Inteligentne architektury systemu
Informatycy opracowali róŋne sposoby ģączenia duŋych programów skģadających się z wielu specjalistycznych podprogramów. Tradycyjna struktura kontrolująca dziaģanie większoķci programów polega na tym, ŋe gģówny program wykonuje instrukcje krok po kroku, pobierając i przechowując dane w pamięci, wykonując róŋne operacje na takich danych oraz podejmując inne dozwolone dziaģania. Niektóre instrukcje w programie gģównym mogą polegaæ na "wywoģaniu" podprogramu i przekazaniu mu kontroli. Podprogramy z kolei mogą wywoģywaæ inne podprogramy i tak dalej. Po tym, jak podprogram nie wykona tego, do czego zostaģ powoģany, ogólna kontrola powraca do programu, który go wywoģaģ, który moŋe następnie wywoģaæ inny podprogram i tak dalej, aŋ do kontroli koņcowej wraca do programu gģównego. Ostatecznie program gģówny moŋe ostatecznie zakoņczyæ dziaģanie, po wykonaniu wszystkich swoich dziaģaņ lub moŋe kontynuowaæ dziaģanie (w zasadzie na zawsze), poniewaŋ podobnie jak program, który rezerwuje linie lotnicze na ŋądanie dla wszystkich korzystających z niego, jego praca nigdy się nie koņczy. Ten schemat to tak zwana architektura von Neumanna. Istnieje wiele opracowaņ na temat tego ogólnego pomysģu. "Przerwania" mogą byæ zawarte w programach i podprogramach. Są one zawsze czujne na specjalne warunki w samym systemie komputerowym lub w ķrodowisku - warunki, które, jeķli zostaną speģnione, wymagają natychmiastowego przekazania kontroli programom, które są w stanie poradziæ sobie z takimi warunkami. Na przykģad komputerowe systemy operacyjne zaleŋą od przerwaņ, aby reagowaæ na dane wejķciowe uŋytkownika i inne rzeczy związane ze sprzętem komputerowym. Najwczeķniejsze programy AI dziaģaģy na komputerach, które korzystaģy z architektury von Neumanna, dlatego naturalne byģo, ŋe architektura programów (czyli sposób, w jaki one byģy zorganizowane) byģa zgodna ze stylem dziaģania komputera von Neumanna. Zrobili to, mimo ŋe z czasem programy niŋszego poziomu, które faktycznie kontrolowaģy komputer, stopniowo stawaģy się bardziej zģoŋone w sposób, którego programiķci nie musieli zauwaŋaæ. Na przykģad jedna innowacja waŋna dla uruchamiania programów napisanych w LISP polegaģa na bardziej efektywnym wykorzystaniu cennych zasobów pamięci komputerowej. Tak zwane procedury czyszczenia pamięci od czasu do czasu skanowaģy pamięæ komputera w celu znalezienia struktur, które nigdy więcej nie będą uŋywane. Pamięæ uŋywana do przechowywania tych struktur moŋe byæ następnie odzyskana w celu wykorzystania do przechowywania nowych struktur list. Twórcy programów mogą zignorowaæ ten aspekt architektury oprogramowania komputerowego niŋszego poziomu i mogą pisaæ swoje styl von Neumann, kolejno uruchamiając programy, jakby mieli duŋo dostępnej pamięci.W przeciwieņstwie do koncepcji von Neumanna polegającej na wykonywaniu instrukcji jedna po drugiej, moŋna wyobraziæ sobie architekturę, w której wiele instrukcji jest wykonywanych jednoczeķnie. Taki "paralelizm" moŋna osiągnąæ albo przez faktyczne posiadanie kilku procesorów sprzętowych, na których programy są hodowane do wykonania, albo przez symulację równolegģej pracy na prostszej architekturze von Neumanna, w której programy są tak naprawdę wykonywane sekwencyjnie, ale programiķci, z tego, co wiedzą, pomyķl o nich jako o jednoczesnym dziaģaniu. Na przykģad w niesymbolicznym ķwiecie sieci neuronowych moŋna sobie wyobraziæ grupy elementów neuronowych dziaģających jednoczeķnie, mimo ŋe symulacje tych sieci muszą kolejno rozpatrywaæ kaŋdy element neuronowy. W Pandemonium demony (byæ moŋe niektóre zaimplementowane przez elementy neuronalne, a niektóre zaimplementowane przez programy) mogģy dziaģaæ równolegle, ale programy Selfridge musiaģy symulowaæ taką równolegģoķæ. Symulację równolegģoķci moŋna równieŋ osiągnąæ dzięki systemowi "dzielenia czasu", w którym uŋytkownik (lub kilku róŋnych uŋytkowników) moŋe sobie wyobraziæ, ŋe wszystkie ich programy dziaģają jednoczeķnie. Nowoczesny komputer ,system operacyjny, taki jak UNIX, Windows lub Mac OS, to bardzo zģoŋona agregacja programów, których organizacja (to znaczy rchitektura) musi byæ bardzo starannie zaprojektowana. Wykorzystują zarówno rzeczywisty sprzęt równolegģy (jak w tak zwanych systemach wielordzeniowych), jak i wspóģuŋytkowanie czasu, dzięki czemu uŋytkownicy mogą na przykģad uruchamiaæ programy poczty e-mail jednoczeķnie (o ile wiedzą) z programami arkuszy kalkulacyjnych.
Architektury obliczeniowe
Architektury trójwarstwowe
Opisano juŋ, w jaki sposób elementy jednego systemu AI, Shakey, zostaģy zorganizowane w grupy wysokiego, ķredniego i niskiego poziomu - architektura "trójwarstwowa". Na rysunku poniŋej pokazano jak programy i dane Shakeya moŋna pogrupowaæ w poziomy.
