Tak jak poprzednio, pierwszym krokiem jest użycie matrycy senator po głosowaniu do stworzenia macierzy odległości senator po senatorze, na której wykonamy MDS. Użyjemy funkcji lapply do wykonania kroków konwersji dla każdego Kongresu osobno. Zaczynamy od mnożenia macierzy i zapisywania wyników w zmiennej rollcall.dist. Następnie wykonujemy MDS za pomocą funkcji cmdscale za pomocą innego wywołania do okrążenia zagięcie. Należy zwrócić uwagę na dwie rzeczy związane z działaniem MDS. Po pierwsze, domyślnie cmdscale oblicza MDS dla dwóch wymiarów, więc jesteśmy zbędni, ustawiając k = 2. Przydatne jest jednak wyraźne wyrażanie się podczas wykonywania tej operacji podczas udostępniania kodu, dlatego dodajemy go tutaj jako najlepszą praktykę. Po drugie, zauważ, że mnożymy wszystkie punkty przez –1. Odbywa się to wyłącznie w celu wizualizacji, odwrócenie pozycjonowania osi x wszystkich punktów, i jak zobaczymy, umieszcza Demokratów po lewej stronie i republikanów po prawej. W kontekście amerykańskim jest to przydatna wskazówka wizualna, ponieważ zazwyczaj myślimy o Demokratach jako ideologicznie lewicy, a republikanach o prawicy. Jak zapewne się domyślacie, zauważyliśmy tylko, że Demokraci znajdą się po prawej stronie, a republikanie po lewej stronie punktów osi X dla MDS po wizualizacji. Częścią dobrego wykonywania analizy danych jest elastyczność i krytyczne myślenie o tym, jak możesz poprawić swoją metodę lub prezentację wyników po zakończeniu im. Chociaż więc prezentujemy to tutaj liniowo, należy pamiętać, że w praktyce decyzja o odwróceniu osi x w wizualizacji zapadła dopiero po pierwszym przejściu ćwiczenia.
rollcall.dist <- lapply (rollcall.simple, function (m) dist (m% *% t (m)))
rollcall.mds <- lapply (rollcall.dist,
function (d) as.data.frame ((cmdscale (d, k = 2)) * -1))
Następnie musimy dodać odpowiednie dane identyfikacyjne do ramek danych punktów współrzędnych w rollcall.mds, abyśmy mogli je wizualizować w kontekście przynależności do partii. W następnym bloku kodu zrobimy to za pomocą prostej pętli for na liście rollcall.mds. Najpierw ustawiamy nazwy kolumn punktów współrzędnych na x i y. Następnie uzyskujemy dostęp do oryginalnych ramek danych wywołania w rollcall.data i wyodrębniamy kolumnę nazw senatorów. Przypomnijmy, że musimy najpierw usunąć wiceprezydenta. Ponadto niektóre nazwiska senatorów obejmują imiona i nazwiska, ale w większości tylko ostatnie. Aby zachować spójność, usuwamy imiona, dzieląc wektor znaków nazwy przecinkiem i przechowujemy ten wektor w zmiennej congress.names. Na koniec używamy funkcji transformacji, aby dodać przynależność do partii jako czynnik i dodać numer Kongresu.
congresses <- 101:111
for(i in 1:length(rollcall.mds)) {
names(rollcall.mds[[i]]) <- c(“x”, “y”)
congress <- subset(rollcall.data[[i]], state < 99)
congress.names <- sapply(as.character(congress$name),
function(n) strsplit(n, “[, ]”)[[1]][1])
rollcall.mds[[i]] <- transform(rollcall.mds[[i]], name=congress.names,
party=as.factor(congress$party), congress=congresses[i])
}
head(rollcall.mds[[1]])
x y name party congress
2 -11.44068 293.0001 SHELBY 100 101
3 283.82580 132.4369 HEFLIN 100 101
4 885.85564 430.3451 STEVENS 200 101
5 1714.21327 185.5262 MURKOWSKI 200 101
6 -843.58421 220.1038 DECONCINI 100 101
7 1594.50998 225.8166 MCCAIN 200 101
Sprawdzając nagłówek pierwszego elementu w rollcall.mds po dodaniu danych kontekstowych, możemy zobaczyć ramkę danych, której użyjemy do wizualizacji. W pliku kodu R zawartym w tej sekcji mamy długi zestaw poleceń do zapętlania tej listy ramek danych w celu tworzenia indywidualnych wizualizacji dla wszystkich kongresów. Dla zwięzłości zamieszczamy tutaj jednak tylko część tego kodu. Podany kod wykreśli dane dla 110. Senatu, ale można go łatwo zmodyfikować w celu wykreślenia każdego innego Kongresu.
