Walidacja krzyżowa i legalizacja to zarówno potężne narzędzia, które pozwalają nam korzystać ze złożonych modeli, które mogą naśladować bardzo skomplikowane wzorce w naszych danych bez nadmiernego dopasowania. Jednym z najciekawszych przypadków, w których możemy zastosować regularyzację, jest użycie tekstu do przewidywania ciągłego wyniku; na przykład możemy spróbować przewidzieć, jak niestabilna będzie akcja na podstawie zgłoszeń z pierwszej oferty publicznej. Kiedy używamy tekstu jako danych wejściowych dla problemu regresji, prawie zawsze mamy znacznie więcej danych wejściowych (słów) niż obserwacji (dokumentów). Jeśli mamy więcej obserwacji niż 1-gram (pojedyncze słowa), możemy po prostu rozważyć 2-gramy (pary słów) lub 3-gramy (trojaczki słów), dopóki nie otrzymamy więcej n-gramów niż dokumentów. Ponieważ nasz zestaw danych ma więcej kolumn niż wierszy, nieregularna regresja liniowa zawsze spowoduje powstanie modelu overfit. Z tego powodu musimy zastosować jakąś formę regularyzacji, aby uzyskać jakiekolwiek znaczące wyniki. Aby dać ci poczucie tego problemu, przeanalizujemy proste studium przypadku, w którym staramy się przewidzieć względną popularność najlepiej sprzedających się książek, które O’Reilly kiedykolwiek opublikował, wykorzystując tylko ich opisy ich tylne okładki jako dane wejściowe. Aby przekształcić te opisy tekstowe w użyteczny zestaw danych wejściowych, przekonwertujemy opisy każdej książki na wektor liczenia słów, abyśmy mogli zobaczyć, jak często w każdym opisie występują słowa takie jak „the” i „Perl”. Wyniki naszej analizy będą teoretycznie listą słów w opisie książki, które przewidują wysoką sprzedaż. Oczywiście zawsze jest możliwe, że zadania przewidywania po prostu nie da się zrealizować. Może to wynikać z przypisywania przez model wysokich współczynników słowom zasadniczo arbitralnym. Oznacza to, że może być bardzo mało popularnych słów w opisach popularnych książek O’Reilly, ale ponieważ model tego nie wie, nadal będzie próbował dopasować dane i przypisać wartość niektórym słowom. Jednak w tym przypadku wyniki nie dostarczą żadnych nowych informacji na temat tego, co czyni te słowa użytecznymi. Ten problem nie pojawi się wyraźnie w tym przykładzie, ale bardzo ważne jest, aby o tym pamiętać podczas regresji tekstu. Na początek załaduj nasz nieprzetworzony zestaw danych i przekształć go w matrycę terminów dokumentu, używając pakietu tm, który wprowadziliśmy wcześniej:
ranks <- read.csv(‘data/oreilly.csv’, stringsAsFactors = FALSE)
library(‘tm’)
documents <- data.frame(Text = ranks$Long.Desc.)
