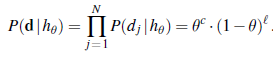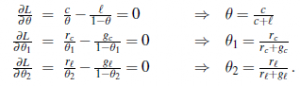https://aie24.pl/
Kluczowymi pojęciami tu, są dane i hipotezy. Tutaj dane są dowodem, to znaczy egzemplarzami niektórych lub wszystkich zmiennych losowych opisujących domenę. Hipotezy przedstawione w tym rozdziale to probabilistyczne teorie działania dziedziny, w tym teorie logiczne jako przypadek szczególny. Rozważ prosty przykład. Nasze ulubione cukierki-niespodzianki występują w dwóch smakach: wiśniowym (mniam) i limonkowym (ugh). Producent ma swoiste poczucie humoru i niezależnie od smaku zawija każdy cukierek w to samo nieprzezroczyste opakowanie. Cukierek sprzedawany jest w bardzo dużych torebkach, których znanych jest pięć rodzajów – znowu nie do odróżnienia z zewnątrz:
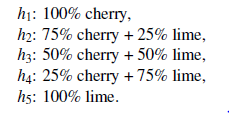
Biorąc pod uwagę nową torebkę cukierków, zmienna losowa H (dla hipotezy) oznacza rodzaj torebki, z możliwymi wartościami od h1 do h5. Oczywiście H nie można zaobserwować bezpośrednio. Gdy kawałki cukierka są otwierane i sprawdzane, ujawniają się dane-D1, D2, …, DN, gdzie każdy Di jest zmienną losową z możliwymi wartościami wiśni i limonki. Podstawowym zadaniem stojącym przed agentem jest przewidzenie smaku kolejnego cukierka. Ten scenariusz, mimo pozornej banalności, wprowadza wiele istotnych kwestii. Agent naprawdę musi wywnioskować teorię swojego świata, aczkolwiek bardzo prostą. Uczenie bayesowskie po prostu oblicza prawdopodobieństwo każdej hipotezy na podstawie danych i dokonuje na tej podstawie przewidywań. Oznacza to, że prognozy są dokonywane przy użyciu wszystkich hipotez ważonych ich prawdopodobieństwem, a nie tylko jednej „najlepszej” hipotezy. W ten sposób uczenie się sprowadza się do wnioskowania probabilistycznego. Niech D reprezentuje wszystkie dane, z obserwowaną wartością d. Kluczowe wielkości w podejściu bayesowskim to uprzednia hipoteza P(hi) oraz prawdopodobieństwo danych w ramach każdej hipotezy, P(d|hi). Prawdopodobieństwo każdej hipotezy uzyskuje się z reguły Bayesa:
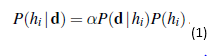
Załóżmy teraz, że chcemy przewidzieć nieznaną wielkość X. Wtedy mamy
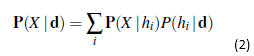
gdzie każda hipoteza określa rozkład prawdopodobieństwa względem X. Równanie to pokazuje, że predykcje są średnimi ważonymi predykcji poszczególnych hipotez, gdzie waga P(hi|d) jest proporcjonalna do prawdopodobieństwa uprzedniego hi i jego stopnia dopasowania, zgodnie z Równaniem (1). Same hipotezy są zasadniczo „pośrednikami” między surowymi danymi a przewidywaniami. Dla naszego przykładu ze słodyczami przyjmiemy na razie, że uprzedni rozkład nad h1,…,h5 jest podane przez <0.1,0.2,0.4,0.2,0.1>, jak reklamuje producent. Prawdopodobieństwo danych jest obliczane przy założeniu, że obserwacje są i.i.d. , aby
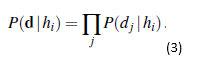
Załóżmy na przykład, że torebka jest w rzeczywistości całkowicie limonkowa (h5), a pierwsze 10 cukierków to w całości limonka; wtedy P(d|h3) wynosi 0.510, ponieważ połowa cukierków w torebce h3 to wapno. Rysunek (a) pokazuje, jak zmieniają się prawdopodobieństwo a posteriori pięciu hipotez, gdy obserwuje się sekwencję 10 cukierków z wapnem.
