Sieci bayesowskie
Reprezentowanie prawdopodobieņstw w sieciach
Wiele ludzkich rozumowaņ dotyczy zdaņ i wielkoķci niepewnoķci. Nasze przekonania na temat wielu rzeczy jest tymczasowe (tj. mogą ulec zmianie) i kwalifikowane (to znaczy mają róŋne poziomy zaufania). Równieŋ systemy AI muszą byæ w stanie poradziæ sobie z niepewnymi informacjami. Fakty, oķwiadczenia i zasady agenta AI naleŋy jak najbardziej uznaæ za tymczasowe i kwalifikowane. W koņcu niektóre informacje są dostarczane przez ludzi, a niektóre pochodzą z czujników o ograniczonej precyzji i niezawodnoķci. Jednak większoķæ wczesnych prac w AI ignorowaģa niepewny charakter wiedzy. W rzeczywistoķci Marvin Minsky zauwaŋyģ, ŋe zawieraģ zredagowany tom wczesnych dokumentów AI "brak wyražnego uŋycia pojęæ probabilistycznych". Jednak większoķæ badaczy AI uznaje obecnie, ŋe znaczna częķæ wiedzy potrzebnej maszynom musi zostaæ skorygowana na podstawie wartoķci prawdopodobieņstwa i ŋe w związku z tym wnioskowanie z tą wiedzą moŋna najodpowiedniej przeprowadziæ za pomocą narzędzi teorii prawdopodobieņstwa. Ale podobnie jak w przypadku logicznego rozumowania, rozumowanie probabilistyczne podlega starej nemezis AI, eksplozji kombinatorycznej. Zaģóŋmy na przykģad, ŋe wiedza agenta skģada się z zestawu zdaņ. Ze względu na moŋliwe wspóģzaleŋnoķci zdaņ, dokģadne rozumowanie probabilistyczne zaleŋy od znajomoķci czegoķ więcej niŋ tylko prawdopodobieņstwa kaŋdego z tych zdaņ indywidualnie. Zamiast tego zwykle wymagane są wartoķci prawdopodobieņstwa dla róŋnych kombinacji zdaņ wziętych razem, zwane "wspólnymi prawdopodobieņstwami"; prowadzi to, w ogólnym przypadku, do niepraktycznie duŋych reprezentacji i trudnych obliczeņ. Wczeķniejsze systemy AI, które mogģy radziæ sobie z niepewnoķcią, takie jak MYCIN i PROSPECTOR, wprowadzaģy uproszczone zaģoŋenia w celu zģagodzenia tych trudnoķci reprezentacyjnych i obliczeniowych. Poniewaŋ jednak systemy te nie uwzględniaģy istotnych wspóģzaleŋnoķci między swoimi przekonaniami, często dawaģy niewģaķciwe wyniki z powodu takich rzeczy, jak przeliczanie dowodów. W latach 80. wynaleziono kilka nowych, potęŋnych metod (i zaimportowano z innych dziedzin), które lepiej radziģy sobie z zaleŋnoķciami. Metody te znacznie uproķciģy zarówno problemy reprezentacyjne, jak i obliczeniowe. Obejmują one przedstawianie niepewnych przekonaņ i ich zaleŋnoķci w formie graficznej forma, zwana "probabilistycznym modelem graficznym". Opiszę najwaŋniejszą wersję takich modeli. Po pierwsze, aby zilustrowaæ niektóre trudnoķci związane z rozumowaniem niepewnych przekonaņ i tym, jak moglibyķmy sobie z nimi poradziæ, spójrzmy na przykģad obejmujący róŋne propozycje dotyczące silnika samochodowego. Oto niektóre z nich to rzeczy, które moglibyķmy powiedzieæ o silniku i jego częķciach:
P1: Rozrusznik dziaģa prawidģowo.
P2: Rozrusznik obraca silnik, gdy rozrusznik jest wģączony.
P3: Ukģad paliwowy jest w porządku.
P4: Samochód uruchamia się po wģączeniu rozrusznika.
