemy tam nieco wczeķniej? Kilku badaczy AI pracowaģo nad systemami posiadającymi zdolnoķæ reprezentowania i rozumowania za pomocą wiedzy jakoķciowej. Scott Fahlman napisaģ taki program do swojej pracy magisterskiej, gdy byģ studentem MIT. Program o nazwie BUILD byģ w stanie zaplanowaæ ukģadanie klocków zabawek, biorąc pod uwagę róŋne siģy dziaģające na bloki, takie jak grawitacja i tarcie. zrobiģ to w sposób bardziej lub mniej jakoķciowy niŋ przy uŋyciu dokģadnych modeli matematycznych. Tak więc BUILD moŋna uznaæ za jedną z pierwszych prób sztucznej inteligencji w zakresie wnioskowania jakoķciowego na temat fizyki. Niedģugo potem inny student MIT, Johan de Kleer , napisaģ program o nazwie NEWTON w swojej pracy magisterskiej, który zawieraģ komponent zdolny do rozumowania jakoķciowego. NEWTON, jak twierdzi de Kleer, "rozumie i rozwiązuje problemy w mechanicznym mini-ķwiecie obiektów poruszających się po powierzchniach". NEWTON wykorzystaģ swoją jakoķciową wiedzę na temat fizyki do opracowania przybliŋonych rozwiązaņ problemów, które następnie wykorzystaģ do planowania i przeprowadzania kolejnych obliczeņ iloķciowych. Większoķæ nauczycieli fizyki powie ci, ŋe jakoķciowe rozumowanie na temat "fizyki" problemu jest niezbędne przed zanurzeniem się w matematyce. Robiąc rozumowanie jakoķciowe, NEWTON wykorzystaģ proces o nazwie "przewidywanie" do "generowania postępu scen zakodowanych w symbolicznym opisie opisującym to, co moŋe się zdarzyæ". Wykorzystano opisy szeķciu podstawowych dziaģaņ odpowiednich do rodzajów problemów, które NEWTON mógģ rozwiązaæ. Jeden z tych opisów dotyczy na przykģad FLY. Zakodowaģ on wiedzę, ŋe "jeķli obiekt porusza się po powierzchni wklęsģej od ruchu, obiekt moŋe się od niego oderwaæ". Gģównym wkģadem de Kleera byģo pokazanie, w jaki sposób obliczenia jakoķciowe i rozumowanie iloķciowe moŋna poģączyæ w programie komputerowym. W 1979 r. Pat Hayes opublikowaģ "Manifest naiwnej fizyki". "Zmieniona wersja pojawiģa się w 1985 r. Zaproponowaģ, aby spoģecznoķæ badająca sztuczną inteligencję rozpoczęģa" budowę formalizacji sporej częķci zdrowego rozsądku wiedzy o codziennym ķwiecie fizycznym: o przedmiotach, ksztaģcie, przestrzeni, ruchu, substancjach (ciaģach staģych i cieczach), czasie itp. "Tematy te od dawna stanowiģy szczególnie trudne wyzwania dotyczące reprezentacji i rozumowania dla sztucznej inteligencji. Kodowanie naszej codziennej wiedzy na te tematy, aby komputery mogģy je zrozumieæ, jest w sercu fizyki jakoķciowej, którą Hayes nazwaģ "fizyką naiwną". Jego manifesty przedstawiaģy kilka ogólnych pomysģów na temat tego, jak reprezentowaæ "skupiska" zdrowego rozsądku na temat ķwiata fizycznego. Jako przykģad zaproponowaģ pojęcie "historii" do reprezentowania wydarzeņ, zamiast stanów i funkcji paņstw, jak wczeķniej opowiadaģ się on i John McCarthy. Okreķliģ historię jako "czasoprzestrzeņ z naturalnymi granicami, zarówno czasowymi, jak i przestrzennymi". "Na przykģad" zdarzenie polegające na zģoŋeniu czterech bloków w kwadrat jest początkiem historii platformy i