cong.110 <- rollcall.mds[[9]]
base.110 <- ggplot(cong.110, aes(x=x, y=y))+scale_size(to=c(2,2), legend=FALSE)+
scale_alpha(legend=FALSE)+theme_bw()+
opts(axis.ticks=theme_blank(), axis.text.x=theme_blank(),
axis.text.y=theme_blank(),
title=”Roll Call Vote MDS Clustering for 110th U.S. Senate”,
panel.grid.major=theme_blank())+
xlab(“”)+ylab(“”)+scale_shape(name=”Party”, breaks=c(“100″,”200″,”328”),
labels=c(“Dem.”, “Rep.”, “Ind.”), solid=FALSE)+
scale_color_manual(name=”Party”, values=c(“100″=”black”,”200″=”dimgray”,
“328”=”grey”),
breaks=c(“100″,”200″,”328”), labels=c(“Dem.”, “Rep.”, “Ind.”))
print(base.110+geom_point(aes(shape=party, alpha=0.75, size=2)))
print(base.110+geom_text(aes(color=party, alpha=0.75, label=cong.110$name, size=2)))
Wiele z tego, co robimy z ggplot2, powinno być już znane. Jednak w tym przypadku korzystamy z jednej niewielkiej zmiany w sposobie budowania grafiki.
Typową procedurą jest utworzenie obiektu ggplot, a następnie dodanie warstwy geom lub stat, ale w tym przypadku tworzymy obiekt podstawowy o nazwie case.110, który zawiera wszystkie szczegóły dotyczące formatowania tych wykresów. Obejmuje to warstwy rozmiaru, alfa, kształtu, koloru i opts. Robimy to, ponieważ chcemy zrobić dwa wykresy: po pierwsze wykres samych punktów, w których kształt odpowiada przynależności do partii; a po drugie, fabuła, w której nazwiska senatorów są używane jako punkty, a kolor tekstu odpowiada przynależności do partii. Najpierw dodając wszystkie te warstwy formatujące do base.110, możemy po prostu dodać do bazy warstwę sgeom_point lub geom_text, aby uzyskać żądany wykres. Rysunek pokazuje wyniki tych wykresów.

Zaczynamy od odpowiedzi na nasze początkowe pytanie: czy senatorowie z różnych partii mieszają się, gdy są zebrani według rekordów głosowania imiennego? Na rysunku odpowiedź jest jednoznaczna „nie”. Wydaje się, że istnieje dość duża różnica między demokratami a republikanami. Dane potwierdzają również, że senatorzy często uważani za najbardziej ekstremalnych, są w rzeczywistości wartościami odstającymi. Po lewej stronie widzimy Senatora Sandersa, niezależnego Vermonta, a po prawej senatorów Coburna i DeMinta. Podobnie senatorzy Collins i Snowe są ściśle skupieni w centrum 111. Kongresu. Jak zapewne pamiętacie, to ci umiarkowani republikańscy senatorowie stali się centralnymi postaciami w wielu ostatnich wielkich bitwach legislacyjnych w Senacie USA. Innym interesującym wynikiem tej analizy jest pozycjonowanie senatorów Obamy i McCaina w 110. Senacie. Obama wydaje się wyróżniony w lewej górnej ćwiartce fabuły, podczas gdy McCain jest skupiony z senatorami Wicker i Thomasem, bliżej centrum. Chociaż może to być kuszące, aby interpretować to jako oznaczające, że dwaj senatorowie mieli bardzo komplementarne zapisy z głosowania, biorąc pod uwagę charakter kodowania danych, bardziej prawdopodobne jest, że w wyniku kampanii brakuje dwóch takich samych głosów. Oznacza to, że kiedy głosowali nad tym samym projektem ustawy, mogli mieć stosunkowo różne nawyki głosowania, chociaż nie bardzo różne zapisy głosowania, ale kiedy brakowało głosów, często dotyczyło tego samego aktu prawnego. Oczywiście rodzi się pytanie: jak interpretujemy pozycję Wiklina i Thomasa? Dla naszej ostatecznej wizualizacji zbadamy wykresy MDS dla wszystkich kongresów w czasie chronologicznym. To powinno dać nam pewne wskazówki na temat ogólnego mieszania senatorów przez partię w czasie, a to da nam bardziej zasadnicze spojrzenie na stwierdzenie, że Senat jest bardziej spolaryzowany niż kiedykolwiek wcześniej. W poprzednim bloku kodu generujemy pojedynczy wykres ze wszystkich danych, zwijając rollcall.mds w pojedynczą ramkę danych za pomocą do.call i rbind. Następnie tworzymy dokładnie ten sam wykres, który stworzyliśmy w poprzednim kroku, z tym wyjątkiem, że dodajemy facet_wrap, aby wyświetlić wykresy MDS w chronologicznej siatce według Kongresu. Rysunek 9-5 przedstawia wyniki tej wizualizacji.