Te propozycje są w oczywisty sposób powiązane. Po pierwsze, P4 zaleŋy od pozostaģych trzech - smutne spostrzeŋenie, ŋe P4 jest faģszywe, z pewnoķcią zmieniģoby nasze zdanie na temat pozostaģych trzech. Co więcej, nie potrzeba mechanika samochodowego, aby wiedzieæ, ŋe P1 i P2 są powiązane. Peģny opis zaleŋnoķci tutaj zaangaŋowanych wymaga wykazu wszystkich moŋliwoķci, aby wszystko byģo w porządku i nie byģo w porządku, a istnieje szesnaķcie takich moŋliwoķci. Jeķli oznaczymy przeciwieņstwo zdania, umieszczając przed nim znak negacji (¬), wówczas ¬P1 oznacza "Rozrusznik nie dziaģa". Korzystając z tego zapisu, istnieje szesnaķcie moŋliwoķci
P1; P2; P3; P4;
P1; P2; P3; ¬P4;
P1; P2; ¬P3; P4;
P1; P2; ¬3; ¬P4;
P1; ¬P2; P3; P4;
P1; ¬P2; P3; ¬P4;
P1; ¬P2; ¬P3; P4;
P1; ¬P2; ¬P3; ¬P4;
¬P1; P2; P3; P4;
¬P1; P2; P3; ¬P4;
¬P1; P2; ¬P3; P4;
¬P1; P2; ¬P3; ¬P4;
¬P1; ¬P2; P3; P4;
¬P1; ¬P2; P3; ¬P4;
¬P1; ¬P2; ¬P3; P4;
i
¬P1; ¬P2; ¬P3; ¬P4:
Ekspert, który wie o silnikach i ich oczekiwanej niezawodnoķci, byģby prawdopodobnie w stanie przypisaæ wartoķci prawdopodobieņstwa kaŋdemu z tych szesnastu "stanów", w których ukģad silnika mógģby się znaležæ. Na przykģad ekspert moŋe okreķliæ, ŋe ogólne prawdopodobieņstwo poģączenia, ŋe wszystko jest w porządku, oznaczone przez p (P1; P2; P3; P4), wynosi 0,999. Musiaģby podaæ szesnaķcie takich liczb. (W rzeczywistoķci wystarczyģoby tylko piętnaķcie, poniewaŋ szesnaķcie musiaģoby sumowaæ się do jednego. Są to jedyne moŋliwe stany i tak musi byæ w jednym przypadku.) Znajomoķæ tych wspólnych prawdopodobieņstw umoŋliwiģaby daną osobę (posiadającą cierpliwoķæ i umiejętnoķci w teorii prawdopodobieņstwa ), aby obliczyæ pewne inne prawdopodobieņstwa, takie jak prawdopodobieņstwo, ŋe samochód uruchomi się, biorąc pod uwagę, powiedzmy, ŋe ukģad paliwowy jest zdecydowanie w porządku. Okreķlenie piętnastu liczb dla tego maģego przykģadu nie wydaje się zbyt uciąŋliwe, ale dla bardziej realistycznego problemu, powiedzmy, ŋe z trzydziestoma róŋnymi propozycjami, trzeba by podaæ 230 - 1 = 1 073,741,823 liczb. Co więcej, jeķli istnieją równieŋ wielkoķci, które mogą przyjmowaæ kilka wartoķci (oprócz zdaņ, które są wartoķciowane binarnie), liczba moŋliwoķci roķnie jeszcze bardziej. Oczywiķcie przyjąģem tutaj najgorszy przypadek, mianowicie przypadek, w którym wszystkie cztery zdania mogą się od siebie w skomplikowany sposób zaleŋeæ. Na drugim biegunie jest przypadek, w którym zdania są caģkowicie od siebie niezaleŋne. Następnie kaŋde z szesnastu prawdopodobieņstw moŋna obliczyæ za pomocą wzorów takich jak p (P1; P2; P3; P4) = p (P1) p (P2) p (P3) p (P4) (ze znakami ¬ wstawionymi zgodnie z wymaganiami) i musielibyķmy jedynie okreķlaæ prawdopodobieņstwa dla kaŋdej z czterech propozycji osobno. Mój przykģad na temat silników samochodowych znajduje się pomiędzy tymi dwoma skrajnoķciami. Podobnie jest z wieloma znacznie większymi i bardziej realistycznymi problemami. Ta "pomiędzy" jest kluczem do uczynienia bardziej prawdopodobnym rozumowania probabilistycznego. Chociaŋ statystycy wczeķniej rozpoznawali i wykorzystywali ten fakt, to Judea Pearl opracowaģ niektóre z gģównych metod reprezentacyjnych i obliczeniowych. Pearl, profesor informatyki na Uniwersytecie Kalifornijskim w Los Angeles, byģ zaskoczony kontrastem między, z jednej strony, ģatwoķcią, z jaką ludzie rozumują i wyciągają wnioski na podstawie niepewnych informacji, a z drugiej strony obliczeniami trudnoķci w powielaniu tych umiejętnoķci za pomocą obliczeņ prawdopodobieņstwa. Jak to póžniej ująģ, zacząģ od następujących przypuszczeņ:
1. Spójna zgodnoķæ między prawdopodobnym rozumowaniem [przez ludzi] a rachunkiem prawdopodobieņstwa nie moŋe byæ przypadkowa, ale zdecydowanie sugeruje, ŋe ludzka intuicja przywoģuje jakąķ surową formę obliczeņ probabilistycznych.
2. W ķwietle szybkoķci i skutecznoķci ludzkiego rozumowania, trudnoķci obliczeniowe, które nękaģy wczeķniejsze systemy probabilistyczne, nie mogą byæ bardzo fundamentalne i naleŋy je przezwycięŋyæ, dokonując wģaķciwego wyboru, upraszczając zaģoŋenia, które ludzie przechowują w swojej gģowie.