jej koņcem. historia jest wtedy, gdy i gdzie są one oddzielone od siebie. "Hayes powiedziaģ w efekcie, ŋe nie powinniķmy byæ" zbyt pochopni "w pisaniu naiwnych programów fizyki {woląc zamiast tego opóžniaæ wdraŋanie, dopóki nie zostaną wykonane bardziej fundamentalne prace nad samymi reprezentacjami Naszkicowaģ juŋ częķæ tej pracy na cieczach. Te wstępne eksploracje w rozumowaniu jakoķciowym wkrótce doprowadziģy do szybko rozwijającego się obszaru sztucznej inteligencji o wielu zastosowaniach, zwģaszcza w diagnozowaniu usterek na podstawie jakoķciowych modeli sprzętu. Wybitne grupy zostaģy utworzone przez profesora Kennetha D. Forbusa z Northwestern University i Benjamina Kuipersa z University of Teksas w Austin. (Kuipers przeprowadziģ się teraz na University of Michigan). Pojawiģy się specjalne wydania czasopism oraz zredagowanych tomów i ksiąŋek poķwięconych temu tematowi. Zakoņczę ten rozdziaģ dotyczący rozumowania i reprezentacji, przechodząc obok nowych osiągnięæ w zakresie wykorzystania sieci semantycznych do reprezentacji wiedzy.
Sieci semantyczne
We wczeķniejszej dyskusji na temat niemoŋliwego do zrozumienia rozumowania pokazano sieæ semantyczną reprezentującą taksonomiczną hierarchię maszyn biurowych. sieci taksonomiczne są szeroko stosowane w sztucznej inteligencji i informatyce do reprezentowania tak zwanych "ontologii". W sztucznej inteligencji ontologia skģada się z zestawu pojęæ i relacji między tymi pojęciami. (W filozofii oznacza to badanie bytu lub istnienia). Systemy AI do wnioskowania za pomocą tych sieci zwykle miaģyby mechanizmy dziedziczenia wģasnoķci przy uŋyciu zasad wyjątków. Chociaŋ najlepiej rozumiemy sieci taksonomiczne, myķląc o nich w formie drzew, to w tym przypadku stosuje się zbiór specjalnych struktur danych kodowanie ich dla komputerów. Struktury te są często nazywane "ramkami" po oryginalnym uŋyciu tego sģowa przez Minsky′ego. Na przykģad jedną z ram dla sieci maszyn biurowych moŋna przedstawiæ jak na rysunku

Zazwyczaj istnieje ramka dla kaŋdej klasy osób lub podmiotów w taksonomii, a takŋe dla kaŋdej z tych jednostek. Ramki dla klas nazwaliby nadklasę, do której naleŋaģa, i naleŋące do niej podklasy. Okreķliģby takŋe wģaķciwoķci podmiotów naleŋących do klasy. Często zdarza się, ŋe ramka ma "meta-informacje", takie jak data utworzenia ramki.
Opis Logika
Wczeķniej w historii AI istniaģy kontrowersje dotyczące tego, czy wiedza powinna byæ reprezentowana przez struktury danych, takie jak sieci semantyczne (zakodowane, powiedzmy, jako ramki), czy przez zestawy instrukcji logicznych. Stopniowo kontrowersje ģagodziģy się, poniewaŋ naukowcy zaczęli akceptowaæ ideę, ŋe sieci semantyczne moŋna traktowaæ jako specjalny sposób reprezentowania pewnych rodzajów logicznych stwierdzeņ, umoŋliwiając w ten sposób dokonywanie pewnych dedukcji bezpoķrednio z sieci. Dwóch badaczy, którzy pomogli ustaliæ ten pogląd, to Ronald J. Brachman i Hector J. Levesque. (Kaŋdy z nich wykonaģ równieŋ powiązane prace podstawowe w zakresie reprezentacji wiedzy i ogólnego rozumowania.