row.names(documents) <- 1:nrow(documents)
corpus <- Corpus(DataframeSource(documents))
corpus <- tm_map(corpus, tolower)
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removeWords, stopwords(‘english’))
dtm <- DocumentTermMatrix(corpus)
Tutaj załadowaliśmy zestaw danych szeregów z pliku CSV, utworzyliśmy ramkę danych, która zawiera opisy książek w formacie, który rozumie tm, utworzyliśmy korpus z tej ramki danych, znormalizowaliśmy wielkość liter tekstu, usunięto białe znaki , usunęliśmy najczęstsze słowa w języku angielskim i zbudowaliśmy naszą matrycę terminów dokumentów. Po tych pracach zakończyliśmy wszystkie istotne transformacje, które musimy wprowadzić do naszych danych. Po ich zakończeniu możemy trochę manipulować naszymi zmiennymi, aby ułatwić opisanie naszego problemu z regresją w glmnet:
x <- as.matrix (dtm)
y <- rev (1: 100)
W tym miejscu przekonwertowaliśmy matrycę terminów dokumentów na prostą matrycę numeryczną, z którą łatwiej jest pracować. I zakodowaliśmy szeregi w odwrotnym kodowaniu, aby książka o najwyższym rankingu miała wartość y równą 100, a książka o najniższym rankingu miała wartość y równą 1. Robimy to, aby współczynniki, które przewidywały popularność książki są pozytywne, gdy sygnalizują wzrost popularności; gdybyśmy zamiast tego użyli surowych szeregów, współczynniki dla tych samych słów musiałyby być ujemne. Uważamy, że jest to mniej intuicyjne, chociaż nie ma istotnej różnicy między dwoma systemami kodowania. Na koniec, przed uruchomieniem naszej analizy regresji, musimy zainicjować losowe ziarno i załadować pakiet glmnet:
set.seed (1)
library („glmnet”)
Po zakończeniu prac konfiguracyjnych możemy zapętlić kilka możliwych wartości dla Lambda, aby zobaczyć, które dają najlepsze wyniki w przetrzymywanych danych. Ponieważ nie mamy dużo danych, dokonujemy tego podziału 50 razy dla każdej wartości Lambda, aby uzyskać lepsze poczucie dokładności, którą uzyskujemy z różnych poziomów regularyzacji. W poniższym kodzie ustawiliśmy wartość dla Lambda, podzieliliśmy dane na zestaw szkoleniowy i zestaw testowy 50 razy, a następnie oceniliśmy wydajność naszego modelu przy każdym podziale
performance <- data.frame()
for (lambda in c(0.1, 0.25, 0.5, 1, 2, 5))
{
for (i in 1:50)
{
indices <- sample(1:100, 80)
training.x <- x[indices, ]
training.y <- y[indices]
test.x <- x[-indices, ]
test.y <- y[-indices]
glm.fit <- glmnet(training.x, training.y)
predicted.y <- predict(glm.fit, test.x, s = lambda)
rmse <- sqrt(mean((predicted.y – test.y) ^ 2))
performance <- rbind(performance,
data.frame(Lambda = lambda,
Iteration = i,
RMSE = rmse))
}
}
Po obliczeniu wydajności modelu dla tych różnych wartości Lambda, możemy je porównać, aby zobaczyć, gdzie model najlepiej sobie radzi:
ggplot(performance, aes(x = Lambda, y = RMSE)) +
stat_summary(fun.data = ‘mean_cl_boot’, geom = ‘errorbar’) +
stat_summary(fun.data = ‘mean_cl_boot’, geom = ‘point’)
Niestety, spojrzenie na rysunek sugeruje, że jest to nasz pierwszy przykład nieudanej próby zastosowania metody statystycznej do danych.
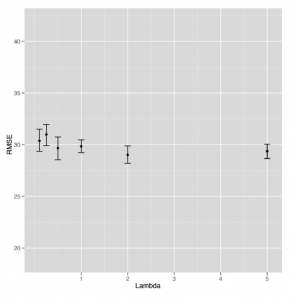
Oczywiste jest, że model staje się coraz lepszy wraz z wyższymi wartościami Lambda, ale dzieje się to dokładnie wtedy, gdy model ogranicza się do niczego więcej niż przechwytywanie. W tym momencie nie używamy żadnych danych tekstowych. Krótko mówiąc, tutaj nie ma sygnału, że można znaleźć naszą regresję tekstu. Wszystko, co widzimy, okazuje się być hałasem, gdy testujesz model pod kątem wstrzymanych danych. Chociaż oznacza to, że nie mamy lepszego pomysłu na to, jak napisać opis tylnej okładki książki, aby upewnić się, że dobrze się sprzedaje, jest to cenna lekcja dla każdego, kto pracuje nad uczeniem maszynowym do przyswojenia: czasami po prostu nie ma sygnału w danych, z którymi pracujesz.