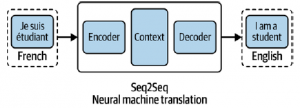
Naukowcy z Google i Uniwersytetu w Toronto przedstawili ideę modelu transformatora w artykule z 2017 roku: Proponujemy nową, prostą architekturę sieci, Transformer, opartą wyłącznie na mechanizmach uwagi, całkowicie rezygnując z powtarzalności i splotów. Eksperymenty przeprowadzone na dwóch zadaniach tłumaczenia maszynowego wykazały, że modele te mają lepszą jakość, a jednocześnie są bardziej zrównoleglone i wymagają znacznie mniej czasu na szkolenie. Podstawą modeli transformatorów jest architektura sekwencyjna. Sekwencja do sekwencji (Seq2Seq) przekształca daną sekwencję elementów, np. słów w zdaniu, w inną sekwencję, np. zdanie w innym języku; zdania są zależne od sekwencji, ponieważ kolejność słów ma kluczowe znaczenie dla zrozumienia zdania. Modele Seq2Seq są szczególnie dobre w tłumaczeniu, gdzie sekwencja słów z jednego języka jest przekształcana na sekwencję różnych słów w innym języku. Tłumacz Google zaczął używać w produkcji modelu opartego na Seq2Seq pod koniec 2016 r. Modele Seq2Seq składają się z dwóch części: kodera i dekodera. Wyobraź sobie osobę kodującą i dekoderującą jako tłumaczy, z których każdy zna tylko dwa języki, a każdy ma inny język ojczysty. W naszym przykładzie 2 powiemy, że koder jest rodzimym użytkownikiem języka francuskiego, a dekoder jest rodzimym użytkownikiem języka angielskiego. Obydwa mają wspólny drugi język: powiedzmy, że jest to koreański. Aby przetłumaczyć język francuski na angielski, koder konwertuje zdanie francuskie na język koreański (tzw. kontekst) i przekazuje kontekst do dekodera. Ponieważ dekoder rozumie język koreański, może teraz tłumaczyć z koreańskiego na angielski. Pracując razem, potrafią przetłumaczyć język francuski na angielski, jak pokazano na rysunku