Brachman zrobiģ doktorat w Harvardzie pod kierunkiem Billa Woodsa. (Oprócz pracy w przetwarzaniu języka naturalnego, Woods pisaģ takŋe o związku między sieciami semantycznymi a logiką.) Rozwijając pomysģy w swojej pracy, Brachman wraz z innymi kolegami z BBN (w tym Woods) i USC-ISI, opracowaģ oparty na ramkach system reprezentacji wiedzy o nazwie KL-ONE, który staģ się podstawą tak zwanej logiki opisu. Levesque wykonaģ caģą pracę w collegeu (B.S., M.S. i doktorat) na University of Toronto. Po otrzymaniu stopnia doktora dyplom w 1981 r. doģączyģ do Brachmana w Fairchild Laboratory for Artiial Intelligence Research w Palo Alto, grupie zaģoŋonej przez Petera Harta po odejķciu Hart z SRI. Tam Brachman i Levesque wraz z Richardem Fikessem (wówczas w Xerox PARC) opracowali system reprezentacji i rozumowania KRYPTON. KRYPTON byģ systemem hybrydowym - co oznacza, ŋe reprezentowaģ wiedzę zarówno za pomocą formuģ logicznych, jak i sieci semantycznej. Chociaŋ sieci semantyczne uģatwiają rozumowanie osób i ich wģaķciwoķci w hierarchii, trudno im reprezentowaæ stwierdzenia zawierające negacje i rozbieŋnoķci. Jak stwierdza papier KRYPTON, "… oķwiadczenie takie jak "Elsie lub Bessie jest krową stojącą w polu Farmera Jonesa" nie moŋe byæ sformuģowane w typowym systemie asercyjnym" .Rozwiązaniem KRYPTON jest uŋycie kombinacji obu rodzajów reprezentacji:
podzieliliķmy [ rozumowanie] na dwa osobne rodzaje, uzyskując dwa gģówne komponenty dla naszego systemu reprezentacji: terminologiczny [to znaczy oparty na sieci] lub T Box oraz asercjonalny [to znaczy oparty na logice] lub A Box. T Box pozwala nam ustalaæ taksonomie ustrukturyzowanych terminów i odpowiadaæ na pytania dotyczące analitycznych relacji między tymi terminami; A Box pozwala nam budowaæ opisowe teorie domen zainteresowaņ i odpowiadaæ na pytania dotyczące tych domen. Schemat z papieru KRYPTON przedstawiony na ryc. 26.4 ilustruje budowę ukģadu.
Jak napisali autorzy, skģada się on z "T-Boxa ustrukturyzowanych terminów zorganizowanych taksonomicznie, A-Box z (z grubsza) zdaņ pierwszego rzędu, których predykaty pochodzą z T-Box, oraz tablicy symboli z nazwami terminów T-Box aby uŋytkownik mógģ się do nich odwoģaæ ". Pole T na schemacie reprezentuje (między innymi), ŋe dziecko jest osobą. A Box stwierdza, ŋe istnieje lekarz, który ma dziecko. KRYPTON byģ prekursorem kilku systemów opisowych, w tym CLASSIC, opracowanych przez Brachmana i wspóģpracowników po przejķciu do AT&T Bell Laboratories. Oprócz ich zastosowania w systemach wnioskowania AI, logiki opisu są uŋywane w językach ontologii dla sieci semantycznej, na przykģad DAML-ONT23 i OWL.