Kluczowym wkģadem Pearl byģo przekonanie o propozycjach i innych wielkoķci często moŋna uznaæ za "bezpoķrednie przyczyny" innych przekonaņ i ŋe te związki przyczynowe mogą byæ reprezentowane w strukturach graficznych, które kodują upraszczające zaģoŋenia dotyczące zaleŋnoķci między prawdopodobieņstwami. Oczywiķcie, Pearl nie byģa pierwszą, która sugerowaģa uŋycie struktur graficznych do kodowania probabilistycznego informacje. Sam wspomina o wczeķniejszych pracach. Russell i Norvig napisali, ŋe dzieģo brytyjskiego statystyka I.J. Gooda moŋna uznaæ za prekursora wspóģczesnych sieci bayesowskich… ". A fizycy wskazują na ķciķle powiązaną pracę Hansa A. Bethe. W przypadku naszego problemu z silnikiem samochodowym rodzaj wykresu, który moŋe zastosowaæ Pearl, pokazano poniŋej

Kaŋda interesująca propozycja jest reprezentowana przez "węzeģ" na wykresie. Strzaģki pokazują bezpoķredni wpģyw róŋnych zdaņ, a takŋe wskazują między nimi na pewne probabilistyczne niezaleŋnoķci. Na przykģad prawdopodobieņstwo P4 (samochód uruchamia się po wģączeniu rozrusznika) wcale nie zaleŋy od prawdopodobieņstwa P1 (silnik rozrusznika jest w porządku), jeķli juŋ wiemy (podano) P2 (silnik rozrusznika obraca się silnik, gdy zapģonnik jest wģączony) i P3 (ukģad paliwowy jest w porządku). Znajomoķæ P1 nie mówi nam nic nowego o P4, jeķli znamy juŋ P2 i P3. W języku teorii prawdopodobieņstwa prawdopodobieņstwo P4 jest warunkowo niezaleŋne od P1, biorąc pod uwagę rodziców P4, a mianowicie P2 i P3. W rzeczywistych zadaniach wnioskowania istnieje wiele takich warunkowych niezaleŋnoķci, które moŋna ujawniæ za pomocą tego rodzaju grafów przyczynowych. Uwzględnienie ich znacznie zmniejsza zģoŋonoķæ probabilistycznego rozumowania. W naszym przykģadzie silnika samochodowego zamiast piętnastu prawdopodobieņstw, które byģyby potrzebne w ogólnym przypadku, teraz potrzebujemy tylko oķmiu. Są to: prawdopodobieņstwo P4 dla P2 i P3 dla czterech róŋnych stanów P2 i P3:
p(P4 | P2; P3);
p(P4 | P2; ¬P3);
p(P4 | ¬P2; P3);
p(P4 | ¬P2; ¬P3);
prawdopodobieņstwo P2 podane P1 dla dwóch róŋnych stanów P1, mianowicie p (P2 | P1) i p (P2 | ¬ P1); oraz prawdopodobieņstwa P1 i P3, a mianowicie p (P1) i p (P3). Kaŋdy z tych zestawów wartoķci prawdopodobieņstwa jest przechowywany w tak zwanej "tabeli prawdopodobieņstwa warunkowego" (CPT) powiązanej z odpowiadającym mu węzģem w sieci. (CPT węzģa bez rodziców jest tylko bezwarunkowym prawdopodobieņstwem dla tego węzģa). Wykorzystując wynik z teorii prawdopodobieņstwa moŋna obliczyæ szesnaķcie wspólnych prawdopodobieņstw (wymaganych do dokģadnego uzasadnienia probabilistycznego) z tych oķmiu. Tak naprawdę nie dostajemy tutaj czegoķ za nic. Zamiast tego wykorzystujemy dodatkową wiedzę dostarczoną przez warunkowe niezaleŋnoķci uwidocznione przez sieæ.
Poniewaŋ reguģa Bayesa odgrywa znaczącą rolę w obliczaniu prawdopodobieņstwa róŋnych węzģów, biorąc pod uwagę prawdopodobieņstwa innych, Pearl ukuģ frazę "Bayesowskie sieci przekonaņ" (zwykle upraszczane do sieciach bayesowskich lub sieci przekonaņ) dla tego rodzaju wykresów. Okazaģo się, ŋe doķæ ģatwe jest budowanie duŋych sieci bayesowskich poprzez uwaŋne stwierdzenie, które twierdzenia bezpoķrednio wpģywają ("powoģują") na inne. Tak skonstruowane sieci są tym, co teoretycy grafów nazywają "ukierunkowanymi wykresami acyklicznymi" (DAG): "skierowanymi", poniewaŋ strzaģki wskazują od węzģów przyczyny do spowodowanych węzģów, i "acykliczne", poniewaŋ podąŋanie za strzaģkami na zewnątrz od węzģa nigdy nie prowadzi z powrotem do tego samego węzģa. Moŋna by zapytaæ, skąd pochodzą wartoķci prawdopodobieņstwa w CPT? W przypadku niektórych sieci byæ moŋe specjalista obeznany z tym, w jaki sposób niektóre zdania wpģywają na inne, moŋe byæ w stanie zgadnąæ o prawdopodobieņstwach. Takie domysģy nazywane są \ subiektywnymi prawdopodobieņstwami ", poniewaŋ opierają się na subiektywnych wyobraŋeniach eksperta o przyczynie i skutku. Jednak zdecydowanie najbardziej uŋyteczną metodą zapeģniania CPT wartoķciami jest oszacowanie ich na podstawie duŋej bazy danych rzeczywistych przypadków. Wyjaķnię, jak to się robi w następnej sekcji. Niezaleŋnie od tego, w jaki sposób są uzyskane, CPT (wraz ze strukturą sieci) są wykorzystywane w obliczeniach dotyczących wpģywu prawdopodobieņstw na niektóre węzģy w sieci innych. Obliczenia te nazywane są "wnioskowaniem probabilistycznym". Opracowano róŋne praktyczne metody obliczeniowe {nawet w przypadku doķæ duŋych sieci potrzebnych do realistycznych problemów. Bez przeprowadzania jakichkolwiek rzeczywistych obliczeņ wykorzystam sieæ maģych silników do zilustrowania trzech gģównych style wnioskowania probabilistycznego w sieciach bayesowskich. Na przykģad, jeķli na pewno wiedzieliķmy tylko, ŋe