Keras: Aby załadować i zapisać model DNN zasad eksperckich.
Python-chess: Biblioteka symulacji szachów dla Pythona.
Składniki:
RLC_model.h5: Polityka ekspercka
Model Kerasa.
Agent: zawiera wszystkie wymagane funkcje, w tym strategię aktualizacji polityki.
Środowisko: zawiera funkcje związane z charakterystyką środowiska szachowego.
TD_search_m: zawiera kod symulacji gry i kod wyszukiwania MCTS.
Środowisko:
Cel: Efektywnie grać w szachy przeciwko ludzkiemu przeciwnikowi.
Środowisko jest budowane przy użyciu biblioteki o nazwie Python-chess. Rysunek pokazuje szachownicę stworzoną przez Python-chess.

Biblioteka zapewnia:
- Reprezentacja Zarządu
- Reprezentacja sztuk
- Pokolenie ruchu
- Przenieś walidację
- Wsparcie dla UCI (uniwersalny interfejs szachowy), FEN (notacja Forsyth-Edwards), SAN (standardowa notacja algebraiczna).
- Wyrenderuj szachownicę za pomocą SVG (Scalable Vector Graphics)
Fragment kodu : Pseudokod obliczający nagrodę za działanie w określonym stanie.

Obliczanie nagrody:
- Załóżmy, że plansza znajduje się w jakimś pośrednim stanie gry.
- Stan płytki jest modelowany jako węzeł w drzewie MCTS.
- System jest iterowany po wszystkich dzieciach węzła.
- Dla każdego dziecka ten sam proces jest powtarzany aż do pewnej głębokości drzewa.
- Po dotarciu do węzła liścia
- Jeśli nagroda = 1, jeśli system wygra grę.
- Jeśli nagroda = -1, jeśli system przegra grę.
- Nagroda wynosi 0,01 * różnica wartości materialnej stanu początkowego i końcowego dla wszystkich innych sytuacji.
- Na podstawie otrzymanej nagrody końcowej aktualizujemy wartość działania państwa rodzica tego dziecka za pomocą formuł sieci SARSA.
- Val(ParentState,Action) = Val(ParentState,Action) + LearningRate *(Reward of Child State + Discount_Factor *Val(ChildState,Action) – Val(ParentState,Action))
- Używając Val stanu podrzędnego, możemy zaktualizować wartość stanu rodzica o współczynnik uczenia się i współczynnik dyskontowy.
- Para StateAction dla bieżącego węzła ze wszystkimi dziećmi zostaje znaleziona, a ruch, który daje najlepszą nagrodę, jest wybierany jako następny ruch wykonywany przez agenta.
Strategie decyzyjne agenta – zasady:
Agent wykorzystuje dwa różne rodzaje strategii podejmowania decyzji, aby wykonać ruch. Oni są:
- Eksploracja: Wybiera losowy ruch z listy dozwolonych ruchów i bada różne stany gry.
- Eksploatacja: Wybiera ruch spośród dozwolonych ruchów, który ma największe prawdopodobieństwo wygranej.
W każdym stanie agent poświęca 1 sekundę na rozszerzenie MCTS. Kroki wykonywane przez agenta przez 1 sekundę są pokazane na rysunku.
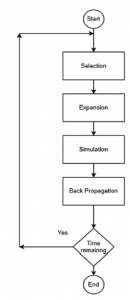
Są to:
- Wybór: Wybierz ruch z listy dozwolonych ruchów.
- Rozszerzenie: Utwórz nowy węzeł podrzędny, jeśli węzeł nie istnieje lub przenieś się do istniejącego węzła podrzędnego.
- Symulacja: Wykonaj krok 1 (Wybór) i krok 2 (Rozbudowa) kilkakrotnie, aż upłynie czas.
- Propagacja wsteczna: Po upływie czasu nagroda zostanie przyznana. Węzły nadrzędne można aktualizować za pomocą funkcji wartości SARSA.