WordNet
WordNet to duŋy "konceptualny" sģownik angielskich sģów, zorganizowany nieco jak sieæ semantyczna i zainspirowany psycholingwistycznymi i obliczeniowymi teoriami ludzkiej pamięci leksykalnej. Jego rozwój rozpocząģ się na Uniwersytecie Princeton w latach 80. pod kierunkiem profesora George′a A. Millera (tego samego George′a Millera, o którym wspominaģem wczeķniej i który napisaģ "The Magical Number Seven, Plus or Minus Two "). W artykule z 1990 roku Miller i jego koledzy powiedzieli o początkach projektu:
"W 1985 r. Grupa psychologów i lingwistów z Princeton University zobowiązaģa się do opracowania leksykalnej bazy danych zgodnie z sugestiami z wczeķniejszych badaņ [psycholingwistycznych]. Pierwotnym pomysģem byģo zapewnienie pomocy w wyszukiwaniu sģowników pojęciowo, a nie tylko alfabetycznie {miaģ byæ uŋywany w poģączeniu ze sģownikiem on-line konwencjonalnego typu. W miarę upģywu czasu praca wymagaģa jednak bardziej ambitnego sformuģowania wģasnych zasad i celów. WordNet jest wynikiem. Poniewaŋ WordNet tworzy hipotezy oparte na wynikach badaņ psycholingwistycznych, moŋna powiedzieæ, ŋe jest sģownikiem opartym na zasadach psycholingwistycznych."
WordNet grupuje sģowa w kolekcje zwane "synsetami". Kaŋdy zestaw zawiera grupę sģów synonimicznych, to znaczy sģów o mniej więcej tym samym znaczeniu. Korzystam z narzędzia wyszukiwania online WordNet, aby podaæ przykģady synchronizacji i relacji między nimi. Na przykģad sģowo "komputer" występuje w dwóch róŋnych zestawach. Jeden z tych synsetów zawiera, oprócz "komputera", maszyny komputerowej "synonimy", "urządzenia komputerowego", "procesora danych", "komputera elektronicznego" i "systemu przetwarzania informacji". Drugi zestaw synonimów zawiera synonimy dla starszych zastosowaņ sģowo "komputer" (gdy odnosi się do ludzi wykonujących obliczenia), a mianowicie "kalkulator", "licznik", "gurer" i "estymator". Synsetowi moŋe takŋe towarzyszyæ skrót, zwany " poģysk ", który nadaje znaczenie sģowom w synsecie. W przypadku pierwszego zestawu poģysk to" urządzenie do automatycznego wykonywania obliczeņ. "Po drugie, poģysk to" ekspert w dziedzinie obliczeņ (lub obsģugi maszyn liczących) "Czasami poģysk zawiera takŋe przykģadowe zdanie ilustrujące typowe uŋycie. Synsety są poģączone z innymi synsetami za pomocą relacji podobnych do tych uŋywanych w sieci semantycznej. Jedna taka relacja nazywana jest "hipernym", odpowiadającym (z grubsza) "rodzajowi". Na przykģad, nasz synset zawierający "komputer" i "urządzenie komputerowe" itp. jest synsetem zawierającym sģowo "maszyna" (i ewentualnie takŋe inne sģowa) o poģysku "dowolne urządzenie mechaniczne lub elektryczne, które transmituje lub modyfikuje energia do wykonania lub pomocy w wykonywaniu ludzkich czynnoķci. " "Hiponim", odpowiadający (z grubsza) "jest ogólnym przypadkiem", jest przeciwieņstwem hipernymu. Wspomniany wczeķniej zestaw "komputerowy" ma kilka hiponimów, między innymi zawierające sģowa "komputer cyfrowy" i dowolny z jego synonimów (komputer, który reprezentuje informacje za pomocą cyfr numerycznych), "moduģ liczbowy" i dowolny z jego synonimów (komputer zdolny do wykonywania duŋej liczby operacji matematycznych na sekundę), "maszynę Turinga" i dowolny z jego synonimów (hipotetyczny komputer z prawie dģugą taķmą pamięci) i inne. Istnieją równieŋ inne relacje. W przypadku synsetów zawierających rzeczowniki istnieje relacja zwana "meronimem" odpowiadająca "ma jako częķci". Synset zawierający "komputer" i "urządzenie komputerowe" itp. Ma kilka meronimów, wķród nich te zawierające sģowa "chip" i jego synonimy (wszystkie z poģyskliwym "sprzętem elektronicznym skģadającym się z maģego krysztaģu póģprzewodnika krzemowego