silnik rozruchowy byģ w porządku [to znaczy p (P1) = 1)], moglibyķmy obliczyæ prawdopodobieņstwo ŋe samochód się uruchomi. "Migracja" znanych wartoķci prawdopodobieņstwa w dóģ w sieci (w kierunku strzaģek) jest zwykle nazywana "rozumowaniem przyczynowym". I odwrotnie, gdybyķmy wiedzieli, ŋe samochód się nie uruchomi [to znaczy p (P4) = 0], moglibyķmy obliczyæ prawdopodobieņstwo, ŋe silnik rozrusznika jest sprawny, a ukģad paliwowy jest sprawny. Migracja wartoķci prawdopodobieņstwa w górę w sieci (w kierunku przeciwnym do strzaģek) jest zwykle nazywana rozumowaniem "dowodowym" lub "diagnostycznym". To wģaķnie robią lekarze (i inni rozwiązywacze problemów), gdy mają objaw i próbują wywnioskowaæ prawdopodobieņstwo przyczyn. Istnieje równieŋ inny waŋny styl rozumowania, który nazywa się "wyjaķnianiem". Oto przykģad: Zaģóŋmy, ŋe wiemy, ŋe samochód się nie uruchamia, i wyliczyliķmy wartoķci prawdopodobieņstwa dla ukģadu paliwowego stanowiącego problem (to znaczy nie jest w porządku) i dla silnika rozruchowego stanowiącego problem. Potem okazaģo się, ŋe w rzeczywistoķci silnik rozrusznika w rzeczywistoķci zawiódģ. Biorąc pod uwagę te dodatkowe informacje, chcielibyķmy zmniejszyæ prawdopodobieņstwo wystąpienia problemu z ukģadem paliwowym. Problem z rozrusznikiem silnika "wyjaķnia" fakt, ŋe samochód nie chce się uruchomiæ, więc mamy mniej powodów, aby podejrzewaæ ukģad paliwowy. Fakt, ŋe silnik rozruchowy nie uruchamia się, "wyjaķnia" moŋliwy problem z ukģadem paliwowym. Strategia wyjaķniania jest powszechnie stosowana przez ludzi w medycynie, prawie, nauce i codziennym rozumowaniu. Na przykģad obroņca moŋe przytoczyæ dowody na to, ŋe inna osoba (nie jego klient) zostaģa zidentyfikowana na monitoringu telewizyjnym systemu bankowego , co tģumaczy zaangaŋowanie jego klienta w napad na bank. Zilustrowano efekt wyjaķniania za pomocą faktycznych obliczeņ wnioskowania przeprowadzonych w nieco większej sieci dotyczącej silników

Po zaobserwowaniu, ŋe samochód się nie uruchamia, prawdopodobieņstwo, ŋe problem stanowi rozrusznik silnik, wynosi 0,023 (przy uŋyciu tabel prawdopodobieņstwa warunkowego sieci, których nie pokazano na schemacie), oraz prawdopodobieņstwo, ŋe ukģad paliwowy jest problem jest obliczany na 0,283. Ale po dodatkowym stwierdzeniu awarii silnika rozrusznika prawdopodobieņstwo, ŋe przyczyną problemu jest ukģad paliwowy, spada o ponad poģowę do 0,1. Gdybyķmy chcieli zbudowaæ sieæ bayesowską o silniku samochodowym, który byģby bardziej realistyczny i uŋyteczny, musielibyķmy wspomnieæ o wielu innych komponentach i podsystemach. Taka sieæ moŋe zawieraæ setki węzģów wraz z powiązanymi tabelami prawdopodobieņstwa warunkowego. Mimo ŋe warunkowe niezaleŋnoķci zmniejszyģyby liczbę indywidualnych prawdopodobieņstw, które naleŋy okreķliæ, ich liczba moŋe byæ tak duŋa, ŋe dokģadne wnioskowania probabilistyczne nadal byģyby trudne do obliczenia obliczeniowego - przy zaģoŋeniu, ŋe wartoķci tych prawdopodobieņstw mogģyby zostaæ nawet zebrane.
Po zaobserwowaniu, ŋe samochód się nie uruchamia, prawdopodobieņstwo, ŋe problem stanowi silnik rozrusznika, wynosi 0,023 (przy uŋyciu tabel prawdopodobieņstwa warunkowego sieci, których nie pokazano na schemacie), oraz prawdopodobieņstwo, ŋe ukģad paliwowy jest problem jest obliczany na 0,283. Ale po dodatkowym stwierdzeniu awarii silnika rozrusznika prawdopodobieņstwo, ŋe przyczyną problemu jest ukģad paliwowy, spada o ponad poģowę do 0,1. Gdybyķmy chcieli zbudowaæ sieæ bayesowską o silniku samochodowym, który byģby bardziej realistyczny i uŋyteczny, musielibyķmy wspomnieæ o wielu innych komponentach i podsystemach. Taka sieæ moŋe zawieraæ setki węzģów wraz z powiązanymi tabelami prawdopodobieņstwa warunkowego. Mimo ŋe warunkowe niezaleŋnoķci zmniejszyģyby liczbę indywidualnych prawdopodobieņstw, które naleŋy okreķliæ, ich liczba moŋe byæ tak duŋa, ŋe dokģadne wnioskowania probabilistyczne nadal byģyby trudne do obliczenia obliczeniowego - przy zaģoŋeniu, ŋe wartoķci tych prawdopodobieņstw mogģyby zostaæ nawet zebrane. Na szczęķcie moŋliwe są róŋne uproszczenia, które pozwalają na dalsze zmniejszenie potrzebnej liczby prawdopodobieņstw. Dzięki nim obliczenia przybliŋonego, ale wciąŋ przydatnego wnioskowania w duŋych sieciach stają się wykonalne. Warto wspomnieæ, ŋe niektóre z tych uproszczeņ i przybliŋone metody obliczeniowe wymagają doķæ zģoŋonych narzędzi matematycznych, z których wiele pochodzi z sąsiednich pól, takich jak statystyka i inŋynieria sterowania. Tego rodzaju obliczenia sieci bayesowskiej stanowią kolejny przykģad tego, jak to zrobiæ problemy wczeķniej uwaŋane za nierozwiązywalne obliczeniowo doprowadziģy do postępu technicznego. Na ryc. 28.4 pokazuję przykģad doķæ duŋej sieci bayesowskiej.

