https://aie24.pl/
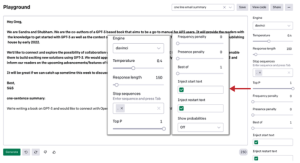
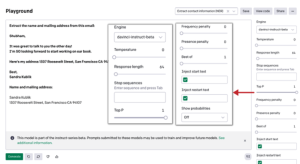
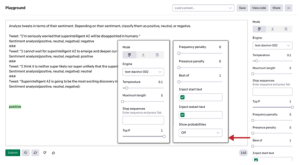
Podsumowanie tekstu to technika generowania zwięzłego i dokładnego podsumowania długich tekstów, skupiając się na sekcjach zawierających przydatne informacje, bez utraty ogólnego znaczenia. Podsumowanie tekstu w oparciu o GPT-3 ma na celu przekształcenie długich fragmentów tekstów tl;dr w ich skrócone wersje. Zadania takie są na ogół trudne i kosztowne do wykonania ręcznie. W przypadku GPT-3 jest to kwestia jednego wprowadzenia i kilku sekund! Modele NLP można wytrenować w zakresie rozumienia dokumentów i identyfikowania sekcji, które przekazują ważne fakty i informacje przed utworzeniem podsumowania tekstów. Jednak takie modele wymagają dużej liczby próbek szkoleniowych, zanim będą mogły poznać kontekst i zacząć podsumowywać niewidoczne dane wejściowe. Abstrakcyjne podsumowanie GPT-3 jest kluczem do rozwiązania problemu ekstrakcji informacji. Tworząc streszczenia, zamiast jedynie wyodrębniać kluczowe informacje, GPT-3 może zapewnić bardziej wszechstronne i dokładne zrozumienie tekstu. Wykorzystuje podejście zerowe lub kilka strzałów do podsumowania tekstu, dzięki czemu jest przydatne w różnych przypadkach użycia. Dzięki GPT-3 istnieje wiele sposobów podsumowania tekstu w zależności od przypadku użycia: streszczenia podstawowe, streszczenia jednowierszowe lub streszczenia na poziomie klasy. Przeanalizujmy szybko te podejścia. W większości przypadków model jest w stanie wygenerować przyzwoite wyniki w formie podsumowania przeglądu, ale czasami może generować nieistotne wyniki w zależności od wcześniejszego kontekstu. Aby uniknąć problemu uzyskania niepożądanych wyników, możesz ustawić parametr „best of” na 3, co zawsze da Ci najlepszy z trzech wyników wygenerowanych przez API. W przykładzie pokazanym na rysunku po kilku próbach i niewielkich zmianach parametrów uzyskaliśmy przyzwoite wyniki.
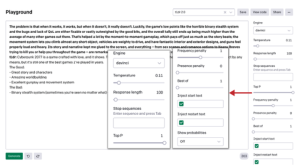
Oto nasz monit:
Problem w tym, że jak coś działa, to działa, a kiedy nie,
to naprawdę
nie. Na szczęście słabe punkty gry, takie jak okropny plik binarny
system ukryty
a błędy i brak QoL można naprawić lub można je naprawić w znacznym stopniu
przeważone przez dobro
bitów, a ogólny wynik nadal jest znacznie wyższy niż
średnia z
wiele innych gier. To bardzo pomogło w tej chwili
rozgrywka,
co opłaca się tak samo, jak historia bije na głowę; ruch
system Ci na to pozwala
wspiąć się na prawie każdy krótki obiekt, pojazdy są ciężkie w prowadzeniu i
mieć fantastyczne
projekty wewnętrzne i zewnętrzne, a broń wydaje się odpowiednio głośna i
ciężki. Jego historia
i narracja trzymały mnie przyklejonego do ekranu i wszystkiego – od
sceny seksu
i opcje romansu z Keanu Reevesem, który próbuje cię zabić lub pomóc
na wskroś
gra – są wyjątkowo dobrze zrobione. Cyberpunk 2077 to gra
stworzone z miłością,
i to pokazuje.
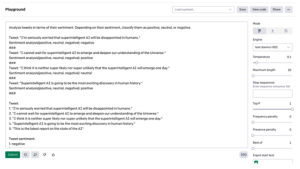
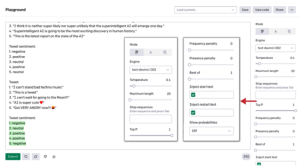
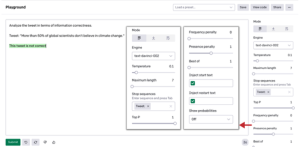
tl;dr:
I wynik:
Cyberpunk 2077 to gra stworzona z miłością i to widać. The
historia jest świetna,
rozgrywka jest świetna, budowanie świata jest świetne. To nie jest
pod każdym względem doskonały,
ale i tak jest to jedna z najlepszych gier, w jakie grałem od lat.
Dobre:
– Świetna historia i bohaterowie
– Niesamowite budowanie świata
– Doskonały system strzelania i ruchu
Złe:
– Binarny system ukrywania się (czasami jesteś widziany bez względu na wszystko) –