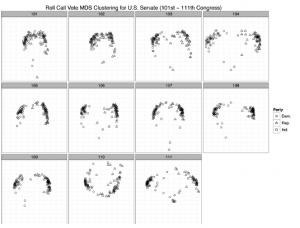
all.mds <- do.call(rbind, rollcall.mds)
all.plot <- ggplot(all.mds, aes(x=x, y=y))+
geom_point(aes(shape=party, alpha=0.75, size=2))+
scale_size(to=c(2,2), legend=FALSE)+
scale_alpha(legend=FALSE)+theme_bw()+
opts(axis.ticks=theme_blank(), axis.text.x=theme_blank(),
axis.text.y=theme_blank(),
title=”Roll Call Vote MDS Clustering for U.S. Senate
(101st – 111th Congress)”,
panel.grid.major=theme_blank())+
xlab(“”)+ylab(“”)+
scale_shape(name=”Party”, breaks=c(“100″,”200″,”328”),
labels=c(“Dem.”, “Rep.”, “Ind.”),
solid=FALSE)+facet_wrap(~ congress)
all.plot
Używając głosowania imiennego jako miernika różnicy między senatorami, z tych wyników wynika, że senat USA jest tak samo stronniczy, jak nigdy dotąd. Ogólnie rzecz biorąc, widzimy tylko duże grupy trójkątów i kół skupionych razem, z niewielką liczbą wyjątków na każdym Kongresie. Można powiedzieć, że 101. i 102. kongresy były mniej spolaryzowane, ponieważ klastry wydają się być bliżej. Ale to jest artefakt skali osi. Przypomnijmy, że procedura MDS stara się po prostu zminimalizować funkcję kosztów opartą na obliczonej macierzy odległości wśród wszystkich obserwacji. To, że skale dla 101. i 102. kongresu są mniejsze niż w przypadku wielu innych fabuł, nie oznacza, że kongresy te są mniej spolaryzowane. Różnice te mogą wynikać z wielu powodów, takich jak liczba obserwacji. Ponieważ jednak wizualizowaliśmy je na jednym wykresie, skale muszą być jednolite na wszystkich panelach, co może powodować ,że niektóre wydają się ściśnięte, a inne rozciągnięte. Ważną rzeczą wynikającą z tego spisku jest to, że bardzo mało jest mieszania się stron, gdy grupujesz je za pomocą głosowania imiennego. Chociaż wewnątrz partii mogą występować niewielkie różnice, jak widać po rozwarstwieniu punktów koła lub trójkąta, różnice między stronami są bardzo małe. W prawie wszystkich przypadkach widzimy Demokratów skupionych z Demokratami i Republikanów z Republikanami. Oczywiście istnieje wiele innych informacji poza przynależnością do partii, które można by dodać do tego wątku. Możemy na przykład zastanawiać się, czy senatorowie z tego samego regionu geograficznego gromadą razem. Albo możemy się zastanawiać, czy członkostwo w komitecie prowadzi do grupowania. To są wszystkie interesujące pytania i zachęcamy do lektury