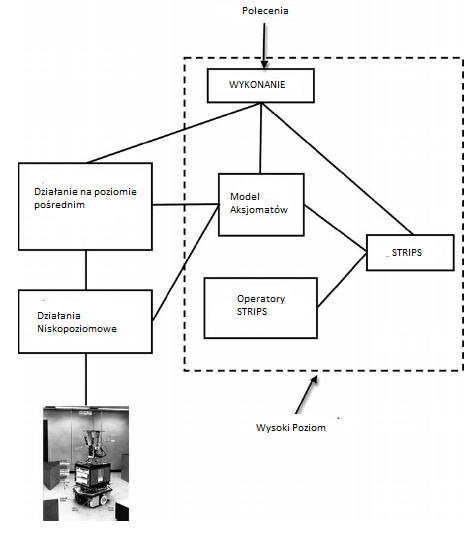
Interakcje między programami na tych poziomach ilustrują linie ģączące. Wszystkie percepcyjne i podstawowe programy ruchowe Shakeya zostaģy osadzone w dziaģaniach na niskim poziomie, podczas gdy dziaģania na poziomie poķrednim ģączyģy dziaģania na niskim poziomie na róŋne sposoby, aby wykonywaæ niektóre typowe zadania. Wysoki poziom odpowiadaģ za planowanie i ogólną realizację planów. Trójwarstwowe architektury, takie jak ta stosowana przez Shakey, byģy (i nadal są) stosowane w kilku innych systemach robotów. Jako Erann Gat, badacz, który wykorzystaģ te architektury w Jet Propulsion Laboratory, podkreķla w swojej pracy badawczej, Trójwarstwowa architektura wynika z obserwacji empirycznej, ŋe skuteczne algorytmy sterowania robotami mobilnymi dzielą się na trzy odrębne kategorie: 1) algorytmy sterowania reaktywnego, które mapują czujniki bezpoķrednio na siģownikach z niewielkim stanem wewnętrznym lub bez niego, 2) algorytmy rządzące rutynowymi sekwencjami czynnoķci, które w duŋej mierze opierają się na stanie wewnętrznym, ale nie przeprowadzają wyszukiwania, oraz 3) czasochģonne (w stosunku do tempa zmiany ķrodowiska) oparte na wyszukiwaniu algorytmy, takie jak planiķci. Kilka trójwarstwowych architektur opisanych przez Gat opiera się na trójwarstwowym schemacie R. Jamesa Firby'ego przy uŋyciu " Reactive Action Packages "(RAP). Raporty RAP są doķæ podobne do programów telereaktywnych, poniewaŋ grupują razem i opisują wszystkie znane sposoby wykonania zadania w róŋnych sytuacjach. Wspóģczesnym przykģadem trójwarstwowej architektury jest ta uŋywana przez niemiecki "widzący samochód osobowy", VaMoRs-P, opisany przez Ernsta D. Dickmannsa i wspóģpracowników.
Architektury wielowarstwowe
Jako alternatywa dla trójwarstwowych systemów, z których wszystkie obejmowaģy: poziom planowania, Rodney Brooks i inni zaproponowali takie architektury które kontrolowaģy dziaģania robota w sposób, który reagowaģ bezpoķrednio na zmiany w otoczeniu (zgodnie z wyczuciem) bez potrzeby planowania. Pierwotnie zwane "architekturami subsumpcji", póžniej nazwano je "opartymi na zachowaniu", poniewaŋ skģadaģy się one ze specjalnie zaprogramowanych zachowaņ robotów. Róŋne zachowania, na przykģad "wędrówka", "unikanie przeszkód" i "eksploruj" są uģoŋone w poziomach, z których kaŋdy reaguje na wģasny zestaw bodžce ķrodowiskowe i kaŋdy w stanie kontrolowaæ robota w zaleŋnoķci od wykrytej sytuacji. To ķcisģe powiązanie i interakcja z tym, co dzieje się w ķrodowisku, powoduje to, co niektórzy nazywają "zachowaniem wschodzącym". Jak ujęli to Maja Matariffic i Francois Michaud, na przykģad robot, który zadokuje się innymi robotami, moŋe nie mieæ okreķlonego zachowania flokującego; zamiast tego jego interakcja ze ķrodowiskiem i innymi robotami moŋe powodowaæ flokowanie, chociaŋ jego jedynymi zachowaniami mogą byæ unikanie kolizji, pozostawanie blisko grupy i kontynuowanie pracy James Albus, w National Institute of Standards i Technologia (wczeķniej National Bureau of Standards) opracowaģy coķ, co nazwaģ "architekturą modelu referencyjnego". Architektura skģada się z wielu warstw "systemów sterowania w czasie rzeczywistym" (RCS) opracowanych wczeķniej w NIST jako elementów "teorii inteligencji". (Albus twierdzi, ŋe jego model RCS zostaģ pierwotnie zainspirowany modelem móŋdŋku, który wymyķliģ on i David Marr.) Kaŋdy RCS "dzieli problem sterowania na cztery podstawowe elementy: generowanie zachowaņ (lub rozkģad zadaņ), modelowanie ķwiata, przetwarzanie sensoryczne, oraz (w nowszych wersjach) ocenianie wartoķci. Grupuje te elementy w węzģy obliczeniowe, które są odpowiedzialne za okreķlone podsystemy, i rozmieszcza te węzģy w hierarchicznych warstwach, tak aby kaŋda warstwa miaģa charakterystyczną funkcjonalnoķæ i czas. " Warstwowa struktura RCS, zwana NASREM (dla NASA / NBS Standard . Model referencyjny), zostaģ zaproponowany jako architektura dla latającego tele-robota servicera na stacji kosmicznej. W kaŋdej warstwie jednostki RCS mają komponenty przetwarzania sensorycznego (SP), komponenty modelowania ķwiata (WM) i komponenty rozkģadu zadaņ (TD). Najniŋsza warstwa RCS jest zasadniczo serwosterownikiem; w miarę przesuwania się w górę hierarchii, RCS wykonują coraz bardziej strategiczne zadania. Albus i jego zespóģ z NIST opracowali róŋnorodne architektury przy uŋyciu warstw. Zainspirowany architekturą Albusa opracowano taką, którą nazwano "architekturą potrójnej wieŋy" . Najniŋszy poziom centralnej wieŋy modelowej odbiera dane wejķciowe przez czujniki bezpoķrednio z otoczenia i przechowuje je jako prymitywne predykaty percepcyjne. Programy (reprezentowane jako reguģy) w Wieŋy Percepcji reprezentują te prymitywne predykaty jako bardziej abstrakcyjne {dodając je do Wieŋy Modelowej. Ten proces tworzenia coraz wyŋszych abstrakcji przebiega stopniowo aby udoskonaliæ Wieŋe Percepcji i Modele. W wieŋy akcji procedury dziaģania na najniŋszym poziomie są prostymi refleksami, wywoģywanymi przez predykaty w wieŋy modelu odpowiadające pierwotnym predykatom. Bardziej zģoŋone dziaģania są wywoģywane przez bardziej abstrakcyjne predykaty odpowiednie dla tych dziaģaņ. Akcje wysokiego poziomu wywoģują inne akcje, aŋ proces osiągnie prymitywne akcje, które faktycznie wpģywają na ķrodowisko. Dziaģania w