https://aie24.pl/
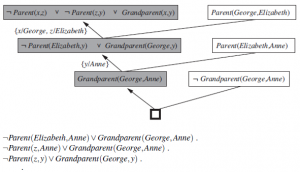
Procedura odwrotnego rozwiązywania, która odwraca pełną strategię rozwiązywania, jest w zasadzie kompletnym algorytmem do uczenia się teorii pierwszego rzędu. Oznacza to, że jeśli jakaś nieznana Hipoteza generuje zestaw przykładów, wówczas procedura odwrotnego rozwiązywania może wygenerować Hipotezę na podstawie przykładów. Ta obserwacja sugeruje interesującą możliwość: Załóżmy, że dostępne przykłady obejmują różne trajektorie spadających ciał. Czy program odwrotnej rozdzielczości byłby teoretycznie zdolny do wywnioskowania prawa grawitacji? Odpowiedź jest oczywiście tak, ponieważ prawo grawitacji pozwala wyjaśnić przykłady, biorąc pod uwagę odpowiednie podstawy matematyczne. Podobnie można sobie wyobrazić, że elektromagnetyzm, mechanika kwantowa i teoria względności również wchodzą w zakres programów ILP. Oczywiście są one również w zasięgu małpy z maszyną do pisania; wciąż potrzebujemy lepszych heurystyk i nowych sposobów strukturyzowania przestrzeni wyszukiwania. Jedną z rzeczy, które zrobią dla ciebie systemy odwróconej rozdzielczości, jest wymyślenie nowych predykatów. Ta zdolność jest często postrzegana jako nieco magiczna, ponieważ komputery są często postrzegane jako „tylko pracujące z tym, co im dane”. W rzeczywistości nowe predykaty wypadają bezpośrednio z kroku rozwiązywania odwrotnego. Najprostszym przypadkiem jest postawienie hipotezy o dwóch nowych klauzulach C1 i C2, biorąc pod uwagę klauzulę C. Rozwiązanie C1 i C2 eliminuje dosłowny wspólny dla dwóch klauzul; stąd całkiem możliwe, że wyeliminowany literał zawierał orzeczenie, które nie występuje w C. Tak więc podczas pracy wstecz jedną z możliwości jest wygenerowanie nowego predykatu, z którego można zrekonstruować brakujący literał.
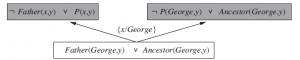
Po wygenerowaniu P może być używane w późniejszych krokach rozdzielczości odwrotnej. Na przykład, późniejszy krok może postawić hipotezę, że Mother(x;y) ) P(x;y). Zatem nowy predykat P ma swoje znaczenie ograniczone przez generowanie hipotez, które go dotyczą. Inny przykład może prowadzić do ograniczenia Ojciec(x;y) ) P(x;y). Innymi słowy, predykat P jest tym, o czym zwykle myślimy jako o relacji rodzicielskiej. Jak wspomnieliśmy wcześniej, wynalezienie nowych predykatów może znacznie zmniejszyć rozmiar definicji predykatu celu. W związku z tym, dzięki możliwości wymyślania nowych predykatów, systemy odwrotnego rozwiązywania często mogą rozwiązywać problemy uczenia się, które są niewykonalne przy użyciu innych technik. Niektóre z najgłębszych rewolucji w nauce pochodzą z wynalezienia nowych predykatów i funkcji — na przykład wynalezienie przyspieszenia przez Galileusza lub wynalezienie energii cieplnej przez Joule’a. Gdy te terminy są dostępne, odkrywanie nowych praw staje się (stosunkowo) łatwe. Najtrudniejsza część polega na uświadomieniu sobie, że jakiś nowy byt, mający specyficzny związek z istniejącymi bytami, pozwoli wyjaśnić cały zbiór obserwacji za pomocą znacznie prostszej i bardziej eleganckiej teorii niż istniała wcześniej. Jak dotąd systemy ILP nie dokonały odkryć na poziomie Galileusza czy Joule’a, ale ich odkrycia zostały uznane za możliwe do opublikowania w literaturze naukowej. Na przykład w Journal of Molecular Biology, Turcotte i inni opisują automatyczne odkrywanie reguł fałdowania białek za pomocą programu ILP PROGOL. Wiele reguł odkrytych przez PROGOL można było wyprowadzić ze znanych zasad, ale większość z nich nie została wcześniej opublikowana jako część standardowej bazy danych biologicznych. . W pracy pokrewnej Srinivasan zajmował się problemem odkrywania opartych na strukturze molekularnej reguł mutagenności związków nitroaromatycznych. Związki te znajdują się w spalinach samochodowych. Dla 80% związków w standardowej bazie danych możliwe jest zidentyfikowanie czterech ważnych cech, a regresja liniowa tych cech przewyższa ILP. W przypadku pozostałych 20% same cechy nie są predyktywne, a ILP identyfikuje relacje, które pozwalają mu przewyższać regresję liniową, sieci neuronowe i drzewa decyzyjne. Co najbardziej imponujące, King i inni wyposażyli robota w możliwość przeprowadzania eksperymentów z biologii molekularnej i rozszerzyli techniki ILP o projektowanie eksperymentów, tworząc w ten sposób autonomicznego naukowca, który faktycznie odkrył nową wiedzę na temat funkcjonalnej genomiki drożdży. W przypadku wszystkich tych przykładów wydaje się, że zdolność zarówno do reprezentowania relacji, jak i korzystania z wiedzy podstawowej przyczynia się do wysokiej wydajności ILP. Fakt, że zasady znalezione przez ILP mogą być interpretowane przez ludzi, przyczynia się do akceptacji tych technik w czasopismach biologicznych, a nie tylko w czasopismach informatycznych. ILP wniosła wkład do innych nauk poza biologią. Jednym z najważniejszych jest przetwarzanie języka naturalnego, w którym ILP zostało wykorzystane do wyodrębnienia złożonych informacji relacyjnych z tekstu.