wykonanego z realizują szereg funkcji elektronicznych w ukģadzie scalonym "), "monitorze"i jego synonimach (wszystkie z poģyskiem" wyķwietlacza wytwarzanego przez urządzenie, które odbiera sygnaģy i wyķwietla je na ekranie telewizyjnym lub monitorze komputera ") oraz kilka inni "Holonim" jest przeciwieņstwem meronimu. Kaŋdy synset wspomina takŋe częķæ mowy zawartych w nim sģów: rzeczownik, czasownik, przymiotnik lub przysģówek. Relacje między synsetami róŋnią się nieco w zaleŋnoķci od częķci mowy. Na przykģad, zestawy czasowników mają relację zwaną "pociąganiem". Na przykģad jeden z synsetów czasownika "chodziæ" (poruszaæ się nogami; krok po kroku) pociąga za sobą synset zawierający czasownik "krok" (przesunięcie lub ruch wykonując krok). Wedģug strony internetowej (w chwili pisania tego tekstu) WordNet zawiera 155 287 sģów i 117 659 synsetów. Jest utrzymywany i rozwijany w Princeton i jest dostępny bezpģatnie do publicznego pobrania. Oprócz wykorzystania jako sģownika online i tezaurusa, jest on uŋywany do wspierania automatycznej analizy tekstu, w aplikacjach do przetwarzania języka naturalnego, jako baza wiedzy do odpowiedzi na pytania oraz w semantycznych aplikacjach internetowych. Podobne "sieci sģowne" zostaģy utworzone w kilkudziesięciu innych językach. Zastosowanie WordNet jako ontologii w bazie wiedzy taksonomicznej zaleŋy od relacji hipernym / hiponimu między synsetami rzeczowników i od uŋycia przez WordNet mechanizmu dziedziczenia do wnioskowania o wģaķciwoķciach obiektów reprezentowanych przez synsety na podstawie wģaķciwoķci ich przodków. Na przykģad jeden ģaņcuch (od konkretnego do ogólnego) w takiej hierarchii jest następujący:
stacja robocza → komputer cyfrowy → komputer! maszyna → urządzenie →instrumentalnoķæ → artefakt→ …
Oczywiķcie wzdģuŋ tego ģaņcucha znajdują się gaģęzie boczne (które moŋna eksplorowaæ za pomocą funkcji wyszukiwania online WordNet). Jednak niektóre modyfikacje mogą byæ potrzebne, gdy uŋywa się WordNet jako ontologii, poniewaŋ wedģug Wikipedii "… zawiera setki podstawowych niekonsekwencje semantyczne, takie jak (i) istnienie wspólnych specjalizacji dla kategorii wyģącznych oraz (ii) zwolnienia w hierarchii specjalizacji, "między innymi." W ramach powiązanego wysiģku Karin Kipper Schuler stworzyģa "VerbNet" zgodnie ze stroną internetową o VerbNet jest największym dostępnym obecnie sģownikiem czasowników online dla języka angielskiego. Jest to hierarchiczny niezaleŋny od domeny, szeroko zakrojony sģownik czasowników z odwzorowaniami na inne zasoby leksykalne, takie jak WordNet, Xtag i FrameNet. "
Cyc
W 1984 r., Zdając sobie sprawę, ŋe do wielu zastosowaņ sztucznej inteligencji potrzebna będzie duŋa wiedza ze zdrowego rozsądku, szczególnie do rozumienia języka naturalnego, profesor Stanford Douglas Lenat, który wczeķniej pracowaģ nad automatyzacją odkrywania pojęæ matematycznych i heurystyk postanowiģ podjąæ się ogromnego zadania polegającego na dostarczeniu komputerom zdrowej wiedzy. Pierwszym krokiem, pomyķlaģ, byģoby "zalanie pompy milionami codziennych terminów, pojęæ, faktów i praktycznych zasad", które zawierają zdrowy rozsądek. Jak to póžniej opisaģ, projekt rozpocząģ się w ten sposób:
"jesienią 1984 r. Admiraģ Bobby Ray Inman przekonaģ mnie, ŋe jeķli powaŋnie podchodzę do tego pierwszego kroku, muszę opuķciæ ķrodowisko akademickie i przybyæ do jego nowo utworzonego MCC (Microelectronics i Computer Consortium) w Austin w Teksasie i zebraæ zespóģ, aby to zrobiæ. Pomysģ polegaģ na tym, ŋe w ciągu następnej dekady dziesiątki osób stworzy program, Cyc, ze zdrowym rozsądkiem. "Zalewamy pompę wiedzy" ręcznie i karmimy ģyŋeczką Cyc kilkoma milionami waŋnych faktów i praktycznych zasad."