wieŋy akcji miaģy byæ programowane przy uŋyciu mojego tele-reaktywnego języka. Postrzegane efekty tych dziaģaņ z kolei zmieniają wartoķci predykatów w Wieŋy Modelowej, wywoģując byæ moŋe róŋne dziaģania. Aby wiernie modelowaæ trwające zmiany ķrodowiskowe, jako częķæ wieŋy modelowej doģączono system utrzymania prawdy (TMS). TMS w sposób ciągģy usuwa predykaty i wartoķci z Wieŋy Modelowej, których nie moŋna juŋ uzyskaæ (na podstawie reguģ percepcyjnych) z obecnych wówczas skģadników Wieŋy Modelowej. Jedyną implementacją tej architektury, którą znam, byģo sterowanie symulowanym robotem ukģadającym klocki. Opisaģem juŋ architekturę tablicy, opracowaną na Carnegie Mellon University dla jej systemu rozumienia mowy HEARSAY-II (patrz str. 279). Zostaģ równieŋ wykorzystany w systemie HASP / SIAP do nadzoru oceanów (patrz str. 321). Jak wczeķniej zacytowaģem Russella i Norviga, systemy \ Blackboard są podstawą nowoczesnej architektury interfejsu uŋytkownika. "Są one równieŋ wykorzystywane w kilku aplikacjach komputerowych, w tym na przykģad w automatycznym systemie adnotacji genomu do przewidywania lokalizacji genów i struktur. Powiedziaģem wczeķniej, ŋe tablica jest warstwową strukturą pamięci, w której programy o nazwie \ žródģa wiedzy mogą odczytywaæ dane i zapisuj dane w róŋnych warstwach. Zazwyczaj KS moŋe wyszukaæ, a następnie odczytaæ niektóre dane z jednej lub więcej warstw, wykonaæ niektóre obliczenia przy uŋyciu tych danych, a następnie zapisaæ wyniki tych obliczeņ w jednej lub więcej warstwach. Administrator decyduje, które KS, które widzą dane, na których mogą dziaģaæ, powinny byæ aktywne. W niektórych aplikacjach jednoczeķnie moŋe byæ aktywnych kilka KS. Wynikiem tego wszystkiego jest bardzo dynamiczny proces, w którym dane na tablicy stale się rozwijają, ostatecznie wytwarzając poŋądane informacje, takie jak przewidywanie lokalizacji genu, rozpoznawanie zdania lub interpretacja sygnaģów sonaru oceanicznego. Poniewaŋ informacje na jednej warstwie tablicy mogą powodowaæ, za poķrednictwem KS, pojawienie się innych informacji na dowolnym innym poziomie, architektura tablicy tablic zapowiadaģa propagację prawdopodobieņstwa w górę iw dóģ w modelach korowych.
Architektura BDI
Michael Georgeff i inni zaproponowali agenta
architektury oparte na filozoficznych koncepcjach przekonaņ, pragnieņ i intencji. Są to tak zwane architektury BDI. Przekonania agenta reprezentują jego wiedzę na temat jego ķrodowiska (w tym siebie i innych agentów), zwykle wyraŋoną w jakimķ logicznym języku, takim jak rachunek predykatów pierwszego rzędu. (Sģowo "przekonanie" jest uŋywane zamiast "wiedzy", poniewaŋ przekonania agenta mogą ulec zmianie i mogą nie modelowaæ dokģadnie jego otoczenia.) Pragnienia agenta reprezentują cele agenta - sytuacje, które chce osiągnąæ. Intencje agenta reprezentują pragnienia, które agent faktycznie postanowiģ osiągnąæ. Oznacza to, ŋe zacząģ realizowaæ plan ich osiągnięcia. Na przykģad architektury BDI, w odróŋnieniu od opartych na zachowaniu, reaktywnych, wyražnie reprezentują przekonania, pragnienia i intencje jako rzeczywiste struktury danych. Mówiąc tak ogólnie, niektóre schematy architektoniczne, o których juŋ wspomniaģem, moŋna uznaæ za architektury BDI. Shakey, na przykģad, miaģ przekonania (swój model ķwiata), w kaŋdej chwili otrzymywaģ pragnienie (swój cel), a jego system wykonawczy czasami byģ w trakcie realizacji planu (swojej intencji), aby osiągnąæ ten cel. Georgeff i wspóģpracownicy zaproponowali jednak specjalną wersję architektury BDI, którą nazwali Systemowym Rozumowaniem Proceduralnym (PRS). Oto, w skrócie, jak dziaģa ta architektura.
• Baza danych skģada się z aktualnych przekonaņ agenta na temat jego ķrodowiska (w tym samego siebie) i obszaru tematycznego. Niektóre przekonania są początkowo instalowane przez projektanta, a niektóre uzyskuje agent poprzez aparat percepcyjny i mechanizmy wnioskowania. W PRS przekonania są reprezentowane przez wyraŋenia w rachunku predykatów pierwszego rzędu.
• Cele (pragnienia agenta) są warunkami do osiągnięcia i mogą odnosiæ się zarówno do ķwiata zewnętrznego, jak i do wewnętrznych stanów agenta.
• Biblioteka planów KA zawiera tak zwane "obszary wiedzy" (KA). Kaŋda KA jest okreķloną procedurą okreķlającą plan wykonania zadania, takiego jak podniesienie obiektu. KA skģada się z ciaģa, które opisuje etapy procedury i warunek wywoģania , który okreķla, w jakich sytuacjach KA moŋe byæ uŋyteczny stosowany. Jednostki "prymitywne" nie mają ciaģ, ale odnoszą się bezpoķrednio do dziaģaņ wykonalnych przez system. Są teŋ takie KA wybierane spoķród wielu odpowiednich KA, modyfikowane i manipulowane intencjami oraz obliczające iloķæ argumentów, które naleŋy poķwięciæ na problem, biorąc pod uwagę ograniczenia w czasie rzeczywistym.
• Struktura intencji zawiera zadania, które system wybraģ do wykonania. Zamiar wyraŋa się jako gģówny KA wraz ze wszystkimi jednostki podrzędne KA, które są uŋywane do wykonania gģównej KA.
• Tģumacz uruchamia system. Utrzymuje pozostaģe komponenty systemu i wybiera zamiar ze struktury intencji (KA) do wykonania. Jedną z cech PRS jest to, ŋe wykonanie KA moŋe zostaæ przerwane przez pewne postrzegane sytuacje (takie jak sytuacje awaryjne), co da jej zdolnoķæ do szybkiego reagowania na nieprzewidziane zmiany w otoczeniu.
