https://aie24.pl/
W robotyce niepewność wynika z częściowej obserwowalności otoczenia oraz ze stochastycznych (lub niemodelowanych) skutków działań robota. Błędy mogą również wynikać ze stosowania algorytmów aproksymacyjnych, takich jak filtrowanie cząstek, które nie dają robotowi dokładnego stanu przekonania, nawet jeśli środowisko jest idealnie modelowane. Większość dzisiejszych robotów wykorzystuje do podejmowania decyzji algorytmy deterministyczne, takie jak algorytmy planowania ścieżki z poprzedniej sekcji lub algorytmy wyszukiwania, które zostały wprowadzone w rozdziale 3. Te deterministyczne algorytmy są adaptowane na dwa sposoby: po pierwsze, zajmują się ciągła przestrzeń stanów poprzez przekształcenie jej w przestrzeń dyskretną (na przykład za pomocą wykresów widoczności lub rozkładu komórek). Po drugie, zajmują się niepewnością w nurcie stan, wybierając najbardziej prawdopodobny stan z rozkładu prawdopodobieństwa wygenerowanego przez algorytm estymacji stanu. Takie podejście przyspiesza obliczenia i czyni lepszym nadające się do deterministycznych algorytmów wyszukiwania. W tej sekcji omówimy metody radzenia sobie z niepewnością, które są analogiczne do bardziej złożonych algorytmów wyszukiwania omówionych w rozdziale 4. Po pierwsze, niepewność wymaga polityki, a nie planów deterministycznych. Omówiliśmy już, w jaki sposób kontrola śledzenia trajektorii zamienia plan w politykę kompensującą błędy w dynamice. Czasami jednak, jeśli najbardziej prawdopodobna hipoteza zmienia się wystarczająco, śledzenie planu zaprojektowanego dla innej hipotezy jest zbyt nieoptymalne. W tym miejscu pojawia się ponowne planowanie online: możemy przeliczyć nowy plan w oparciu o nowe przekonanie. Obecnie wiele robotów wykorzystuje technikę zwaną modelową kontrolą predykcyjną (MPC), w której planują krótsze horyzonty czasowe, ale zmieniają plan w każdym kroku czasowym. (W związku z tym MPC jest ściśle powiązany z algorytmami wyszukiwania w czasie rzeczywistym i grania w gry). To skutecznie skutkuje polityką: na każdym kroku uruchamiamy planer i podejmujemy działania pierwsze działanie w planie; jeśli pojawią się nowe informacje lub skończymy nie tam, gdzie się spodziewaliśmy, to w porządku, ponieważ i tak zamierzamy zmienić plan, a to powie nam, co robić dalej. Po drugie, niepewność wymaga działań w zakresie gromadzenia informacji. Gdy weźmiemy pod uwagę tylko posiadane przez nas informacje i na ich podstawie sporządzamy plan (nazywa się to oddzieleniem estymacji od kontroli), skutecznie rozwiązujemy (w przybliżeniu) nowy MDP na każdym kroku, odpowiadający naszemu obecnemu przekonaniu o tym, gdzie jesteśmy i jak działa świat. Ale w rzeczywistości niepewność lepiej oddaje struktura POMDP: jest coś, czego nie obserwujemy bezpośrednio, czy to lokalizacja robota lub konfiguracja, położenie obiektów na świecie, czy parametry samego modelu dynamiki — na przykład gdzie dokładnie jest środek masy ogniwa drugiego na tym ramieniu? To, co tracimy, gdy nie rozwiązujemy POMDP, to zdolność wnioskowania o przyszłych informacjach, które robot otrzyma: w MDP planujemy tylko z tym, co wiemy, a nie z tym, co możemy ostatecznie wiedzieć. Pamiętasz wartość informacji? Cóż, roboty, które planują wykorzystać swoje obecne przekonania tak, jakby nigdy więcej się nie dowiedziały, nie uwzględniają wartości Informacji. Nigdy nie podejmą działań, które według tego, co wiedzą, wydają się obecnie nieoptymalne, ale w rzeczywistości przyniosą one wiele informacji i pozwolą robotowi dobrze sobie radzić. Jak wygląda taka akcja dla robota nawigacyjnego? Robot może zbliżyć się do punktu orientacyjnego, aby lepiej oszacować, gdzie się znajduje, nawet jeśli ten punkt orientacyjny jest na uboczu zgodnie z tym, co obecnie wie. To działanie jest optymalne tylko wtedy, gdy robot bierze pod uwagę nowe obserwacje, które otrzyma, w przeciwieństwie do patrzenia tylko na informacje, które już posiada. Aby obejść ten problem, techniki robotyki czasami wyraźnie definiują działania związane z gromadzeniem informacji — takie jak poruszanie ręką, aż dotknie powierzchni (tzw. ruchy chronione) — i upewnij się, że robot robi to, zanim wymyśli plan osiągnięcia swojego rzeczywistego celu. Każdy strzeżony ruch składa się z (1) polecenia ruchu i (2) warunku zakończenia, który jest predykatem wartości czujników robota mówiącym, kiedy się zatrzymać. Czasami sam cel można osiągnąć za pomocą sekwencji strzeżonych ruchów, które gwarantują sukces bez względu na niepewność. Jako przykład, Rysunek przedstawia dwuwymiarową przestrzeń konfiguracyjną z wąskim pionowym otworem.
