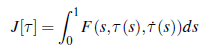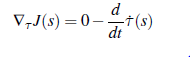Sztuczną inteligencję można uznać za rewolucyjną technologię, a jej integracja z dużą liczbą aplikacji jest jednym z głównych czynników napędzających wzrost rynku. Oczekuje się, że na całym świecie branże skoncentrowane na człowieku, takie jak usługi finansowe i handel detaliczny, będą największymi inwestorami we wdrażanie sztucznej inteligencji, a następnie przemysł wytwórczy, energetyczny i użyteczności publicznej, transportowy itp. (wykres 19.4). W biznesie, wydajności, poprawie obsługi klienta i zadowoleniu konsumentów, cyberbezpieczeństwie, analityce, sztuczna inteligencja szybko się rozwija. Będzie to miało większy wpływ, ponieważ oczekuje się, że 40% nowych zastosowań przemysłowych wyda do 2021 r. 45 miliardów USD, uwzględniając technologie inteligentnych maszyn . Rosnące inwestycje wiodących branż w badania i rozwój będą odgrywać kluczową rolę w ulepszonych zastosowaniach technologii sztucznej inteligencji, które obejmują tagowanie, grupowanie, kategoryzację, generowanie hipotez, alarmowanie, filtrowanie, nawigację i wizualizację. Zwiększone wykorzystanie platform opartych na chmurze i sprzętu do bezpiecznego przechowywania ogromnych ilości danych dało wskazówkę dla rozwoju platformy analitycznej (Armstrong, 2016). Firma konsultingowa Zinnov oszacowała, że światowe firmy wydały ponad 470 miliardów dolarów na media cyfrowe w 2017 roku, podczas gdy wydatki cyfrowe prawdopodobnie wzrosną o ponad 20%, osiągając 1,1-1,2 biliona dolarów do 2022 roku . Głównymi czynnikami rozwoju rynku sztucznej inteligencji są dostępność big data, aplikacji i usług w chmurze oraz inteligentnych asystentów wirtualnych. Nowe premiery dużych firm, takich jak NVDIA (USA), Intel (USA), Xilinx (USA), Samsung (Korea Południowa), Micron (USA), IBM (USA), Google (USA), Microsoft Corporation (USA) i Amazon Web Services (USA) pomoże w rozwoju rynku AI w nadchodzących latach . Wiele krajów korzysta z okazji rewolucji AI, aby promować krajowy rozwój gospodarczy i technologiczny. Technologia AI może być wykorzystana do zwiększenia produktywności biznesowej nawet o 40%. Ameryka Północna miała największy udział w światowym rynku w 2019 r., jednak przewiduje się, że region Azji i Pacyfiku zastąpi Amerykę Północną i stanie się wiodącym rynkiem regionalnym do 2025 r. Może to wynikać z różnych przyczyn, takich jak ogromne postępy w pojemności pamięci masowej, dużej mocy obliczeniowej i przetwarzaniu równoległym. Roboty przemysłowe generują duże ilości danych, które można wykorzystać do szkolenia tych robotów. Kraje takie jak Japonia, Chiny i Korea Południowa są uważane za największy rynek dla robotów przemysłowych. Rysunek 19.6 pokazuje, że ocena potencjału wzrostu rynku w robotyce; robo-doradcy, następnie pojazdy samojezdne, roboty analityczne, logistyczne i przemysłowe. Według Grand View Research, Inc. roboty oparte na sztucznej inteligencji automatycznie identyfikują obszar do czyszczenia i rozróżniają brud od innych obiektów. Rozwój rynku robotów sprzątających wynika z automatyzacji technologii i wyższych kosztów pracy ręcznej przy czyszczeniu dużych powierzchni. ML i DL przyciągną znaczne inwestycje w sztuczną inteligencję. Zgodnie z raportem Grand View Research, Inc. (2020a), globalny rynek sztucznej inteligencji ma osiągnąć wartość 390,9 mld USD do 2025 r. i 733,7 mld USD do 2027 r., a następnie wzrosnąć o CAGR na poziomie 46,2% w latach 2019-2027. Cele wielu firm znacznie wykraczają poza ich konkretne zastosowanie sztucznej inteligencji, które może stać się potencjalnym źródłem inwestycji i generować wsparcie dla technologii sztucznej