Byģo kilka zastosowaņ architektury w stylu PRS, w tym radzenie sobie z wadliwym dziaģaniem promu kosmicznego i sterowanie autonomicznym robotem. Oprócz konkretnych pomysģów architektonicznych, które wģaķnie opisaģem, pojawiģo się wiele innych ogólnych sugestii dotyczących organizacji inteligentnych systemów, z których niektóre zaowocowaģy uruchomieniem programów (lub przynajmniej języków programowania, w których moŋna pisaæ uruchomione programy). Pojawiģo się kilka propozycji systemów zdolnych do tak zwanego "rozumowania na poziomie meta", czyli rozumowania na temat sposobu rozumowania. Spoķród nich wymienię Briana Smitha i System 3-LISP i system FOL Richarda Weyhraucha, które byģy w stanie "zastanowiæ się" nad wģasnymi procesami. Systemy wnioskowania na poziomie meta zaproponowali równieŋ Pat Hayes, Michael Genesereth, Stuart Russell i Eric Wefald Waŋne rozwaŋania na temat problemu na poziomie meta przy podejmowaniu decyzji o tym, jak najlepiej rozwiązaæ problem na poziomie podstawowym, obejmują szacunki oczekiwanych kosztów i zalety róŋnych metod rozwiązania. Eric Horvitz jako pionier zastosowaģ "teorię decyzji do kontrolowania rozwiązywania trudnych problemów, biorąc pod uwagę ograniczenia i niepewnoķæ w zasobach wnioskowania". Od tego czasu stosowanie metod probabilistycznych i teorii decyzji w rozumowaniu na poziomie meta staģo się waŋną częķcią sztucznej inteligencji Badania. Czasopismo "Sztuczna inteligencja" poķwięciģo temu zagadnieniu specjalną kwestię w 2001 r. Pomysģy Marvina Minsky′ego na temat "spoģeczeņstwa umysģu" równieŋ sugerują potencjalne projekty inteligentnych systemów, mimo ŋe nie byģy one wystarczająco szczegóģowe do natychmiastowego wdroŋenia. Takie "spoģeczeņstwo" skģadaģoby się z duŋej liczby prostych "agentów", z których ŋaden nie byģby wystarczająco potęŋny ani kompletny, aby sam byģ bytem inteligentnym, ale "umysģ" prawdopodobnie wyģoniģby się z ich wspólnych zachowaņ i interakcji. W podobnym tonie William Kornfeld i Carl Hewitt zasugerowali, ŋe inteligentny system powinien byæ zorganizowany w sposób podobny do "spoģecznoķci naukowej", wykorzystującej indywidualne i równolegģe badania, publikację i krytykę
Architektury dla grup agentów
Naleŋy się spodziewaæ, ŋe inteligentni agenci będą istnieæ w ķrodowiskach zawierających inne inteligentne czynniki, zarówno ludzi, jak i maszyny. Wielu z tych agentów będzie wspóģpracowaæ lub konkurowaæ w wykonywaniu swoich zadaņ. Waŋnymi tematami sztucznej inteligencji staģy się strategie komunikacji między agentami i architektury wieloagentowe. Zwróciģem juŋ uwagę na interakcje między systemami AI a ludžmi. Te interakcje wykorzystują ograniczone wersje języka naturalnego lub innego rodzaju urządzenia interfejsu uŋytkownika. Rzeczywiķcie ķwiat jest peģen komputerów komunikujących się z innymi komputerami za poķrednictwem sieci przy uŋyciu specjalnie zaprojektowanych protokoģów. Chciaģbym tutaj porozmawiaæ o tym, w jaki sposób wykorzystywane są metody sztucznej inteligencji, aby umoŋliwiæ bardziej elastyczną i efektywną komunikację między agentami sztucznej inteligencji, niŋ byģoby to moŋliwe przy komunikacji staģej i protokoģach organizacyjnych. Agenci AI powinni móc planowaæ komunikację z innymi agentami wraz z planowaniem innych dziaģaņ. Ponadto muszą byæ w stanie interpretowaæ komunikację innych agentów wraz z tģumaczeniem innych danych percepcyjnych. Aby to zrobiæ, muszą wziąæ pod uwagę oczekiwane dziaģania, wiedzę i cele innych agentów. Niektóre z wczesnych prac nad tak zwanymi "systemami wieloagentowymi" (wczeķniej "rozproszona AI") wykonaģ Victor Lesser z University of Massachusetts i Lee Erman z Carnegie Mellon University. Zaadaptowali pomysģy architektury tablicy do HEARSAY-II, aby opracowaæ system, który nazwali DISTRIBUTED HEARSAY-II. Byģo to poģączenie kilku rozproszonych tablic, z których kaŋda ma wģasne KS, komunikujących się między sobą w celu przetworzenia aszumionyh sygnaģów pochodzących z wielu rozproszonych žródeģ. Lesser i Erman przewidzieli zastosowania w kilku obszarach, w tym w "sieciach czujników (skģadających się z radaru maģej mocy, detektorów akustycznych lub optycznych, sejsmometrów, hydrofonów itp.), kontroli ruchu w sieci (motoryzacyjnej), kontroli zapasów (na przykģad wynajmu samochodów) , sieci elektroenergetyczne i zadania z wykorzystaniem robotów mobilnych ". Jak zauwaŋyli, "architektura, która lokalizuje moŋliwoķci przetwarzania w lokalizacjach czujników i wymaga jedynie ograniczonej komunikacji między procesorami, jest szczególnie korzystna i byæ moŋe jest to jedyny sposób, aby sprostaæ wymaganiom odpowiedzi w czasie rzeczywistym, ograniczonej przepustowoķci komunikacji oraz niezawodnoķci." Lesser i koledzy kontynuuowali prace nad systemami wieloagentowymi w MAS Lab na University of Massachusetts w Amherst. Opierając się na pracy w ramach projektu DISTRIBUTED HEARSAY-II, opracowali "Distributed Vehicle Monitoring Testbed" (DVMT). Badania z wykorzystaniem stanowiska testowego koncentrowaģy się na ķledzeniu ruchu pojazdu za pomocą rozproszonej sieci czujników i byģy žródģem informacji do testowania metod kooperacyjnego, rozproszonego rozwiązywania problemów. Po pracach DVMT przeprowadzono szereg innych projektów systemów wieloagentowych. Na przeģomie lat 70. i 80. opracowano kilka pomysģów koordynowania dziaģaņ wielu agentów. Jednym z nich byģ system Contract Net opracowany przez Reida Smitha. Opieraģ się on na protokole i "procesie negocjacji" w celu "komunikacji i kontroli rozwiązywania problemów dla węzģów w rozproszonym rozwiązaniu problemu". Wczesna aplikacja obejmowaģa rozproszoną sieæ czujników, w której lokalizacje i typy czujników byģy znane dopiero po wdroŋeniu czujnika. Innym waŋnym systemem byģ "Multi-Agent Computing Environment" (MACE) opracowany przez Lesa Gassera i wspóģpracowników z University of Southern California. Artykuģ o MACE opisuje to w następujący sposób:
"MACE… jest instrumentalnym testem do budowy szerokiej gamy eksperymentalnych systemów rozproszonej sztucznej inteligencji…Jednostki obliczeniowe MACE (zwane "agentami") dziaģają równolegle i komunikują się za poķrednictwem komunikatów. Zapewniają opcjonalne udogodnienia dla reprezentacja wiedzy (ķwiatowa wiedza, modele innych agentów, ich cele i plany, ich role i moŋliwoķci itp.) oraz moŋliwoķci wnioskowania"
Ciekawa aplikacja do badaņ systemów wieloagentowych obejmuje roboty wspóģpracujące (i konkurencyjne). Profesor Manuela Veloso z Carnegie Mellon University jest jednym z gģównych badaczy pracujących w tej dziedzinie. Oprócz pracy nad "badaniami nad inteligentnymi robotami, które wspóģpracują, obserwują, rozumują, dziaģają i uczą się", byģa aktywna w meczach RoboCup robotów grających w piģkę noŋną. Zazwyczaj w tych meczach kaŋdy robot ma wģasne moŋliwoķci wykrywania i przetwarzania. Kaŋdy musi wziąæ pod uwagę dziaģania innych graczy i ich dziaģania. RoboCup to międzynarodowy wspólny projekt. . . wspieranie badaņ nad sztuczną inteligencją i inteligentnymi robotami poprzez dostarczenie standardowego problemu, w którym moŋna zintegrowaæ i zbadaæ szeroki zakres technologii. "Jego ostatecznym celem jest rozwój zespoģu w peģni autonomicznych robotów humanoidalnych, które [do 2050 r.] mogą wygraæ z druŋyna mistrzów ķwiata w piģce noŋnej. " Niektórzy z was będą w pobliŋu, aby zobaczyæ.