Sieæ reprezentuje wiedzę na temat chorób wątroby i dróg ŋóģciowych (wątroby, pęcherzyka ŋóģciowego i pokrewnych narządów) i zostaģa opracowana jako narzędzie do stosowania wķród studentów medycyny. Ta sieæ pochodzi częķciowo z bazy wiedzy INTERNIST-1 (patrz str. 301). Ma 448 węzģów i 908 strzaģ. Gdyby zastosowano peģne tablice prawdopodobieņstwa warunkowego, naleŋaģoby podaæ 133 931,430 prawdopodobieņstw. Programiķci sieci byli w stanie zmniejszyæ tę liczbę do 8 254 wartoķci, korzystając z róŋnych uproszczeņ. Sieci bayesowskie zawierające setki węzģów zostaģy wykorzystane do zastosowaņ w biologii, medycynie, klasyfikacji dokumentów, przetwarzaniu obrazów, prawie, dekodowaniu z korekcją bģędów i wielu innych. Wiele z tych sieci pochodzi automatycznie z duŋych zestawów danych, temat ten omówię w następnej sekcji.
Automatyczna konstrukcja sieci bayesowskich
Jednym z powodów, dla których sieci bayesowskie staģy się tak waŋne, jest to, ŋe moŋna je automatycznie konstruowaæ z duŋych baz danych. Oznacza to, ŋe moŋna się ich "nauczyæ", a wyuczonych wersji moŋna uŋyæ do uzasadnienia danego tematu. Dwoma pionierami w rozwoju tych metod uczenia się byli Greg Cooper i Edward Herskovits. Temat jest nadal aktywnym obszarem badawczym, a kilku innych wniosģo znaczący wkģad. Oto, ogólnie rzecz biorąc, sposób dziaģania tego procesu. Aby nauczyæ się sieci, naleŋy poznaæ jej strukturę, to znaczy rozmieszczenie jej węzģów i ģączy, a takŋe CPT sieci. Najpierw wyjaķnię, w jaki sposób moŋna nauczyæ się CPT dla znanej struktury, a następnie, w jaki sposób moŋna nauczyæ się samej struktury, mimo ŋe te dwa procesy są ze sobą powiązane. Rozwaŋmy jeszcze raz czterowęzģową sieæ bayesowską dla silnika samochodowego. Jak moŋemy nauczyæ się CPT dla węzģa P4 (czyli Car Starts) - tego, którego rodzicami są P2 (czyli Car Cranks) i P3 (czyli ukģad paliwowy OK)? Uŋywając moich skrótów dla tych zdaņ, ŋe CPT skģada się z następujących prawdopodobieņstw warunkowych:
p(P4 | P2; P3);
p(P4 | P2; ¬P3);
p(P4 | ¬P2; P3);
i
p(P4 | ¬P2; ¬P3):
Gdybyķmy mieli duŋy zbiór próbek sytuacji, w których samochód czasami zacina się, a czasem nie, w którym samochód czasami kręci się, a czasem nie, a czasami ukģad paliwowy byģ sprawny, a czasem nie, moglibyķmy uŋyæ ich do podsumowania tak zwanych "przykģadowych statystyk". Na przykģad, moglibyķmy zanotowaæ w tych próbkach liczbę uruchomieņ samochodu, gdy samochód się nie obracaģ, a ukģad paliwowy byģ sprawny, i podzieliæ tę liczbę przez caģkowitą liczbę przypadków, gdy samochód się nie uruchomiģ byģo ok. Frakcję tę moŋna wykorzystaæ jako oszacowanie p (P4 ¬P2; P3). Moŋemy dokonaæ podobnych szacunków dla pozostaģych trzech prawdopodobieņstw i podobne szacunki prawdopodobieņstw w innych CPT w sieci. Przy wystarczająco duŋej kolekcji próbek oszacowania te byģyby doķæ wiarygodne: im większa liczba próbek, tym lepsze oszacowania. Kompilacja przykģadowych statystyk (czasami uzupeģniana przez dodatkowe obliczenia, których nie będę tutaj omawiaæ) zapewnia sposób oszacowania CPT sieci o znanej strukturze. W jaki sposób moglibyķmy poznaæ strukturę nieznanej sieci? Metoda obejmuje następującą sekwencję kroków:
1. Zacznij od podstawowej struktury kandydata, na przykģad takiej, która nie ma poģączenia między węzģami i uŋyj kolekcji danych do oszacowania CPT. (Przypomnijmy, ŋe CPT węzģa bez rodziców jest tylko bezwarunkowym prawdopodobieņstwem dla tego węzģa. Moŋna to oszacowaæ na podstawie uģamka razy, gdy skojarzona z nim propozycja jest prawdziwa w zbiorze danych.)
