Czy słyszałeś o teorii 10 000 godzin? W swojej książce „Outliers” Malcolm Gladwell sugeruje, że ćwiczenie dowolnej umiejętności przez 10 000 godzin wystarczy, aby stać się ekspertem. Ta „ekspercka” wiedza znajduje odzwierciedlenie w połączeniach, jakie twój ludzki mózg rozwija pomiędzy neuronami. Model sztucznej inteligencji faktycznie robi coś podobnego. Aby stworzyć dobrze działający model, należy go wytrenować przy użyciu określonego zestawu zmiennych, zwanych parametrami. Proces ustalania ideału 1 parametr modelu nazywa się szkoleniem. Model asymiluje wartości parametrów w kolejnych iteracjach szkoleniowych. Znalezienie idealnych parametrów w modelu głębokiego uczenia się zajmuje dużo czasu. Szkolenie to długotrwały proces, który w zależności od zadania może trwać od kilku godzin do kilku miesięcy i wymaga ogromnej mocy obliczeniowej. Bardzo pomocna byłaby możliwość ponownego wykorzystania części tego długiego procesu uczenia się do innych zadań. I tu właśnie pojawiają się wstępnie przeszkolone modele. Wstępnie wyszkolony model, zgodny z teorią 10 000 godzin Gladwella, to pierwsza umiejętność, którą rozwijasz, która może pomóc ci szybciej zdobyć kolejną. Na przykład opanowanie umiejętności rozwiązywania problemów matematycznych może pomóc w szybszym nabyciu umiejętności rozwiązywania problemów inżynierskich. Wstępnie wytrenowany model jest szkolony (przez Ciebie lub kogoś innego) do bardziej ogólnego zadania, a następnie jest dostępny w celu dostrojenia go do różnych zadań. Zamiast budować model od zera w celu rozwiązania problemu, jako punkt wyjścia wykorzystujesz model przeszkolony w oparciu o bardziej ogólny problem i przeprowadzasz bardziej szczegółowe szkolenie w wybranym przez Ciebie obszarze, korzystając ze specjalnie dobranego zestawu danych. Wstępnie wytrenowany model może nie być w 100% dokładny, ale pozwala uniknąć konieczności wymyślania koła na nowo, oszczędzając w ten sposób czas i poprawiając wydajność. W uczeniu maszynowym model jest szkolony na zestawie danych. Rozmiar i typ próbek danych różnią się w zależności od zadania, które chcesz rozwiązać. GPT-3 jest wstępnie nauczony na korpusie tekstu z pięciu zestawów danych: Common Crawl, WebText2, Books1, Books2 i Wikipedia.
Common Crawl
Korpus Common Crawl (zbiór tekstów) obejmuje petabajty danych, w tym surowe dane stron internetowych, metadane i dane tekstowe zebrane w ciągu ośmiu lat przeszukiwania sieci. Badacze OpenAI korzystają z wyselekcjonowanej, przefiltrowanej wersji tego zbioru danych.
WebText2
WebText2 to rozszerzona wersja zbioru danych WebText, który jest wewnętrznym korpusem OpenAI tworzonym poprzez skrobanie stron internetowych o szczególnie wysokiej jakości. Aby sprawdzić jakość, autorzy usunęli z Reddita wszystkie linki wychodzące, które otrzymały co najmniej trzy punkty karmy (wskaźnik tego, czy inni użytkownicy uznali link za interesujący, edukacyjny czy po prostu zabawny). WebText2 zawiera 40 gigabajtów tekstu z tych 45 milionów linków, co stanowi ponad 8 milionów dokumentów.
Books1 i Books 2
Books1 i Books2 to dwa korpusy (liczba mnoga korpusu), które zawierają tekst dziesiątek tysięcy książek o różnej tematyce.
Wikipedia
Korpus Wikipedii to zbiór obejmujący wszystkie anglojęzyczne artykuły z internetowej encyklopedii Wikipedia pochodzącej z crowdsourcingu w momencie finalizowania zbioru danych GPT-3 w 2019 r. Ten zbiór danych zawiera około 5,8 miliona artykułów w języku angielskim.
Korpus ten zawiera w sumie prawie bilion słów. GPT-3 jest w stanie generować i skutecznie pracować również z językami innymi niż angielski. Tabela przedstawia 10 najpopularniejszych języków w zbiorze danych.
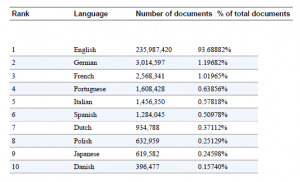
Choć przepaść między angielskim a innymi językami jest dramatyczna, na pierwszym miejscu znajduje się angielski, obejmujący 93% zbioru danych; Język niemiecki, na drugim miejscu, stanowi zaledwie 1% — ten 1% wystarczy do stworzenia doskonałego tekstu w języku niemieckim, z przeniesieniem stylu i innymi zadaniami. To samo dotyczy innych języków na liście. Ponieważ GPT-3 jest wstępnie przeszkolony na obszernym i zróżnicowanym zbiorze tekstów, może z powodzeniem wykonywać zaskakującą liczbę zadań NLP bez podawania przez użytkowników żadnych dodatkowych przykładowych danych.