Chcielibyśmy, aby reprezentacja słów nie wymagała ręcznej inżynierii cech, ale pozwala na uogólnianie między powiązanymi słowami — słowami, które są powiązane syntaktycznie („bezbarwny” i „idealny” są przymiotnikami), semantycznie („kot” i „kotek” są kotami), lokalnie („słonecznie” i „ze śniegiem” to terminy pogodowe), pod względem sentymentu („niesamowity” ma przeciwny sentyment do „wartego do bólu”) lub w inny sposób. Jak zakodować słowo do wektora wejściowego x do wykorzystania w sieci neuronowej? Jak wyjaśniono , możemy użyć jednego gorącego wektora — to znaczy, kodujemy i-te słowo w słowniku z 1 bitem na i-tej pozycji wejściowej i 0 na wszystkich pozostałych pozycjach. Ale taka reprezentacja nie uchwyciłaby podobieństwa między słowami. Podążając za maksymą lingwisty Johna R. Firtha (1957) „Poznasz słowo po frmie, w której się znajduje”, możemy przedstawić każde słowo za pomocą wektora liczby n-gramów wszystkich fraz, w których to słowo się pojawia. surowe liczby n-gramów są kłopotliwe. Przy słownictwie składającym się ze 100 000 słów jest 1025 5 gramów do śledzenia (chociaż wektory w tej 1025-wymiarowej przestrzeni byłyby dość rzadkie — większość zliczeń wynosiłaby zero). Lepsze uogólnienie uzyskalibyśmy, gdybyśmy zredukowali to do wektora o mniejszym rozmiarze, być może o zaledwie kilkuset wymiarach . Ten mniejszy, gęsty wektor nazywamy osadzaniem słowa: niskowymiarowym wektorem reprezentującym słowo. Osadzania słów są uczone automatycznie z danych. (Później zobaczymy, jak to się robi.) Jakie są te wyuczone osadzania słów? Z jednej strony każda z nich jest tylko wektorem liczb, gdzie poszczególne wymiary i ich wartości liczbowe nie mają dostrzegalnego znaczenia:
Z drugiej strony przestrzeń cech ma tę właściwość, że podobne słowa mają podobne wektory. Widzimy to na rysunku

, gdzie istnieją oddzielne klastry dla słów kraj, pokrewieństwo, transport i jedzenie. Okazuje się, z powodów, których do końca nie rozumiemy, że wektory osadzające słowo mają dodatkowe właściwości poza samą bliskością podobnych słów. Załóżmy na przykład, że patrzymy na wektory A dla Aten i B dla Grecji. W przypadku tych słów różnica wektorowa B-A wydaje się kodować relację kraj/stolica. Inne pary — Francja i Paryż, Rosja i Moskwa, Zambia i Lusaka – mają zasadniczo tę samą różnicę wektorów. Możemy użyć tej własności do rozwiązywania problemów z analogią słów, takich jak „Ateny są dla Grecji, tak jak Oslo dla [czego]?” Pisząc C dla wektora Oslo i D dla niewiadomego, zakładamy, że B-A=D-C, co daje nam D=C+(B-A). A kiedy obliczamy ten nowy wektor D, okazuje się, że jest on bliższy „Norwegii” niż jakiemukolwiek innemu słowu. Nie ma jednak gwarancji, że określony algorytm osadzania słów uruchomiony w określonym korpusie uchwyci określoną relację semantyczną. Osadzanie słów jest popularne, ponieważ okazało się, że jest dobrą reprezentacją zadań językowych (takich jak odpowiadanie na pytania, tłumaczenie lub podsumowywanie), a nie dlatego, że gwarantuje, że same odpowiedzą na pytania dotyczące analogii. Używanie wektorów do osadzania słów zamiast kodowania słów w jednym miejscu okazuje się być pomocne w zasadzie we wszystkich zastosowaniach uczenia głębokiego do zadań NLP. Rzeczywiście, w wielu przypadkach możliwe jest użycie generycznych, wstępnie przeszkolonych wektorów, uzyskanych od dowolnego z kilku dostawców, do konkretnego zadania NLP. W chwili pisania tego tekstu powszechnie używane słowniki wektorowe obejmują WORD2VEC, GloVe (Global Vectors) i FASTTEXT, który ma osadzania dla 157 języków. Korzystanie z wstępnie wytrenowanego modelu może zaoszczędzić wiele czasu i wysiłku. Możliwe jest również trenowanie własnych wektorów słów; odbywa się to zwykle w tym samym czasie, co szkolenie sieci do określonego zadania. W przeciwieństwie do ogólnych, wstępnie wytrenowanych