Gdy otoczenie obejmuje innych agentów, z którymi agent musi wspóģpracowaæ lub konkurowaæ, waŋne jest, aby ten agent posiadaģ modele tych innych agentów jako częķæ swojego modelu ķrodowiskowego. Modele te powinny zawieraæ informacje o tym, w co wierzą inni agenci i jak moŋna modyfikowaæ te przekonania. Aby poradziæ sobie z takimi sprawami, badacze zaczęli rozwaŋaæ problemy, takie jak to, jak agent A powinien reprezentowaæ dla siebie, ŋe agent B zna jakiķ fakt P i pod jakimi warunkami agent A powinien powiedzieæ jakiķ fakt P, agentowi B. Jedną z gģównych trudnoķci byģo rozróŋnienie między A wiedzącym, ŋe B wie (P ∨ Q), a A wiedzącym, ŋe B zna P lub B wie P: Innym byģo to, w jaki sposób agent A moŋe uzasadniæ przekazanie agentowi B faktu na temat jakiegoķ obiektu, powiedzmy OB, gdy A nie zna nazwy, którą B uŋywa dla OB. Jeszcze inna dotyczyģa tego, co A mógģby zaģoŋyæ na temat wniosków, do których B moŋe dojķæ Wģasna rea B. procesy soningowe. Zaproponowano róŋne rozwiązania. Najwaŋniejsze z nich dotyczyģo tak zwanej "logiki epistemicznej" (logiki wiary).
Agent, który ma wiedzę na temat tego, co wie inny agent i co moŋe wyciągnąæ, jest w stanie spróbowaæ dodaæ, poprawiæ lub wyciągnąæ wnioski z wiedzy tego innego agenta. Dostosowanie i uczenie się na podstawie wiedzy innego agenta jest kluczem do wspóģpracy między agentami i wymaga komunikacji od nadawcy do odbiorcy oraz zrozumienia i moŋliwej zgodnoķci ze strony odbiorcy. Naukowcy zauwaŋyli, ŋe istnieje kilka rodzajów dziaģaņ komunikacyjnych. Są one zwykle nazywane "aktami mowy", nawet jeķli komunikacja odbywa się za pomocą ķrodków innych niŋ mowa. Wiele z tych rodzajów zostaģo wczeķniej sklasyfikowanych przez Johna Searle′a po pracy Johna L. Austina. Gģównymi z nich do uŋytku przez wielu agentów są "asertywni" "za przekazywanie faktów od jednego agenta do drugiego", "dyrektywy" dotyczące ŋądania lub nakazania odbiorcy podjęcia pewnych dziaģaņ oraz "komisje" za obietnicę, ŋe nadawca popeģni pewne dziaģanie. Gdy komunikacja między agentami zostanie rozpatrzona w kategoriach dziaģaņ, moŋna pomyķleæ o generowaniu planów za pomocą tych dziaģaņ: Philip R. Cohen z BBN i C. Raymond Perrault z University of Toronto byli wķród tych, którzy to zrobili. REQUEST i INFORM (na podstawie wczeķniejszych "asertywów" i "dyrektyw") oraz proponowane warunki, na jakich moŋna by wykonaæ te akty i jakie byģyby ich skutki. Warunki i skutki zostaģy okreķlone w kategoriach logicznych wyraŋeņ lub umieszczane w bazach wiedzy nadawcy i odbiorcy (lub pochodnych) (Zaģoŋono, ŋe zarówno nadawca, jak i odbiorca musi mieæ wiedzę na temat wzajemnej znajomoķci i tego, ŋe mogliby ją uzasadniæ.) System planowania, podobnie jak STRIPS, mógģby następnie generowaæ plany skģadające się z wystąpieņ aktów mowy, które osiągnęģyby poŋądane efekty. Akty mowy Cohena i Perraulta stanowiģy podstawę akronimu KQML dla języka manipulacji kwerendą wiedzy. KQML zostaģ opracowany przy wsparciu DARPA w ramach inicjatywy "dzielenia się wiedzą" .Okreķla róŋne dziaģania komunikacyjne, które mogą odbywaæ się między agentami, takie jak pytanie-jeķli, informowanie, mówienie i odpowiadanie. KQML wykorzystuje KIF (format wymiany wiedzy), a język oparty na rachunku predykatu pierwszego rzędu, do wyraŋania zawartoķci wiadomoķci. Gdy więc agent A chce wysģaæ wiadomoķæ do agenta B, koduje treķæ wiadomoķci w KIF, a następnie zawija ją w odpowiednie dziaģanie komunikacyjne KQML Oto na przykģad typowe okno dialogowe KQML / KIF:
A to B: (ask-if (> (size chip1) (size chip2)))
B to A: (reply true)
B to A: (inform (= (size chip1) 20))
B to A: (inform (= (size chip2) 18))
Fundacja na rzecz inteligentnych agentów fizycznych (FIPA), zainspirowana projektami takimi jak KQML i KIF, powstaģa w Szwajcarii w 1996 roku. FIPA jest obecnie jednym z komitetów normalizacyjnych Towarzystwa Komputerowego IEEE. Jego standardy "mają na celu promowanie wspóģpracy heterogenicznych agentów i usģug, które mogą reprezentowaæ". Zajmują się komunikatami "Agent Communication Language" (ACL) i przewidują "protokoģy interakcji wymiany komunikatów, akty komunikacyjne oparte na teorii mowy i reprezentacje językowe treķci ". Obecnie istnieje kilka systemów i języków do wdraŋania systemów wieloagentowych. Na przykģad interpreter Jason typu open source dla