Możliwe jest również użycie RNN do innych zadań językowych, takich jak znakowanie mowy lub rozwiązywanie koferencji. W obu przypadkach warstwa wejściowa i warstwa ukryta będą takie same, ale w przypadku taggera POS wyjściem będzie rozkład softmax na znaczniki POS, a dla rozdzielczości współreferencyjnej będzie to rozkład softmax na możliwych poprzednikach. Na przykład, gdy sieć dotrze do niego w „Eduardo powiedział mi, że Miguel jest bardzo chory, więc zabrałem go do szpitala”, powinno wyświetlić duże prawdopodobieństwo dla „Miguel”. rzucanie RNN na taką klasyfikację odbywa się w taki sam sposób, jak w przypadku modelu językowego. Jedyna różnica polega na tym, że dane treningowe będą wymagały etykiet — części znaczników mowy lub wskazań referencyjnych. To sprawia, że gromadzenie danych jest znacznie trudniejsze niż w przypadku modelu językowego, w którym potrzebujemy tylko tekstu bez etykiety. W modelu językowym chcemy przewidzieć n-te słowo na podstawie poprzednich słów. Ale dla klasyfikacji nie ma powodu, abyśmy ograniczali się do patrzenia tylko na poprzednie słowa. Spojrzenie w przyszłość w zdaniu może być bardzo pomocne. W naszym przykładzie koordynacyjnym referent byłby inny, gdyby zdanie kończyło się „zobaczyć Miguela” zamiast „do szpitala”, więc patrzenie w przyszłość ma kluczowe znaczenie. Z eksperymentów polegających na śledzeniu wzroku wiemy, że czytelnicy nie idą ściśle od lewej do prawej. Aby uchwycić kontekst po prawej stronie, możemy użyć dwukierunkowej sieci RNN, która łączy oddzielny model od prawej do lewej z modelem od lewej do prawej. Przykład użycia dwukierunkowej sieci RNN do znakowania POS pokazano na rysunku 25.5. W przypadku wielowarstwowej sieci RNN zt będzie ukrytym wektorem ostatniej warstwy. W przypadku dwukierunkowej sieci RNN za zt zwykle przyjmuje się konkatenację wektorów z modeli od lewej do prawej i od prawej do lewej. RNN mogą być również używane do zadań klasyfikacji na poziomie zdań (lub na poziomie dokumentu), w których na końcu pojawia się pojedynczy wynik, zamiast strumienia wyników, po jednym na krok czasowy. Na przykład w analizie sentymentu celem jest sklasyfikowanie tekstu jako posiadającego sentyment pozytywny lub negatywny. Na przykład „Ten film został źle napisany i źle zagrany” należy sklasyfikować jako Negatyw. (Niektóre schematy analizy sentymentu wykorzystują więcej niż dwie kategorie lub stosują liczbową wartość skalarną.) Używanie RNN do zadania na poziomie zdania jest nieco bardziej złożone, ponieważ musimy uzyskać zagregowaną reprezentację całego zdania, y z per- słowo wyprowadza yt z RNN. Najprostszym sposobem na to jest użycie ukrytego stanu RNN odpowiadającego ostatniemu słowu wejścia, ponieważ RNN przeczyta całe zdanie w tym kroku. Może to jednak pośrednio skłonić model do zwracania większej uwagi na koniec zdania. Inną powszechną techniką jest łączenie wszystkich ukrytych wektorów. Na przykład, średnie sumowanie oblicza średnią dla elementów ze wszystkich ukrytych wektorów:
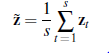
Zebrany w puli d-wymiarowy wektor ˜z może następnie zostać dostarczony do jednej lub większej liczby warstw ze sprzężeniem do przodu przed wprowadzeniem do warstwy wyjściowej.