Nazwa "Cyc" (wymawiane jak "psych") pochodzi od trzech liter w ķrodku sģowa "encyklopedia". Pomysģ polegaģ na tym, ŋe jeķli Cyc miaģby wystarczającą wiedzę, aby zrozumieæ artykuģy w encyklopedii, byģby w stanie czytaæ wszystkie rodzaje materiaģów i samodzielnie zdobywaæ dodatkową wiedzę - "drugi krok" w kierunku inteligentnych komputerów. ("Trzecim krokiem" byģoby wymyķlenie i przeprowadzenie eksperymentów w celu zdobycia większej wiedzy, to znaczy wiedzy wykraczającej poza to, co ludzie juŋ wiedzą.) Aby zrozumieæ artykuģy z encyklopedii, ludzie muszą juŋ sporo wiedzieæ o ķwiecie. Jak to ująģ Lenat :
"Jeķli wežmiemy jakieķ zdanie z encyklopedii i pomyķlimy o tym, co autor zakģada, ŋe czytelnik juŋ wie o ķwiecie, będziemy mieli coķ, co warto powiedzieæ Cycowi. Alternatywnie, moŋemy zrobiæ akapit i spojrzeæ na "przeskoki" z jednego zdania do następnego i zastanówcie się, co autor zakģada, ŋe czytelnik będzie wnioskowaæ "między" zdaniami. [Rozwaŋmy na przykģad zdania] "Napoleon zmarģ na Ķwiętą Helenę. Wellington byģ bardzo zasmucony. "Autor oczekuje, ŋe czytelnik wywnioskuje, ŋe Wellington dowiedziaģ się o ķmierci Napoleona, ŋe Wellington przeŋyģ Napoleona itd."
Jak wiele wiedzy musiaģby Cykl, aby zrozumieæ artykuģy w encyklopedii? Lenat powiedziaģ niedawno, ŋe początkowo sądziģ, ŋe Cyc będzie potrzebowaģ "kilku milionów ogólnych stwierdzeņ, takich jak" ssaki mają wģosy "(plus znacznie większa liczba konkretnych faktów, takich jak to, jaka jest stolica Kalifornii)." Teraz wierzy, ŋe "liczba jest więcej niŋ 200 milionów. "Lenat i jego zespóģ programistów i" entuzjastów wiedzy "pracowali nad Cycem, ręcznie wprowadzając wiedzę przez okoģo dziesięæ lat w MCC.