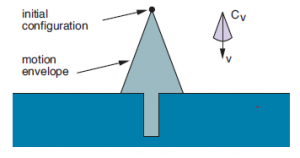
Może to być przestrzeń konfiguracyjna do wkładania prostokątnego kołka w otwór lub kluczyka samochodowego do stacyjki. Polecenia ruchu to stałe prędkości. Warunkiem zakończenia jest kontakt z powierzchnią. Aby modelować niepewność kontroli, zakładamy, że zamiast poruszać się w zadanym kierunku, rzeczywisty ruch robota leży w stożku Cv wokół niego. Rysunek pokazuje, co by się stało, gdyby robot próbował ruszyć w dół z początkowej konfiguracji. Ze względu na niepewność prędkości robot może poruszać się w dowolnym miejscu w stożkowej kopercie, prawdopodobnie wchodząc do otworu, ale bardziej prawdopodobne jest, że wyląduje z jednej strony. Ponieważ robot nie wiedziałby wtedy, po której stronie otworu się znajduje, nie wiedziałby, w którą stronę się poruszać. Bardziej sensowną strategię przedstawiono na wykresach poniższych
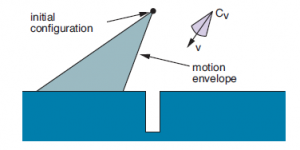
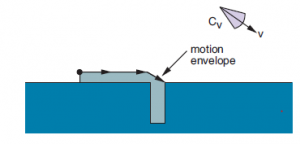
Na rysunku pierwszym robot celowo przesuwa się na jedną stronę otworu. Polecenie ruchu pokazano na rysunku, a test zakończenia polega na kontakcie z dowolną powierzchnią. Na rysunku drugim podano polecenie ruchu, które powoduje, że robot ślizga się po powierzchni i do otworu. Ponieważ wszystkie możliwe prędkości w obwiedni ruchu są w prawo, robot przesunie się w prawo za każdym razem, gdy zetknie się z poziomą powierzchnią. Gdy go dotknie, zsunie się po prawej pionowej krawędzi otworu, ponieważ wszystkie możliwe prędkości spadają w stosunku do pionowej powierzchni. Będzie się poruszał, aż dotrze do dna otworu, ponieważ jest to warunek jego zakończenia. Pomimo niepewności sterowania, wszystkie możliwe trajektorie robota kończą się w kontakcie z dnem otworu – to znaczy, o ile nierówności powierzchni nie spowodują, że robot przyklei się w jednym miejscu. Inne techniki poza strzeżonymi ruchami zmieniają funkcję kosztów, aby zachęcić do działań, o których wiemy, że doprowadzą do uzyskania informacji — takich jak heurystyka nawigacji przybrzeżnej, która wymaga, aby robot pozostawał w pobliżu znanych punktów orientacyjnych. Mówiąc bardziej ogólnie, techniki mogą uwzględniać oczekiwany zysk informacyjny (redukcja entropii przekonania) jako termin w funkcji kosztu, co prowadzi do tego, że robot wyraźnie rozumuje, ile informacji może przynieść każde działanie przy podejmowaniu decyzji, co zrobić. Chociaż trudniejsze obliczeniowo, takie podejścia mają tę zaletę, że robot wymyśla własne działania w zakresie gromadzenia informacji, zamiast polegać na heurystyce dostarczanej przez człowieka i strategiach skryptowych, którym często brakuje elastyczności.