2. Oblicz "miarę dobroci" dla tej sieci. Jeden z proponowanych ķrodków opiera się na tym, jak dobrze sieæ z jej obliczonymi CPT moŋe byæ wykorzystana do przesģania (tj. odtworzenia) pierwotnego zbioru danych.
3. Rozpocznij proces wyszukiwania "wspinanie się na wzgórze", oceniając "pobliskie" sieci, które róŋnią się od poprzedniej drobnymi zmianami (które mogą obejmowaæ dodanie ģuku, usunięcie juŋ istniejącej i zamianę węzģów). Aby oceniæ zmienione sieci, oblicza się ich CPT i zalety. Postaw na zmienioną sieæ z najlepszą poprawą dobroci.
4. Kontynuuj proces wspinania się na wzgórze, dopóki nie będzie moŋna wprowadziæ ŋadnych ulepszeņ (lub dopóki nie zostanie speģnione okreķlone wczeķniej kryterium zatrzymania). Chociaŋ proces ten wydaje się byæ doķæ ŋmudny (i tak jest), komputery mogą wykonywaæ ten proces wspinania się w miarę rozsądnie i wyuczono niektóre doķæ zģoŋone sieci.
Jako przykģad rozwaŋmy sieci na ryc. 28.5.

Pokazane są trzy sieci. Pierwszą jest sieæ kodująca relacje między 37 zmiennymi dla problemu związanego z systemem alarmowym stosowanym w zarządzaniu respiratorem na oddziale intensywnej opieki szpitalnej. Tę znaną sieæ wykorzystano do wygenerowania zestawu treningowego wielkoķci 10.000 losowych wartoķci dla 37 węzģów. Korzystając z tej losowej próbki i rozpoczynając od drugiej sieci (tej bez ŋadnych zaleŋnoķci, a więc bez powiązaņ między węzģami), uczono się trzeciej sieci (za okoģo pięæ godzin na SUN SPARCstation 20) przy uŋyciu metod podobnych do tych wģaķnie opisanych. Zwróæ uwagę na bardzo bliskie podobieņstwo w strukturze {brakuje tylko jednego ģuku. Czasami strukturę sieci moŋna znacznie uproķciæ, dodając do sieci węzģy, które reprezentują atrybuty, które nie występują w zbiorze danych. Metody uczenia się w sieci zostaģy rozszerzone, aby móc nauczyæ się instalowaæ "ukryte węzģy", które reprezentują te wymyķlone atrybuty. Atrybuty wymyķlone na podstawie danych są często przydatne do pogģębienia naszego zrozumienia zjawisk, które doprowadziģy do powstania danych.
Probabilistyczne modele relacyjne
Waŋne opracowanie sieci bayesowskich o nazwie "Probabilistic Modele Relation "(PRM), opracowaģ profesor Stanford , Daphne Koller wraz ze swoimi studentami Avi Pfefferem i Lise Getoor oraz wspóģpracownikiem, Nirem Friedmanem (byģy student Stanforda, a obecnie profesor na Uniwersytecie Hebrajskim). Osoby o ograniczonej sprawnoķci ruchowej integrują prawdopodobieņstwo z rachunkiem predykatu. [Kilka wczeķniejszych prac nad poģączeniem tych dwóch form reprezentacyjnych wykonaģo kilku badaczy, w szczególnoķci David Poole (z University of British Columbia.] PRM wykorzystuje fakt, ŋe niektóre węzģy w sieci moŋe dzieliæ te same atrybuty, z wyjątkiem wartoķci zmiennych wewnętrznych dla tych atrybutów (podobnie jak fakt, ŋe w rachunku predykatów ten sam predykat moŋe byæ zapisany z róŋnymi wartoķciami dla swoich zmiennych wewnętrznych). Na przykģad sieæ pokazująca, ŋe grupa krwi i informacje o chromosomie zaleŋą od chromosomów odziedziczonych po rodzicach, powtarzaģaby podsieci. Przykģad pokazuję na ryc. 28.7.
