https://aie24.pl/
Rozwiązanie podstawowego MDP, jak w poprzedniej sekcji, nie jest jedynym sposobem na zastosowanie równań Bellmana do problemu uczenia się. Innym sposobem jest wykorzystanie obserwowanych przejść do dostosowania użyteczności obserwowanych stanów tak, aby zgadzały się z równaniami więzów. Rozważmy na przykład przejście od (1,3) do (2,3) w drugiej próbie na stronie 843. Załóżmy, że w wyniku pierwszej próby oszacowania użyteczności wynoszą Uπ(1,3)=0,88 i Uπ (2;3)=0,:96. Teraz, gdyby to przejście od (1,3) do (2,3) zachodziło cały czas, oczekiwalibyśmy, że narzędzia będą zgodne z równaniem
Uπ(1,3) = -0:04+Uπ(2,3) ;
więc Uπ(1,3) byłoby 0,92. Tym samym jego obecne szacunki na poziomie 0,88 mogą być nieco zaniżone i powinny zostać podwyższone. Mówiąc bardziej ogólnie, gdy następuje przejście ze stanu s do stanu s’ poprzez akcję (s), stosujemy następującą aktualizację do π(s):
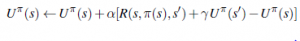
Tu α to parametr szybkości uczenia się. Ponieważ ta reguła aktualizacji wykorzystuje różnicę użyteczności między kolejnymi stanami (a tym samym kolejnymi czasami), jest często nazywana równaniem różnicy czasowej (TD). Podobnie jak w zasadach aktualizacji wag , termin TD R(s,π (s); s’)+ γUπ(s’)-Uπ(s) jest efektywnie sygnał błędu, a aktualizacja ma na celu zmniejszenie błędu. Wszystkie metody różnic czasowych działają poprzez dostosowanie oszacowań użyteczności w kierunku idealnej równowagi, która utrzymuje się lokalnie, gdy oszacowania użyteczności są prawidłowe. W przypadku uczenia się pasywnego równowaga jest dana równaniem
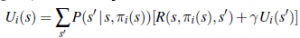
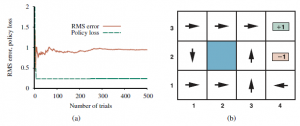
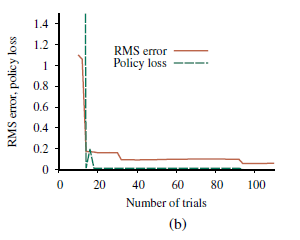
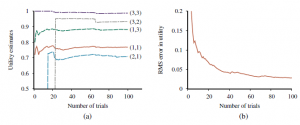
Tu α to parametr szybkości uczenia się. Ponieważ ta reguła aktualizacji wykorzystuje różnicę użyteczności między kolejnymi stanami (a tym samym kolejnymi czasami), jest często nazywana równaniem różnicy czasowej (TD). Podobnie jak w zasadach aktualizacji wag , termin TD R(s,π (s); s’)+ γUπ(s’)-Uπ(s) jest efektywnie sygnał błędu, a aktualizacja ma na celu zmniejszenie błędu. Wszystkie metody różnic czasowych działają poprzez dostosowanie oszacowań użyteczności w kierunku idealnej równowagi, która utrzymuje się lokalnie, gdy oszacowania użyteczności są prawidłowe. W przypadku uczenia się pasywnego równowaga jest dana równaniem). Teraz powyższe faktycznie powoduje, że agent osiąga równowagę podaną przez równanie wcześniejsze, ale wiąże się to z pewną subtelnością. Po pierwsze, zauważ, że aktualizacja dotyczy tylko obserwowanego następcy s0, podczas gdy rzeczywiste warunki równowagi obejmują wszystkie możliwe kolejne stany. Można by pomyśleć, że powoduje to niewłaściwie dużą zmianę Uπ(s), gdy występuje bardzo rzadkie przejście; ale w rzeczywistości, ponieważ rzadkie przejścia występują rzadko, średnia wartość Uπ(s) zbiegnie się do prawidłowej wartości w limicie, nawet jeśli sama wartość będzie się zmieniać. Co więcej, jeśli zmienimy parametr w funkcję, która zmniejsza się wraz ze wzrostem liczby odwiedzin danego stanu, wówczas samo Uπ(s) zbiegnie się do prawidłowej wartości. Rysunek ilustruje wydajność pasywnego agenta TD na świecie 4 3.