języka opartego na logice AgentSpeak zapewnia uŋytkownikom platformę do tworzenia zģoŋonych systemów wieloagentowych. Chociaŋ wiele pracy nad systemami wieloagentowymi koncentrowaģo się na aplikacjach, w których kilku agentów wspóģpracuje w celu rozwiązania jakiegoķ ogólnego problemu, zdarza się równieŋ, ŋe agenci mogą byæ zainteresowani sobą, co moŋe prowadziæ do rywalizacji między nimi. Przykģadem mogą byæ przeciwne druŋyny robotów grających w piģkę noŋną. Innymi przykģadami są agenci zajmujący się handlem, np. kupujący i sprzedający (prawdopodobnie dziaģający dla ludzi). Te aspekty badaņ wieloagentowych obejmują negocjacje i aukcje. Istnieją dobrze znane ramy, a mianowicie teoria gier do radzenia sobie z sytuacjami, w których sukces agenta w dokonywaniu wyborów zaleŋy od wyborów innych agentów. Teorię gier wprowadzili do badaņ systemów wieloagentowych Jeff Rosenschein (1957 {) i Michael Genesereth (1948 {) w swoim artykule "Oferty wķród racjonalnych agentów". Obecnie systemy wieloagentowe stanowią gģówny podtemat sztucznej inteligencji, a teoria mowy i teoria gier naleŋą do jej waŋnych podstaw teoretycznych.
Architektury poznawcze
Systemy produkcyjne
Allen Newell i Herb Simon byli jednymi z pierwszych zainteresowanych komputerowymi modelami rozwiązywania problemów u ludzi. Opisanojuŋ GPS, General Problem Solver, który moŋna uznaæ za jedną z pierwszych architektur procesów poznawczych. W tej częķci opiszę kilka innych tak zwanych architektur poznawczych. Jak póžniej ujęli twórcy jednej rodziny tych architektur, [Architektura poznawcza] stanowi staģą bazę ķciķle powiązanych mechanizmów leŋących u podstaw inteligentnego zachowania. Architektura [taka] stanowi następnie podstawę do szeroko zakrojonych badaņ podstawowych inteligentnych moŋliwoķci {takich jak rozwiązywanie problemów, planowanie, uczenie się, reprezentacja wiedzy, język naturalny, percepcja i robotyka -a takŋe zastosowania w takich obszarach, jak systemy eksperckie i modelowanie psychologiczne
Po pracy nad GPS, Newell i Simon skupili się na "systemach produkcyjnych", modelach wykorzystujących reguģy IF - THEN, zwane produkcjami. Aby wygenerowaæ podzadania, Newell i Simon byli zainteresowani zastosowaniem tych reguģ do tworzenia akcji. Częķæ IF byģa, jak zwykle, warunkiem, a częķæ THEN byģa akcją, która zostaģa wykonana, jeķli warunek zostaģ speģniony w modelu. Newell i Simon wymyķlili architekturę skģadającą się z dwóch rodzajów struktur pamięci. Jedna, "pamięæ dģugoterminowa", skģada się z reguģ produkcji. Druga, pamięæ krótkotrwaģa lub "pamięæ robocza", zawiera dynamiczne informacje o wykonywanym zadaniu. Pamięæ dģugoterminowa utrzymuje się z czasem i moŋe zawierają tysiące reguģ. Pamięæ robocza zawiera dane, które mają byæ testowane przez częķci warunków reguģ. Gdy warunek jest częķcią reguģy , dopasowuje dane w pamięci roboczej, która reguģa "odpala"; to znaczy wykonywana jest jego częķæ akcji. Wykonanie moŋe spowodowaæ zapis lub usunięcie (lub oba) niektórych danych w pamięci roboczej lub podjęcie pewnych dziaģaņ w ķrodowisku zewnętrznym. Kiedy dane w pamięci roboczej są zmieniane, róŋne reguģy są czerwone, co ponownie zmienia dane i tak dalej. W przypadku, gdy więcej niŋ jedna częķæ warunku reguģy pasuje do danych w pamięci roboczej (co byģoby normalne), "Conflict Resolver" wybiera, który z nich (lub w przypadku pracy równolegģej) powinien zostaæ uruchomiony. W tej wersji architektury, która generuje dziaģania w ķrodowisku zewnętrznym, system "Percepcji" jest w stanie zapisywaæ dane w pamięci krótkotrwaģej, reprezentując wszelkie istotne cechy aktualnego stanu ķrodowiska. Newell i Simon przeprowadzili szeroko zakrojoną eksperymentalną pracę z ludzkimi podmiotami wykonującymi zadania rozwiązywania problemów {pokazując, ŋe ich wydajnoķæ moŋna dobrze modelowaæ przez dziaģanie wersji tego schematu architektonicznego. Ich ksiąŋka Human Problem Solving jest opisem większoķci tej pracy. Przewaŋnie uwaŋali, ŋe ich architektura systemu produkcyjnego jest wkģadem w badania naukowe nad poznaniem czģowieka, a nie propozycją strukturyzowania systemów AI. Komentując swoją ksiąŋkę, Newell napisaģ póžniej: "Celem byģo wykazanie, ŋe psychologia jest wykonywana, a nie coķ, co moŋna by zaszufladkowaæ w powiązaniu z komputerami". Jednak inni kojarzyli systemy produkcyjne z komputerami, w szczególnoķci za pomocą języka komputerowego OPS5. Póžniejsze propozycje architektur poznawczych, a mianowicie ACT-R i SOAR, byģy pod wpģywem modelu systemu produkcyjnego i byģy wykorzystywane zarówno jako modele rozwiązywania problemów, jak i architektury systemów AI. Opiszę następnie te systemy
