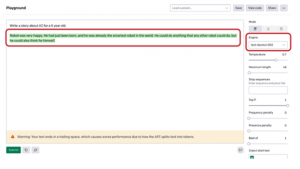
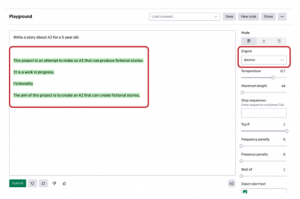
W oparciu o cztery podstawowe modele OpenAI uruchomiło serię modeli InstructGPT, które lepiej rozumieją instrukcje ipodążając za nimi, będąc jednocześnie mniej toksycznym i bardziej zgodnym z prawdą niż oryginalny GPT-3. Zostały one opracowane przy użyciu technik pochodzących z badań OpenAI dotyczących wyrównania. Modele te są szkolone z udziałem ludzi i są teraz wdrażane jako domyślne modele językowe w interfejsie API OpenAI. Rysunki przedstawiają dwa wyniki generowane przez silniki Davinci serii InstructGPT i GPT dla tego samego sygnału wejściowego.
Nasz wkład:
Napisz opowiadanie o sztucznej inteligencji dla 5-latka.
Dane wyjściowe instrukcji GPT:
Robot był bardzo szczęśliwy. Dopiero co się urodził, a już był
najmądrzejszy
robota na świecie. Mógł zrobić wszystko, co każdy inny robot
mógłby zrobić, ale on
mógł też samodzielnie pomyśleć.
Dane wyjściowe GPT:
Ten projekt jest próbą stworzenia sztucznej inteligencji, która może produkować
fikcyjne historie.
Jest to praca w toku.
Fikcyjność
Celem tego projektu jest stworzenie sztucznej inteligencji, która potrafi tworzyć fikcyjne historie.
Aby proces tworzenia podpowiedzi był naprawdę wydajny, OpenAI zdecydowało się udostępnić publicznie wersje InstructGPT czterech modeli: tekst-davinci-001, tekst-curie-001, tekst-babbage-001 i tekst-ada-001. Dzięki jasnym instrukcjom modele te mogą dawać lepsze wyniki niż ich podstawowe odpowiedniki i są teraz domyślnymi modelami interfejsu API. Ta seria to ważny krok w zasypywaniu luki między sposobem myślenia ludzi a sposobem działania modeli.
WSKAZÓWKA
Zalecamy używanie tej serii modeli jako domyślnej do wszystkich zadań związanych z tekstem. Podstawowe wersje modeli GPT-3 są dostępne jako Davinci, Curie, Babbage i Ada i są przeznaczone do stosowania z punktami końcowymi dostrajania, wyszukiwania, klasyfikacji i odpowiedzi.