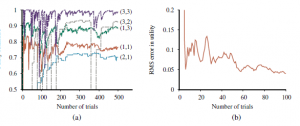
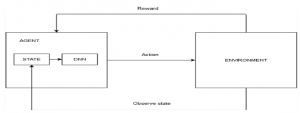
Nie uczy się tak szybko jak agent ADP i wykazuje znacznie większą zmienność, ale jest znacznie prostszy i wymaga znacznie mniej obliczeń na obserwację. Zauważyłem, że TD nie potrzebuje modelu przejściowego do przeprowadzenia aktualizacji. Samo środowisko zasila połączenia między sąsiadującymi państwami w postaci obserwowanych przejść. Podejścia ADP i TD są ze sobą ściśle powiązane. Obaj starają się dokonywać lokalnych korekt szacunków użyteczności, aby każdy stan „zgadzał się” ze swoimi następcami. Jedną z różnic jest to, że TD dostosowuje stan, aby zgadzał się z obserwowanym następcą (Równanie (23.3)), podczas gdy ADP dostosowuje stan, aby zgadzał się ze wszystkimi następcami, które mogą wystąpić, ważonymi ich prawdopodobieństwami . Ta różnica znika, gdy efekty korekt TD są uśredniane dla dużej liczby przejść, ponieważ częstotliwość każdego następcy w zestawie przejść jest w przybliżeniu proporcjonalna do jego prawdopodobieństwa. Ważniejsza różnica polega na tym, że podczas gdy TD dokonuje pojedynczej korekty na obserwowane przejście, ADP dokonuje tyle, ile potrzeba, aby przywrócić spójność między oszacowaniami użyteczności U a modelem przejścia P. Chociaż obserwowane przejście powoduje tylko lokalną zmianę w P, jego efekty mogą wymagać propagowania w całym U. Tak więc TD można postrzegać jako prymitywne, ale skuteczne pierwsze przybliżenie do ADP. Każda korekta dokonana przez ADP mogła być postrzegana, z punktu widzenia TD, jako wynik pseudodoświadczenia wygenerowanego przez symulację obecnego modelu przejścia. Możliwe jest rozszerzenie podejścia TD o wykorzystanie modelu przejścia do generowania kilku pseudodoświadczeń – przejść, które agent TD może sobie wyobrazić, biorąc pod uwagę jego obecny model. Dla każdego obserwowanego przejścia agent TD może wygenerować dużą liczbę urojonych przejść. W ten sposób uzyskane szacunki użyteczności będą coraz bardziej zbliżać się do tych z ADP – oczywiście kosztem wydłużenia czasu obliczeń. W podobnym duchu możemy generować wydajniejsze wersje ADP, bezpośrednio przybliżając algorytmy iteracji wartości lub iteracji polityki. Chociaż algorytm iteracji wartości jest wydajny, jest niewykonalny, jeśli mamy, powiedzmy, 10100 stanów. Jednak wiele niezbędnych korekt wartości stanu w każdej iteracji będzie bardzo małych. Jednym z możliwych podejść do szybkiego generowania dość dobrych odpowiedzi jest ograniczenie liczby korekt dokonywanych po każdym zaobserwowanym przejściu. Można również użyć heurystyki, aby uszeregować możliwe korekty tak, aby przeprowadzić tylko te najważniejsze. Szeroko zakrojona heurystyka z priorytetami woli dokonywać korekt stanów, których prawdopodobni następcy właśnie przeszli dużą korektę w swoich własnych szacunkach użyteczności.
Używając takiej heurystyki, przybliżone algorytmy ADP mogą uczyć się mniej więcej tak szybko, jak pełne ADP, pod względem liczby sekwencji treningowych, ale mogą być o rząd wielkości bardziej wydajne pod względem obliczeń całkowitych. Dzięki temu mogą obsługiwać przestrzenie stanów, które są zbyt duże dla pełnego ADP. Przybliżone algorytmy ADP mają dodatkową zaletę: na wczesnych etapach uczenia się nowego środowiska model przejścia P często będzie daleki od poprawności, więc nie ma sensu obliczać dokładnej funkcji użyteczności, która by mu odpowiadała. Algorytm aproksymacyjny może używać minimalnego rozmiaru korekty, który zmniejsza się, gdy model przejścia staje się dokładniejszy. Eliminuje to bardzo długie cykle iteracji wartości, które mogą wystąpić na wczesnym etapie uczenia się z powodu dużych zmian w modelu.