inteligencji w przyszłości. Liczba start-upów AI na całym świecie od 2000 roku wzrosła 14-krotnie. Oczekuje się, że aktywa AI będą zyskiwać na wartości (fundusze) w miarę upływu czasu, więc nowe wskaźniki finansowe będą oceniać „Zwrot z AI”, który może obejmować fundusze generowane z algorytmu AI. Loucks i inni stwierdzili, że 82% branż z powodzeniem uzyskało dobry zwrot z inwestycji w sztuczną inteligencję. We wszystkich branżach mediana zwrotu z inwestycji w technologie kognitywne wyniosła około 17%. Niektóre branże są bardziej doświadczone niż inne w przekształcaniu inwestycji w korzyści finansowe. Dane liczbowe dotyczące zwrotu z inwestycji pokazują, że branże czerpią korzyści z technologii kognitywnych. Są też siłą napędową dla firm, takich jak Google, Microsoft czy Facebook, do rozwoju rynku i doskonalenia usług. Na przykład Netflix, korzystając ze sztucznej inteligencji, odkrył, że klienci uzyskują lepsze wyniki wyszukiwania filmu w kilka sekund, co wcześniej zajmowało ponad 90 sekund, a tym samym traciło zainteresowanie klientów wyszukiwaniem. Przyniosło Netflixowi 1 miliard dolarów rocznie więcej w porównaniu z korzystaniem bez sztucznej inteligencji.
Postępy w rozpoznawaniu obrazu i głosu to inne ważne obszary, które napędzają wzrost rynku. Ulepszona technologia rozpoznawania obrazu ma kluczowe znaczenie w inteligentnych dronach, samojezdnych samochodach i robotyce . Oczekuje się, że połączenie aplikacji AI związanych z obrazem/wizją będzie stanowić 30% całego rynku AI do 2025 r., zgodnie z ostatnim badaniem Tractica . Pod względem uzyskanych przychodów ranking wykorzystania sztucznej inteligencji był wyższy w przypadku wykrywania pojazdów, maszyn i obiektów; statyczne rozpoznawanie obrazu; i przetwarzania danych pacjentów. Przewiduje się, że przy oczekiwanych skumulowanych przychodach w wysokości ponad 8 mld USD „rozpoznawanie statycznych obrazów, klasyfikacja i tagowanie” będzie liderem, a następnie „poprawa wydajności strategii handlu algorytmicznego” (7,5 mld USD) oraz „wydajne, skalowalne przetwarzanie danych pacjentów” ( 7,4 miliarda USD. Ponieważ przetwarzanie i analiza obrazu stają się ważnym zastosowaniem sztucznej inteligencji w różnych branżach, oczekuje się ogromnego wzrostu. Największy wzrost odnotuje region Azji i Pacyfiku. Rynek rozpoznawania obrazów AI oferujący usługi i Solutions jest wysoce konkurencyjny na rynku krajowym i międzynarodowym. Główne branże działające na tych rynkach stale rozwijają swoje produkty na podstawie opinii klientów, co zapewnia im trwałą przewagę konkurencyjną. Firmy wydają łącznie prawie 20 miliardów USD na produkty AI i usług rocznie, duzi gracze, tacy jak Google, Apple, Microsoft i Amazon, inwestują ogromne kwoty w rozwój tej technologii produktów i usług, a uniwersytety włączają sztuczną inteligencję jako ważny przedmiot do swoich programów nauczania (np. sam MIT zapewnia 1 miliard dolarów na nową uczelnię zajmującą się wyłącznie informatyką z naciskiem na sztuczną inteligencję), popyt na sztuczną inteligencję będzie wzrastał wielorako. Im bardziej obiektywna jest praca, taka jak segregowanie rzeczy do koszy, mycie naczyń, zbieranie owoców i odpowiadanie na telefony obsługi klienta itp., Tym bardziej wymagająca będzie technologia sztucznej inteligencji, ponieważ istnieje wiele zadań, które są powtarzalne i rutynowe. W ciągu najbliższych 5-15 lat takie powtarzalne i rutynowe prace zostaną zastąpione przez zastosowanie sztucznej inteligencji. Na przykład Amazon, magazyny zakupów online wdrożyły ponad 100 000 pracujących robotów, ale prace związane z kompletacją i pakowaniem są nadal wykonywane przez ludzi, co ma się zmienić z czasem