ACT-R
John R. Anderson i inni opracowali szereg architektur poznawczych zwanych ACT (Adaptive Control of Thought) na Uniwersytecie Carnegie Mellon. Najnowsze z tej serii modeli jest ACT-R ("R" oznacza racjonalne). Wedģug strony internetowej ACT-R jest architekturą poznawczą: teorią symulującą i rozumiejącą ludzkie poznanie. Badacze pracujący nad ACT-R starają się zrozumieæ, w jaki sposób ludzie organizują wiedzę i wytwarzają inteligentne zachowania. W trakcie badaņ ACT-R ewoluuje coraz bliŋej w system, który moŋe wykonywaæ peģen zakres ludzkich zadaņ poznawczych: szczegóģowo uchwyciæ sposób, w jaki postrzegamy ķwiat, myķlimy o nim i dziaģamy na nim. Istnieją trzy gģówne elementy: moduģy, bufory i dopasowywanie wzorców. Moduģ silnika moŋe oddziaģywaæ na ķrodowisko poprzez procedury silnika lub na bufory ACT-R. Oprócz pokazanego moduģu wizualnego mogą istnieæ inne moduģy percepcyjne dla odsģuchu, dotyku i tak dalej. Istnieją dwa typy moduģów pamięci w ACT-R. Pamięæ deklaratywna skģada się z faktów, takich jak "Waszyngton, DC jest stolicą Stanów Zjednoczonych, Francja jest krajem w Europie, lub 2 + 3 = 5".Wiedza deklaratywna jest reprezentowana w ACT-R przez jednostki zwane fragmentami. skģada się z reguģ produkcji reprezentujących "wiedzę o tym, jak to robimy: na przykģad wiedzę o tym, jak wpisaæ literę "Q" na klawiaturze, o tym, jak prowadziæ, lub jak wykonaæ dodawanie ". Często nie jesteķmy w stanie werbalizowaæ naszej wiedzy o tym, jak robimy pewne rzeczy: po prostu to robimy; dlatego wiedza o nich jest uwaŋana za proceduralną, a nie deklaratywną. Bufory w ACT-R sģuŋą jako interfejsy między moduģami. "Zawartoķæ buforów w danym momencie reprezentuje stan ACT-R w tym momencie. Moduģ dopasowujący wyszukuje produkcję, która pasuje do bieŋącego stanu buforów. Tylko jedna taka produkcja moŋe byæ wykonana w w danym momencie. Ta produkcja, gdy jest wykonywana, moŋe modyfikowaæ bufory i tym samym zmieniaæ stan systemu. Zatem w ACT-R poznanie rozwija się jako seria pierķcieni produkcyjnych. " Wedģug jednej ze stron internetowych ACT-R
ACT-R to hybrydowa architektura poznawcza. Jego symboliczną strukturą jest system produkcyjny; struktura podsymboliczna jest reprezentowana przez zbiór masowo równolegģych procesów, które moŋna streķciæ za pomocą szeregu równaņ matematycznych. Równania subsymboliczne kontrolują wiele procesów symbolicznych. Na przykģad, jeķli kilka produkcji pasuje do stanu buforów, równanie uŋytecznoķci podsymbolicznej szacuje względny koszt i korzyķæ związane z kaŋdą produkcją i decyduje się wybraæ do wykonania produkcję o najwyŋszej uŋytecznoķci. Podobnie to, czy (lub jak szybko) fakt moŋna odzyskaæ z pamięci deklaratywnej, zaleŋy od subymbolicznych równaņ wyszukiwania, które uwzględniają kontekst i historię uŋycia tego faktu. Mechanizmy subsymboliczne są równieŋ odpowiedzialne za większoķæ procesów uczenia się w ACT-R.
Modele ACT-R zostaģy wykorzystane do wyjaķnienia i symulacji szerokiej gamy zachowaņ poznawczych u ludzi, w tym uczenia się, przetwarzania języka, percepcji, rozwiązywania problemów i podejmowania decyzji. Istnieją setki (jeķli nie tysiące) artykuģów opisujących tę pracę. Zastosowania ACT-R obejmują szeroki zakres tematów, od na przykģad "przewidywania wpģywu wybierania numeru telefonu komórkowego na wydajnoķæ kierowcy" po inteligentne systemy nauczania. W aplikacjach bardziej bezpoķrednio związanych z AI, Greg Trafton i Alan C. Schultz w marynarce wojennej , Centrum Badaņ Stosowanych w Inteligencji Sztucznej (NCARAI) buduje "wbudowanego robota poznawczego" przy uŋyciu wersji ACT-R, którą nazywają ACT-R / E. Obejmuje "moduģy wizualne i sģuchowe" oraz "moduģy motoryczne i przestrzenne" do percepcji i dziaģania. Oprócz roli w wyjaķnianiu procesów psychologicznych, badania funkcjonalnego obrazowania rezonansu magnetycznego (fMRI) zostaģy wykorzystane do powiązania elementów architektury ACT-R z regionami mózgu aktywnymi w zģoŋonych zadaniach.