Napisano kilka raportów, szereg artykuģów i ksiąŋkę opisującą projekt i jego cele. W 1994 r., Częķciowo z powodu trudnoķci w MCC, Lenat zaģoŋyģ Cycorp w Austin w Teksasie, "aby badaæ, rozwijaæ i komercjalizowaæ sztuczną inteligencję". Prace nad Cycem trwają tam pod rządami Lenata i jego personelu. Język uŋywany przez Cyc do reprezentowania wiedzy nazywa się CycL, rozszerzenie rachunku predykatów pierwszego rzędu. Klasy obiektów, o których wie Cyc, są uģoŋone w hierarchii taksonomicznej, która pozwala klasom obiektów odziedziczyæ wģaķciwoķci klas obiektów wyŋszych w hierarchii. Na przykģad w hierarchii Cyc "klasa zdarzeņ", taka jak "wģączenie wģącznika ķwiatģa", jest podklasą "rzeczy doczesnej", która jest podklasą "osoby", która jest podklasą najbardziej ogólnej klasa w Cyc, a mianowicie "rzecz". Cyc uŋywa "reguģ" (okreķlonych w języku logicznym) aby opisywaæ relacje między obiektami. Na przykģad angielska wersja jednej z jej zasad brzmi: "Dla wszystkich zdarzeņ A i B, A powoduje, ŋe B oznacza, ŋe A poprzedza B." Baza wiedzy Cyc (KB) podzielona jest na tysiące "mikro-teorii" - zbiory pojęæ i faktów na temat okreķlonego obszaru. Na przykģad jedna mikro-teoria zawiera wiedzę o geografii europejskiej. Inni poķwięcają się wiedzy eksperckiej na temat \ chemii, biologii, organizacji wojskowych, choroby i systemy uzbrojenia. "Kaŋda mikro-teoria jest spójna, chociaŋ caģa baza wiedzy Cyc, traktowana jako caģoķæ, moŋe mieæ sprzecznoķci. KB Cyc zawiera ponad miliony ogólnych twierdzeņ. Większoķæ z nich przechwytuje zdroworozsądkową wiedzę na temat" przedmioty i wydarzenia codziennego ŋycia, takie jak kupno i sprzedaŋ, relacje pokrewieņstwa, sprzęt AGD, jedzenie, budynki biurowe, pojazdy, czas i przestrzeņ. "Ponadto KB zawiera wiedzę gramatyczną i leksykalną potrzebną do przetwarzania języka naturalnego. Cyc uŋywa "silnika wnioskowania", aby wyciągaæ nowe fakty z innych istniejących faktów i reguģ w swoim KB. Stosowane są dwie gģówne metody wnioskowania, zasada wnioskowania zwana rezolucją. Aby skutecznie argumentowaæ przy pomocy rozwiązania, Cyc opracowaģ zastrzeŋoną heurystykę i ogranicza zakres swoich procesów wyszukiwania za pomocą mikro-teorii. Inną metodą wnioskowania jest dziedziczenie wģaķciwoķci, co jest powszechnie stosowane w reprezentacjach sieci semantycznej. "Cykl obejmuje równieŋ ponad 1000 moduģów wnioskowania specjalnego do obsģugi okreķlonych klas wnioskowania. Jeden taki moduģ obsģuguje rozumowanie dotyczące przynaleŋnoķci do zbioru / rozģącznoķci. Inne obsģugują rozumowanie równoķci, rozumowanie czasowe i rozumowanie matematyczne. CycL uŋywa pewnej formy omijania. … i moŋe w stosownych przypadkach skorzystaæ z zaģoŋenia zamkniętego ķwiata. " Cycorp pracuje nad kilkoma aplikacjami, w tym inteligentnym wyszukiwaniem i wyszukiwaniem informacji z sieci WWW oraz zrozumieniem języka naturalnego. Jego strona internetowa twierdzi, ŋe "jest teraz dziaģającą technologią z aplikacjami do wielu rzeczywistych problemów biznesowych". Istnieje jednak kilka uwag krytycznych dotyczących Cyc. Wpadają w kģopoty z niektórymi problemami z rozumowaniem, które są ģatwe dla ludzi. Ogromna baza wiedzy stanowi jego częķæ rozumowania jest niepraktycznie wolne (i niewątpliwie będzie jeszcze wolniejsze w miarę dodawania większej wiedzy). Nie ma satysfakcjonujących rozwiązaņ dla niektórych problemów związanych z reprezentacją, które