Agent adaptacyjnego programowania dynamicznego (lub ADP) wykorzystuje ograniczenia między użytecznościami stanów, ucząc się modelu przejścia, który je łączy i rozwiązując odpowiedni proces decyzyjny Markowa za pomocą programowania dynamicznego. W przypadku pasywnego agenta uczącego oznacza to podłączenie wyuczonego modelu przejścia P(s’ | s; π(s)) i obserwowanych nagród R(s, π(s), s’) do równania w celu obliczenia użyteczności stanów . Jak zauważyliśmy w naszej dyskusji na temat iteracji polityki , te równania Bellmana są liniowe, gdy polityka π jest ustalona, więc można je rozwiązać przy użyciu dowolnego pakietu algebry liniowej. Alternatywnie, możemy przyjąć podejście iteracji zmodyfikowanej polityki , używając uproszczonego procesu iteracji wartości w celu aktualizacji oszacowań użyteczności po każdej zmianie wyuczonego modelu. Ponieważ model zwykle zmienia się tylko nieznacznie z każdą obserwacją, proces iteracji wartości może wykorzystywać poprzednie oszacowania użyteczności jako wartości początkowe i zazwyczaj bardzo szybko się zbiegają. Nauka modelu przejścia jest łatwa, ponieważ środowisko jest w pełni obserwowalne. Oznacza to, że mamy nadzorowane zadanie uczenia się, w którym danymi wejściowymi dla każdego przykładu uczącego jest para stan-działanie (s,a), a wyjściem jest stan wynikowy s’. Model przejścia P(s’ |s,a) jest reprezentowany w postaci tabeli i jest szacowany bezpośrednio na podstawie zliczeń zgromadzonych w Ns’0|sa. Liczby rejestrują, jak często stan s’ jest osiągany podczas wykonywania a w s. Na przykład, w trzech próbach ,Prawo jest wykonywane cztery razy w (3,3), a wynikowy stan to (3,2) dwa razy i (4,3) dwa razy, więc P((3,2) j (3,3),Prawo) i P((4,3) j (3,3),Prawo) szacuje się na 12 . Pełny program agenta dla pasywnego agenta ADP pokazano tu

Jego wydajność na świecie 4 3 pokazano na rysunku .
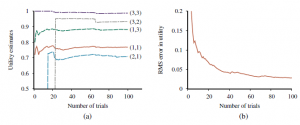
Jeśli chodzi o szybkość poprawy oszacowań wartości, agent ADP jest ograniczony jedynie zdolnością uczenia się modelu przejścia. W tym sensie zapewnia standard, w stosunku do którego można mierzyć inne algorytmy uczenia się przez wzmacnianie. Jest jednak niewykonalny w przypadku dużych przestrzeni państwowych. Na przykład w tryktraku wymagałoby to rozwiązania około 1020 równań w 1020 niewiadomych.