osadzeń, osadzania słów tworzone dla określonego zadania mogą być wytrenowane na starannie dobranym korpusie i będą miały tendencję do podkreślania aspektów słów, które są przydatne w zadaniu. Załóżmy na przykład, że zadanie polega na znakowaniu części mowy (POS) . Przypomnij sobie, że obejmuje to przewidywanie prawidłowej części mowy dla każdego słowa w zdaniu. Chociaż jest to proste zadanie, nie jest trywialne, ponieważ wiele słów można oznaczyć na wiele sposobów – na przykład słowo cut może być czasownikiem czasu teraźniejszego (przechodniego lub nieprzechodniego), czasownikiem czasu przeszłego, czasownikiem bezokolicznikowym, imiesłów czasu przeszłego, przymiotnik lub rzeczownik. Jeśli pobliski przysłówek czasowy odnosi się do przeszłości, sugeruje to, że to konkretne wystąpienie cut jest czasownikiem czasu przeszłego; a zatem możemy mieć nadzieję, że osadzenie uchwyci aspekt przysłówków odnoszący się do przeszłości. Tagowanie POS służy jako dobre wprowadzenie do zastosowania uczenia głębokiego w NLP, bez komplikacji bardziej złożonych zadań, takich jak odpowiadanie na pytania (patrz Rozdział 25.5.3). Mając korpus zdań ze znacznikami POS, jednocześnie uczymy się parametrów osadzenia słów i tagu POS. Proces przebiega w następujący sposób:
- Wybierz szerokość w (nieparzystą liczbę słów) okna przewidywania, które będzie używane do oznaczania każdego słowa. Typowa wartość to w=5, co oznacza, że znacznik jest przewidywany na podstawie słowa plus dwa słowa po lewej i dwa słowa po prawej. Podziel każde zdanie w swoim korpusie na zachodzące na siebie okna o długości w. Każde okno generuje jeden przykład uczący składający się ze słów w jako danych wejściowych i kategorii POS środkowego słowa jako danych wyjściowych.
- Utwórz słownik wszystkich unikalnych tokenów słów, które występują w danych treningowych więcej niż, powiedzmy, 5 razy. Oznacz całkowitą liczbę słów w słowniku jako v.
- Posortuj to słownictwo w dowolnej kolejności (być może alfabetycznie).
- Wybierz wartość d jako rozmiar każdego wektora osadzającego słowo.
- Utwórz nową macierz wag v-by-d o nazwie E. To jest macierz osadzania słów. Wiersz i z E to słowo zawierające i-te słowo w słowniku. Zainicjuj E losowo (lub ze wstępnie wytrenowanych wektorów).
- Skonfiguruj sieć neuronową, która wysyła część etykiety mowy. Pierwsza warstwa będzie się składać z w kopii matrycy osadzania. Możemy użyć dwóch dodatkowych ukrytych warstw, z1 i z2 (z macierzami wag odpowiednio W1 i W2), a następnie warstwy softmax dającej rozkład prawdopodobieństwa wyjścia ˆy nad możliwymi kategoriami części mowy dla środkowego słowa:
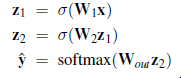
- Aby zakodować sekwencję słów w w wektorze wejściowym, po prostu wyszukaj osadzenie dla każdego słowa i połącz wektory osadzenia. Wynikiem jest wektor wejściowy x o wartościach rzeczywistych o długości wd. Nawet jeśli dane słowo będzie miało to samo osadzenie
wektor niezależnie od tego, czy występuje w pierwszej pozycji, ostatniej, czy gdzieś pomiędzy, każde osadzenie zostanie pomnożone przez inną część pierwszej ukrytej warstwy; dlatego domyślnie kodujemy względną pozycję każdego słowa.
- Ćwicz wagi E i inne macierze wag W1, W2 i Wout, korzystając ze zniżania gradientowego. Jeśli wszystko pójdzie dobrze, środkowe słowo, cut, zostanie oznaczone jako czasownik czasu przeszłego, w oparciu o dowody w oknie, które obejmuje czasowe przeszłe słowo „wczoraj”, zaimek podmiotowy trzeciej osoby „oni” bezpośrednio przed cięcie i tak dalej.
Alternatywą dla osadzania słów jest model na poziomie znaków, w którym dane wejściowe są sekwencją znaków, z których każdy jest zakodowany jako jeden gorący wektor. Taki model musi nauczyć się, jak postacie łączą się w słowa. Większość prac w NLP opiera się na kodowaniu na poziomie słowa, a nie na poziomie znaków.