badacze AI wciąŋ starają się rozwiązaæ - takich jak reprezentacja substancji. Ponadto, poniewaŋ większoķæ pracy nad Cyc odbywa się w warunkach prywatnych, nie jest ogólnie dostępna do oceny rówieķniczej. Chociaŋ Cyc ma pretensje do posiadania wystarczającej wiedzy, aby zrozumieæ naturalny język, nie moŋe jeszcze automatycznie (to znaczy bez interakcji uŋytkownika) odpowiednio przetģumaczyæ typowe angielskie pytania na CycL. Aby wysģaæ zapytanie do Cyc, naleŋy albo uŋyæ niewygodnego języka CycL, albo pracowaæ w interaktywny sposób. Lenat opisaģ mi praktyczny przykģad takiej interakcji zastosowanej w Cleveland Clinic, gdzie badacze medyczni uŋywają Cyc do uzyskiwania informacji z baz danych pacjentów. Badacz wpisuje zapytanie w języku angielskim. "Cyc analizuje, co moŋe, rozpoznając niektóre częķci zapytania i przedstawia uŋytkownikowi zestaw częķciowych" fragmentów "zapytania, które są jak szablony puste." Cyc następnie wykorzystuje swoją specjalistyczną wiedzę na temat medycyny oraz zdrową rozsądek, aby dowiedzieæ się, jak sparafrazowaæ zapytanie do sprawdzenia przez uŋytkownika. Po uzyskaniu zgody uŋytkownika na to, o co pytaģ uŋytkownik, wykorzystuje swoją wiedzę na temat organizacji bazy danych do generowania zapytaņ do bazy danych w celu uzyskania poŋądanych informacji. Istnieją dwie wersje Cyc dostępne do pobrania. Jeden nazywa się ResearchCyc i jest dostępny dla spoģecznoķci badawczej (wyģącznie do celów badawczych) na podstawie licencji ResearchCyc. Poza silnikiem wnioskowania Cyc zawiera prawie 3 000 000 twierdzeņ (faktów i zasad), uŋywając ponad 26 000 relacji, które są powiązane, ograniczają , a w efekcie (częķciowo) zdefiniowaæ pojęcia. "Kolejna, zwana OpenCyc, jest publicznie dostępną wersją technologii Cyc. Zawiera "setki tysięcy terminów, dģugie z milionami twierdzeņ odnoszących się do terminów wzajemnie. . . ." Moŋna równieŋ zbadaæ hierarchię pojęæ w OpenCyc za pomocą przeglądarki internetowej. Nikt nie wie dokģadnie, jak ludzie organizują i stosują zdrowy rozsądek (i ekspercka) wiedza. To, czy fakty i relacje, które zostaģy juŋ zgromadzone (a które dopiero zostaną zebrane) w ramach projektu Cyc, będą wystarczające pod względem iloķci i organizacji, aby umoŋliwiæ rozumowanie na poziomie ludzkim, muszą jeszcze zostaæ wykazane. Jednak pochwalam wysiģek i ŋyczę powodzenia temu projektowi. Z pewnoķcią uwaŋam, ŋe wymagane będzie coķ co najmniej tak ambitnego, jak Cyc. (Inną próbą zebrania zdrowego rozsądku jest wiedza z "Commonsense Computing Initiative" w MIT Media Lab. Moŋliwe, ŋe Cyc moŋe dojķæ do punktu, w którym (przy pewnej pomocy czģowieka) będzie w stanie zebraæ więcej wymaganej wiedzy bezpoķrednio z Internetu. Lenat wspomina o grze "FACTory", której celem jest pomoc w gromadzeniu wiedzy od ludzi, którzy w nią grają. W grze Cyc generuje wypowiedzi w języku naturalnym, które zgromadziģ na podstawie angielskich zdaņ znalezionych w Internecie. Przedstawia te stwierdzenia dziesięciu losowo wybranym graczom w grze. Jeķli wystarczająco duŋo z nich odpowie, ŋe stwierdzenie jest prawdziwe, "Cyc dodaje ten fakt do swojego KB (a gracze zdobywają punkty w grze). Próbowaģem gry, a Cyc zapytaģ mnie, czy "Caģa marinara spaghetti zawiera trochę czosnku . " Odpowiedziaģem "prawda", a Cyc powiedziaģ, ŋe zgadzam się z 66% pozostaģych graczy i ŋe teraz (dlatego) uwaŋa, ŋe zdanie jest "prawdziwe".