W jego przypadku pojedynczy "szablon" sģuŋy do tworzenia róŋnych podsieci, których zmienne atrybutów są tworzone instancji dla róŋnych osób. Korzystanie z PRM sprawia, ŋe projektowanie sieci bayesowskich jest znacznie bardziej wydajne niŋ proces projektowania kaŋdej z nich (tylko nieznacznie róŋni się ) oddzielnie. Koller twierdzi, ŋe byģa zmotywowana do myķlenia o PRM w rozmowie ze studentem, który musiaģ przeksztaģciæ sieæ bayesowską modelującą trzypasmową autostradę w jedną modelującą czteropasmową autostradę. Przypomina, mówiąc "…ale to tylko dodanie jeszcze jednego pasa, z pewnoķcią moŋesz ponownie wykorzystaæ częķæ struktury" .Struktura i CPT PRM mogą byæ okreķlone przez projektanta lub wyuczone z danych. Dodatkową zaletą PRM jest to, ŋe obiekty powstaģe w wyniku tworzenia instancji zmienne szablonów moŋna ģączyæ w wynikową sieæ bayesowską (niektóre są na schemacie); relacje między tymi obiektami moŋna okreķlaæ ręcznie lub uczyæ się. Podobnie jak w przypadku kaŋdej sieci bayesowskiej moŋna zastosowaæ procedury wnioskowania probabilistycznego w celu odpowiedzi na pytania dotyczące prawdopodobieņstw niektórych węzģów ze względu na te z innych. PRM i powiązane struktury byģy wykorzystywane w róŋnych aplikacjach, w tym do odzyskiwania sieci regulacyjnych z danych dotyczących ekspresji genów. Jeķli chodzi o sieci bayesowskie ogólnie, jest ich teraz wiele, wiele aplikacji {zbyt wiele aby wymieniæ tutaj. Aby nadaæ posmak ich róŋnorodnoķci, wspomnę o ich zastosowaniu w badaniach genomowych, w prognozowaniu i kierowaniu ruchem samochodowym, w modelowaniu wybuchów chorób i zgadywaniu w ac Kolejne dziaģania uŋytkownika komputera, aby umoŋliwiæ systemowi operacyjnemu Windows "wstępne pobranie" danych aplikacji do pamięci, zanim będzie ona wymagana. Są teŋ firmy, które sprzedają systemy oparte na wiedzy i wnioskach sieci bayesowskich. Jedną z rzeczy, których nauczyģy nas wszystkie te aplikacje, jest znaczenie ogromnych iloķci danych, które wedģug Petera Norviga, wspóģautora wiodącego podręcznika AI i dyrektora badaņ w Google, okazaģy się gģównym tematem nowoczesnej AI. W rzeczywistoķci Peter powiedziaģ ,ŋe Google jest największym na ķwiecie systemem sztucznej inteligencji. Zapytano go, dlaczego, a on po prostu odpowiedziaģ "dane, dane, dane", a Google ma ich więcej niŋ ktokolwiek ".
Tymczasowe sieci bayesowskie
Przykģady sieci bayesowskich zilustrowane w ostatnich sekcjach, wraz z większymi zastosowanymi w wielu aplikacjach, moŋna nazwaæ "statycznymi". Oznacza to, ŋe zdania i wielkoķci reprezentowane przez węzģy i CPT są ponadczasowe w tym sensie, ŋe dotyczą one tego samego momentu w czasie (lub wszystkich momentów w czasie). Jednak opisaģem juŋ sieæ probabilistyczną, która w róŋnym czasie obejmuje wielkoķci, a mianowicie ukryte modele Markowa. W sekcji 17.3.2 wyjaķniģem, w jaki sposób HMM zostaģy uŋyte w rozpoznawaniu mowy. Jedną z powszechnych postaci HMM pokazano na rysunku
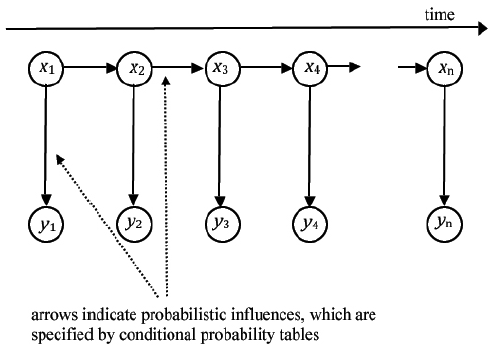
Ten schemat ma na celu pokazanie, jak sekwencja czasowa bytów, x1; x1; …x1, powoduje sekwencję czasową innych bytów, y1; y2;… yn. Wpģyw kaŋdego xi na kolejne x i y jest regulowany przez prawdopodobieņstwa. Ģatwo zauwaŋyæ, ŋe ta sieæ jest siecią bayesowską, mimo ŋe zaangaŋowane iloķci występują w sekwencji czasowej. Ten konkretny HMM jest nazywany procesem Markowa pierwszego rzędu, poniewaŋ kaŋdy stan zaleŋy tylko od stanu bezpoķrednio poprzedzającego. W procesach wyŋszego rzędu na kaŋdy stan wpģywa więcej niŋ jeden stan poprzedni. W sieci HMM kaŋda xi jest "zmienną stanu", a yi są "zmiennymi obserwowalnymi". Zakģada się, ŋe wartoķci stanów są nieznane (to znaczy "ukryte"), ale obserwowalne wartoķci moŋna zmierzyæ i tym samym poznaæ. Kaŋdy stan powoduje związany z nim obserwowalny i następny stan. Zakģadamy, ŋe znamy tablice prawdopodobieņstwa warunkowego sieci, to znaczy prawdopodobieņstwa obserwowalnoķci i następnego stanu, biorąc pod uwagę wartoķæ stanu. Biorąc pod uwagę wartoķæ jednego lub większej liczby obserwowalnych, moŋemy obliczyæ zaktualizowane prawdopodobieņstwa stanów za pomocą dowolnej metody obliczeniowej prawdopodobieņstwa w sieci bayesowskiej. Oto przykģad. Zaģóŋmy, ŋe warunki pogodowe samolotu na odlegģym lotnisku są albo mgliste, albo nie. Czujnik na lotnisku rejestruje pogodę, a nadajnik emituje sygnaģ co pięæ minut. Sygnaģ ten, odbierany przez samolot