https://aie24.pl/
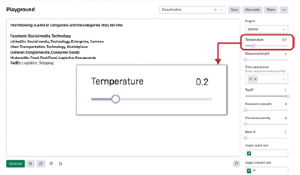
Pokrętło temperatury steruje kreatywnością odpowiedzi, reprezentowaną jako zakres od 0 do 1. Niższa wartość temperatury oznacza, że interfejs API przewidzi pierwszą rzecz, którą zobaczy model, co da najbardziej poprawny, ale być może nudny tekst, z mała odmiana. Z drugiej strony wyższa wartość temperatury oznacza, że model przed przewidywaniem wyniku ocenia możliwe reakcje, które mogłyby pasować do kontekstu. Wygenerowany tekst będzie bardziej zróżnicowany, ale istnieje większe ryzyko błędów gramatycznych i generowania nonsensów. Górne P kontroluje, ile losowych wyników model powinien uwzględnić w celu uzupełnienia, zgodnie z sugestią pokrętła temperatury; określa zakres losowości. Zakres górnego P wynosi od 0 do 1. Wartość bliska zeru oznacza, że losowe odpowiedzi zostaną ograniczone do pewnego ułamka: na przykład, jeśli wartość wynosi 0,1, wówczas tylko 10% losowych odpowiedzi zostanie uznanych za ukończone. To sprawia, że silnik jest deterministyczny, co oznacza, że zawsze będzie generował takie same dane wyjściowe dla danego tekstu wejściowego. Jeśli wartość jest ustawiona na 1, API rozważy wszystkie odpowiedzi pod kątem ukończenia, podejmując ryzyko i wymyślając kreatywne odpowiedzi. Niższa wartość ogranicza kreatywność; wyższa wartość poszerza horyzonty. Temperatura i górny P mają znaczący wpływ na moc wyjściową. Czasami może być mylące, zastanawianie się, kiedy i jak z nich korzystać, aby uzyskać pożądany efekt. Obydwa są ze sobą powiązane: zmiana wartości jednego będzie miała wpływ na drugą. Zatem ustawiając Top P na 1, możesz pozwolić modelowi uwolnić swoją kreatywność, badając całe spektrum reakcji i kontrolować losowość za pomocą pokrętła temperatury.
WSKAZÓWKA: Zawsze zalecamy zmianę górnego P lub temperatury i pozostawienie pokrętła drugiego ustawienia na 1.
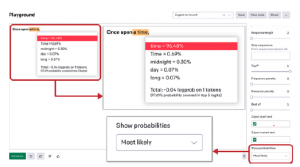
Duże modele językowe opierają się raczej na podejściach probabilistycznych niż na metodach probabilistycznych konwencjonalnej logiki. Mogą generować różne odpowiedzi dla tych samych danych wejściowych, w zależności od tego, jak ustawisz parametry modelu. Model stara się znaleźć najlepsze dopasowanie probabilistyczne w obrębie zbioru danych, na którym został wyszkolony, zamiast szukać za każdym razem idealnego rozwiązania. Jak wspomnieliśmy w Rozdziale 1, wszechświat danych szkoleniowych GPT-3 jest ogromny i składa się z różnych publicznie dostępnych książek, forów internetowych i artykułów z Wikipedii specjalnie wybranych przez OpenAI, co pozwala na generowanie szerokiej gamy uzupełnień dla danego podpowiedzi . Tutaj właśnie wkraczają temperatura i Top P, czasami nazywane „tarczami kreatywności”. Można je dostroić, aby generować bardziej naturalne lub abstrakcyjne reakcje z elementem zabawnej kreatywności. Załóżmy, że będziesz używać GPT-3 do generowania nazw dla swojego start-upu. Możesz ustawić pokrętło temperatury na wyższy poziom, aby uzyskać najbardziej kreatywną reakcję. Kiedy całymi dniami i nocami szukaliśmy idealnej nazwy dla naszego start-upu, podkręcaliśmy temperaturę. GPT-3 przyszedł na ratunek i pomógł nam stworzyć nazwę, którą kochamy: Kairos Data Labs. W innych przypadkach Twoje zadanie może wymagać niewielkiej lub żadnej kreatywności: na przykład zadania klasyfikacji i odpowiadania na pytania. W tym celu należy utrzymywać niższą temperaturę. Spójrzmy na rysunek z prostym przykładem klasyfikacji, który dzieli firmy na ogólne segmenty lub kategorie na podstawie ich nazw.
Nasz monit:
Poniżej znajduje się lista firm i kategorii, do których się zaliczają:
Facebook: Social Media, Technology
LinkedIn: Social Media, Technology, Enterprise, Careers
Uber: Transportation, Technology, Marketplace
Unilever: Conglomerate, Consumer Goods
Mcdonalds: Food, Fast Food, Logistics, Restaurants
FedEx:
I wynik:
Logistics, Shipping
Jak widać na rysunku, ponownie użyliśmy temperatury do kontrolowania stopnia losowości. Można to również zrobić, zmieniając Top P, utrzymując pokrętło temperatury ustawione na 1.