Wiele wysiłku w badaniach głębokiego uczenia się włożono w znalezienie architektur sieciowych, które dobrze uogólniają. Rzeczywiście, w przypadku każdego konkretnego rodzaju danych – obrazów, mowy, tekstu, wideo itd. – znaczny postęp w wydajności wynika z badania różnych rodzajów architektur sieciowych i zmiany liczby warstw, ich połączeń oraz typy węzłów w każdej warstwie. Niektóre architektury sieci neuronowych są wyraźnie zaprojektowane, aby dobrze uogólniać określone typy danych: sieci splotowe kodują ideę, że ten sam ekstraktor cech jest użyteczny we wszystkich lokalizacjach w siatce przestrzennej, a sieci rekurencyjne kodują ideę, że ta sama reguła aktualizacji jest przydatna w wszystkie punkty w strumieniu danych sekwencyjnych. W zakresie, w jakim te założenia są słuszne, oczekujemy, że architektury splotowe będą dobrze uogólniać obrazy, a sieci rekurencyjne będą dobrze uogólniać sygnały tekstowe i dźwiękowe. Jednym z najważniejszych ustaleń empirycznych w dziedzinie głębokiego uczenia się jest to, że porównując dwie sieci o podobnej liczbie wag, głębsza sieć zwykle zapewnia lepszą wydajność uogólniania. Rysunek
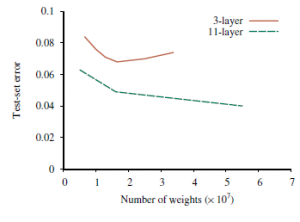
pokazuje ten efekt dla co najmniej jednej aplikacji w świecie rzeczywistym – rozpoznawania numerów domów. Wyniki pokazują, że dla dowolnej stałej liczby parametrów sieć jedenastowarstwowa daje znacznie mniejszy błąd zestawu testowego niż sieć trójwarstwowa. Systemy uczenia głębokiego sprawdzają się dobrze w przypadku niektórych, ale nie wszystkich zadań. W przypadku zadań z wejściami wielowymiarowymi – obrazów, wideo, sygnałów mowy itp. – działają one lepiej niż jakiekolwiek inne podejścia oparte na uczeniu maszynowym. Większość algorytmów może obsługiwać dane wejściowe o dużej wielkości tylko wtedy, gdy są one wstępnie przetwarzane przy użyciu ręcznie zaprojektowanych funkcji w celu zmniejszenia wymiarowości. To podejście do wstępnego przetwarzania, które dominowało przed 2010 r., nie przyniosło wyników porównywalnych z systemami głębokiego uczenia. Najwyraźniej modele głębokiego uczenia się wychwytują niektóre ważne aspekty tych zadań. W szczególności ich sukces oznacza, że zadania mogą być rozwiązywane przez równoległe programy o stosunkowo niewielkiej liczbie kroków (10 do 103 zamiast, powiedzmy, 107). Być może nie jest to zaskakujące, ponieważ te zadania są zazwyczaj rozwiązywane przez mózg w mniej niż sekundę, co wystarcza na zaledwie kilkadziesiąt kolejnych wyładowań neuronowych. Co więcej, badając reprezentacje warstwy wewnętrznej poznane przez głębokie sieci splotowe dla zadań widzenia, znajdujemy dowody na to, że etapy przetwarzania wydają się obejmować wyodrębnianie sekwencji coraz bardziej abstrakcyjnych reprezentacji sceny, zaczynając od maleńkich krawędzi, kropek i elementów narożnych oraz kończąc na całych obiektach i układach wielu obiektów. Z drugiej strony, ponieważ są to proste obwody, modelom uczenia głębokiego brakuje kompozycyjnej i ilościowej mocy ekspresyjnej, którą widzimy w logice pierwszego rzędu i gramatykach bezkontekstowych . Chociaż modele uczenia głębokiego w wielu przypadkach dobrze się uogólniają, mogą również powodować nieintuicyjne błędy. Mają tendencję do tworzenia mapowań wejścia-wyjścia, które są nieciągłe, tak że mała zmiana wejścia może spowodować dużą zmianę wyjścia. Na przykład można zmienić tylko kilka pikseli na obrazie psa i spowodować, że sieć zaklasyfikuje psa jako strusia lub autobus szkolny – nawet jeśli zmieniony obraz nadal wygląda dokładnie jak pies. Zmieniony obraz tego rodzaju nazywany jest przykładem kontradyktoryjności. W przestrzeniach niskowymiarowych trudno znaleźć przykłady kontradyktoryjności. Ale w przypadku obrazu o wartości miliona pikseli często zdarza się, że chociaż większość pikseli przyczynia się do sklasyfikowania obrazu w środku obszaru „psiego” przestrzeni, istnieje kilka wymiarów, w których wartość piksela znajduje się w pobliżu granicy z inną kategorią. Przeciwnik, który potrafi odtworzyć sieć, może znaleźć najmniejszą różnicę wektorów, która przesunęłaby obraz poza granicę. Kiedy po raz pierwszy odkryto przykłady adwersarzy, rozpoczęły się dwie ogólnoświatowe przepychanki: jedna w celu znalezienia algorytmów uczenia i architektur sieciowych, które nie byłyby podatne na ataki adwersarza, a druga w celu stworzenia coraz skuteczniejszych ataków adwersarzy na wszelkiego rodzaju systemy uczące się. Jak dotąd napastnicy wydają się być z przodu. W rzeczywistości, podczas gdy początkowo zakładano, że będzie potrzebny dostęp do wnętrza wyszkolonej sieci, aby zbudować przykład kontradyktoryjności specjalnie dla tej sieci, okazało się, że można zbudować solidne przykłady kontradyktoryjności, które oszukują wiele sieci o różnych architekturach , hiperparametry i zestawy treningowe. Odkrycia te sugerują, że modele uczenia głębokiego rozpoznają obiekty w sposób zupełnie odmienny od ludzkiego układu wzrokowego.