SOAR
Na początku lat osiemdziesiątych John Laird, Allen Newell i Paul Rosenbloom rozpoczęli opracowywanie serii architektur poznawczych o nazwie SOAR (która, jak się pierwotnie mówi, byģa akronim od stanu, operatora i wyniku). Twórcy SOAR powiedzieli, ŋe "ich ostatecznym celem dla architektury SOAR jest to, ŋe sģuŋy ona jako podstawa zarówno dla ludzkiego, jak i sztucznego poznania". Podobnie jak ACT, SOAR ewoluowaģ z pracy Newella i Simona nad GPS i systemami produkcyjnymi i zawieraģ pomysģy dotyczące przestrzeni problemowych, wyszukiwania heurystycznego, nabywania umiejętnoķci poznawczych i uczenia się. Laird i Rosenbloom byli doktorantami Newella i mieli ukoņczone rozprawy na temat aspektów SOAR. Istnieje szereg architektur SOAR, SOAR1 (w 1982 r.) Do SOAR9 (2008), kaŋda z ulepszeniami w stosunku do swojego poprzednika. Niektóre z najnowszych wersji oprogramowania SOAR moŋna pobraæ z Internetu. Dokģadne zrozumienie, w jaki sposób te róŋne wersje SOAR moŋna najlepiej uzyskaæ, ķledząc niektóre przykģady w artykuģach i artykuģach na temat SOAR.. SOAR jest czymķ w rodzaju języka programowania z zestawem staģych procedur . Za pomocą tych procedur moŋna "zaprogramowaæ" róŋne rodzaje zadaņ w SOAR. Przykģady obejmują zarówno ulubione problemy sztucznej inteligencji "zabawki" (takie jak ósma ukģadanka), jak i aplikacje "rzeczywiste" (takie jak konfiguracja systemów komputerowych i sterowanie robotem). SOAR rozwiązuje kaŋde powierzone mu zadanie, tworząc i rozwiązując hierarchię podzadania. Kaŋde zadanie (w tym gģówne i kaŋde podzadania) jest postawiony jako cel znalezienia poŋądanego stanu w "przestrzeni problemowej" skģadającej się z zestawu operatorów, które odnoszą się do bieŋącego stanu w celu wytworzenia nowego stanu. Aby skonfigurowaæ przestrzeņ problemową, SOAR musi znaæ jej aktualny stan i jakie operatory moŋna zastosowaæ do tego stanu. Jeķli nie zna tych rzeczy bezpoķrednio, powiedzmy z wczeķniejszych doķwiadczeņ, tworzy pomocniczą przestrzeņ problemów, której celem jest ich odkrycie (i tak dalej). Gdy SOAR zdefiniuje przestrzeņ problemową, musi wybraæ operatora, który zastosuje się do bieŋącego stanu w tej przestrzeni. Jeķli nie wie juŋ, który operator zastosowaæ, tworzy pomocniczą przestrzeņ problemów, której celem jest znalezienie. Jak stwierdzono w tomie dokumentów SOAR, "mechanizmy SOAR tworzą ķciķle powiązaną hierarchię warstw - pamięæ, decyzja i cel {w którym kaŋda warstwa tworzy wewnętrzną pętlę warstwy nad nią. Te warstwy rosną stopniowo zarówno pod względem zģoŋonoķci, jak i czasu skaluj od doģu do góry hierarchii. " Konfigurowanie pomocniczych obszarów problemowych nazywa się "uniwersalnym podzadaniem" co moŋe skutkowaæ gģębokim drzewem podzadaņ i obszarów problemowych. Gdy dotyczą one decyzji kontrolnych (na przykģad, który operator zastosowaæ), moŋna powiedzieæ, ŋe SOAR "odzwierciedla" swoje wģasne zachowanie związane z rozwiązywaniem problemów. Proces uniwersalnego subgoalingu moŋe wywoģywaæ róŋnorodne tak zwane sģabe metody, takie jak wspinanie się na wzgórze, analiza ķrodków i wyszukiwanie heurystyczne, w zaleŋnoķci od wiedzy, którą SOAR wczeķniej nauczyģ się o rodzaju zadania, nad którym pracuje System produkcyjny, ze zwykģymi strukturami pamięci dģugo- i krótkoterminowej, sģuŋy do ustawiania przestrzeni problemowych. Pamięæ dģugoterminowa (LTM) przechowuje informacje niezaleŋne od bieŋącej sytuacji. Pamięæ krótkotrwaģa lub robocza (WM) zawiera informacje, które są najbardziej istotne w obecnej sytuacji. SOAR uczy się, buforując wyniki swoich doķwiadczeņ związanych z rozwiązywaniem problemów, zarówno jako produkcje w LTM, jak i ogólne fakty w WM dotyczące poprzednich sytuacji, które mogą byæ przydatne w przyszģych sytuacjach. Zestawienie sekwencji uczenia się wczeķniej doķwiadczonych ķladów rozwiązywania problemów nazywa się "dzieleniem", czasem uŋywanym do opisania analogicznego uczenia się u ludzi. Istnieją trzy rodzaje struktur LTM, a mianowicie: proceduralne, semantyczne i epizodyczne. Oto jak opisuje je jeden z artykuģów SOAR:
Wiedza proceduralna dotyczy tego, jak i kiedy robiæ rzeczy - jak ježdziæ na rowerze, jak rozwiązaæ problem algebry lub jak przeczytaæ przepis i uŋyæ go do upieczenia ciasta. Wiedza semantyczna skģada się z faktów o ķwiecie -rzeczy, które ogólnie uwaŋasz za prawdziwe - rzeczy, które "znasz", takie jak rowery, mają dwa koģa, mecz baseballowy ma dziewięæ zmian, a zmiana ma trzy zmiany. Wiedza epizodyczna skģada się z rzeczy, które "pamiętasz" - specyficzne sytuacje, których doķwiadczyģeķ, takie jak chwila, w której wypadģeķ z roweru i podrapaģeķ się w ģokieæ.
LTM nie jest bezpoķrednio dostępny, ale naleŋy go "przeszukaæ", aby znaležæ to, co jest istotne w obecnej sytuacji. Mówiąc to nieco bardziej intuicyjnie, warto pomyķleæ o tym, ŋe LTM zawiera to, co moŋe byæ istotne w wielu róŋnych sytuacjach, ale musi zostaæ jawnie odzyskane, a WM jako zawierający to, co wedģug modelu jest istotne dla konkretnej sytuacji, w której się obecnie znajduje. Jednym z kluczowych rozróŋnieņ między WM i LTM jest to, ŋe wiedza w pamięci roboczej moŋe byæ wykorzystana do odzyskania innej wiedzy z LTM, podczas gdy LTM musi byæ najpierw odzyskane do WM. Wiedza przenosi się z LTM do WM zarówno poprzez automatyczne, jak i celowe wyszukiwanie odpowiednich struktur LTM. Architektura SOAR (w róŋnych wersjach) byģa uŋywana przez naukowcy z caģego ķwiata do róŋnych zadaņ. Intencją osób pracujących nad SOAR jest :
• praca nad peģnym zakresem zadaņ oczekiwanych od inteligentnego agenta, od rutynowych do niezwykle trudnych, otwartych problemów,
• reprezentowaæ i wykorzystywaæ odpowiednie formy wiedzy, takie jak proceduralna, deklaratywna, epizodyczna i byæ moŋe kultowa,
• stosowaæ peģen zakres metod rozwiązywania problemów,
• interakcja ze ķwiatem zewnętrznym, oraz
• poznaæ wszystkie aspekty zadaņ i ich wykonywania na nich.
To wysokie zamówienie, więc bądžcie czujni. Jednym z interesujących obszarów zastosowania SOAR byģo programowanie automatycznych agentów jako stand-in dla ludzi w symulowanych æwiczeniach treningowych. Na przykģad TacAir-SOAR symuluje inteligentne zachowanie pilota taktycznego myķliwca. W 1998 r. Laird zaģoŋyģ SOAR Technology, firmę Ann Arbor (Michigan) specjalizującą się w tworzeniu autonomicznych jednostek AI wykoryzstujących architekturę SOAR. ACT-R i SOAR są prawdopodobnie najbardziej znanymi architekturami poznawczymi, ale są teŋ inne.