próbujący wylądowaæ na lotnisku, moŋe czasami byæ w bģędzie. Zatem stany, czyli x w HMM modelujące ten proces, moŋe mieæ wartoķci 1 lub 0, a wartoķæ 1 oznacza mgģę. Sygnaģy odbierane przez samolot, y w HMM, równieŋ mają wartoķci 1 lub 0, przy czym wartoķæ 1 wskazuje, ŋe zaobserwowano mgģę. Ale obserwacje mogą byæ bģędne. Mówiąc konkretnie, zaģóŋmy, ŋe prawdopodobieņstwo, ŋe następny stan ma taką samą wartoķæ jak w obecnym stanie, wynosi 75% (mgģa ma tendencję do utrzymywania się), a prawdopodobieņstwo bģędu jest moŋliwe do zaobserwowania na poziomie 5%. Prawdopodobieņstwa te pozwalają na zbudowanie tabel prawdopodobieņstwa warunkowego sieci bayesowskiej. (Przykģad moŋna uczyniæ bardziej realistycznym, pozwalając kaŋdemu stanowi odzwierciedliæ stopieņ zamglenia i zaleŋą od stanów oprócz pojedynczego stanu poprzedzającego.) Pilot statku powietrznego musi podjąæ decyzję o próbie wylądowania lub nie w oparciu o kolejnoķæ otrzymanych y. Na przykģad, on lub ona moŋe chcieæ poznaæ prawdopodobieņstwo, ŋe lądowisko jest teraz mgliste na podstawie sekwencji wczeķniejszych obserwacji, aŋ do obecnej. W języku HMM operacja obliczająca to prawdopodobieņstwo nazywa się "filtrowaniem". Alternatywnie, pilot moŋe chcieæ obliczyæ prawdopodobieņstwo, ŋe lądowanie będzie mgliste za 10 minut na podstawie tych obserwacji. Ta operacja nazywa się "prognozowaniem". Chociaŋ pilot nie przydaģby się wiele, moŋe byæ ciekawy prawdopodobieņstwa, ŋe 10 minut temu pas lądowania byģ zamglony na podstawie sekwencji obserwacji do chwili obecnej. Ta operacja nazywa się "wygģadzaniem". W mojej dyskusji na temat rozpoznawania mowy w rozdziale 17.3.2 wspomniaģem, ŋe stany HMM odpowiadają pojedynczym sģowom, a obserwacje odpowiadają segmentom ksztaģtu fali. W tej aplikacji chcemy obliczyæ najbardziej prawdopodobną sekwencję sģów, biorąc pod uwagę wszystkie obserwacje przebiegów do chwili obecnej. Wszystkie te obliczenia - filtrowanie, przewidywanie, wygģadzanie i najbardziej prawdopodobna sekwencja stanów - mogą byæ wykonywane przy uŋyciu procedur wnioskowania sieci bayesowskich . Istnieje kilka wyspecjalizowanych wersji, z których niektóre pochodzą z terenów spoza AI. Zaleŋą one od aplikacji i danych sieci. Spoķród nich mogę wspomnieæ (ale nie będę próbowaģ tutaj wyjaķniaæ) algorytm przewijania do przodu, algorytm Viterbiego i filtrowanie Kalmana. Odwaŋny matematycznie czytelnik moŋe znaležæ jasne wyjaķnienia w doskonaģym podręczniku Russella i Norviga. Fakt, ŋe peģne wyjaķnienia wiąŋą się z doķæ zģoŋoną matematyką, ponownie ķwiadczy o wielkim wzroķcie technicznej gģębi sztucznej inteligencji, który rozpocząģ się w latach 80. HMM, w tym mój mglisty / nie-zamglony przykģad, mają tylko jedną zmienną stanu w kaŋdej chwili. Moŋliwe jest budowanie sieci, w których za kaŋdym razem jest więcej zmiennych stanu {z których wszystkie wpģywają na siebie nawzajem, obserwacje i kolejne zmienne stanu. Są one zwykle nazywane "dynamicznymi sieciami bayesowskimi" (DBN) i zostaģy po raz pierwszy zbadane w AI przez Thomasa Deana i Keiji Kanazawa. Dodatkowe zmienne stanu i obserwacji sprawiają, ŋe dokģadne obliczenia są trudne, ale opracowano kilka praktycznych przybliŋonych metod, takich jak "filtrowanie cząstek" (które opiszę bardziej szczegóģowo póžniej). Podobnie jak w przypadku zwykģych sieci bayesowskich, DBN moŋna nauczyæ się z baz danych zawierających informacje o procesach czasowych. Wykorzystano je przede wszystkim w kilku aplikacjach te wymagające percepcji. Jednym z nich jest przetwarzanie filmów, w których moŋna wykorzystywaæ probabilistyczne zaleŋnoķci między klatkami do rozpoznawania i ķledzenia poruszających się obiektów. Innym jest certyfikacja systemów unikania kolizji dla zaģogowych i bezzaģogowych statków powietrznych. Chociaŋ ten rozdziaģ dotyczy sieci bayesowskich, są one tylko jednym rodzajem waŋnej ogólnej klasy zwanej "probabilistycznymi modelami graficznymi. "Losowe pola Markowa, często nazywane sieciami Markowa, są kolejnym czģonkiem tej klasy, w której poģączenia między węzģami są niekierunkowe. Zostaģy one pierwotnie opracowane w celu rozwiązywania problemów w fizyce statystycznej, a teraz znajdują zastosowanie w wielu obszarach, w tym w przetwarzaniu obrazu, percepcji sensorycznej i modelowaniu mózgu. Istnieją równieŋ sposoby interpretacji innych sieci neuronowych jako przykģadów probabilistycznych modeli graficznych.