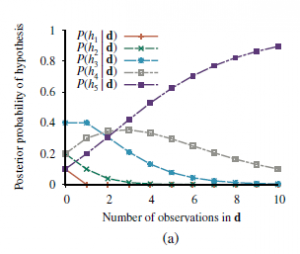
Zauważ, że prawdopodobieństwa zaczynają się od poprzednich wartości, więc h3 jest początkowo najbardziej prawdopodobnym wyborem i pozostaje takie po rozpakowaniu 1 cukierka z limonką. Po rozpakowaniu 2 cukierków z limonką, najprawdopodobniej h4; po 3 lub więcej, najbardziej prawdopodobne jest h5 (przerażająca torebka z limonką). Po 10 z rzędu jesteśmy dość pewni naszego losu. Rysunek (b) pokazuje przewidywane prawdopodobieństwo, że następnym cukierkiem będzie limonka, na podstawie równania (2).
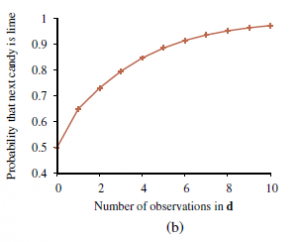
Jak oczekiwalibyśmy, wzrasta ona monotonicznie do 1. Przykład pokazuje, że przewidywanie bayesowskie ostatecznie zgadza się z prawdziwą hipotezą. Jest to charakterystyczne dla uczenia bayesowskiego. W przypadku dowolnego ustalonego a priori, które nie wyklucza prawdziwej hipotezy, prawdopodobieństwo a posteriori jakiejkolwiek fałszywej hipotezy w pewnych warunkach technicznych ostatecznie zniknie. Dzieje się tak po prostu dlatego, że prawdopodobieństwo generowania „nietypowych” danych w nieskończoność jest znikomo małe. Co ważniejsze, przewidywanie bayesowskie jest optymalne, niezależnie od tego, czy zbiór danych jest mały czy duży. Biorąc pod uwagę wcześniejszą hipotezę, oczekuje się, że każda inna prognoza będzie poprawna rzadziej. Oczywiście optymalność uczenia bayesowskiego ma swoją cenę. W przypadku rzeczywistych problemów z uczeniem się przestrzeń hipotez jest zwykle bardzo duża lub nieskończona, jak widzieliśmy w rozdziale 19. W niektórych przypadkach sumowanie w równaniu (2) (lub całkowanie w przypadku ciągłym) można przeprowadzić w sposób praktyczny, ale w w większości przypadków musimy uciekać się do metod przybliżonych lub uproszczonych. Bardzo powszechnym przybliżeniem – takim, które jest zwykle przyjmowane w nauce – jest dokonywanie przewidywań na podstawie jednej najbardziej prawdopodobnej hipotezy – to znaczy hi maksymalizuje P(hi|d). Jest to często nazywane hipotezą maksimum a posteriori lub MAP (wymawiane „em-ay-pee”). Prognozy wykonane zgodnie z hipotezą MAP hMAP są w przybliżeniu bayesowskie do tego stopnia, że P(X|d) ≈ P(X |hMAP). W naszym przykładzie cukierków hMAP=h5 po trzech cukierkach z limonką z rzędu, więc uczeń MAP przewiduje, że czwarty cukierek to limonka z prawdopodobieństwem 1,0 – o wiele bardziej niebezpieczna prognoza niż przewidywanie bayesowskie 0,8 pokazane na rysunku (b). . W miarę napływu większej ilości danych prognozy MAP i Bayesa stają się coraz bliższe, ponieważ konkurencja dla hipotezy MAP staje się coraz mniej prawdopodobna. Chociaż ten przykład tego nie pokazuje, znajdowanie hipotez MAP jest często znacznie łatwiejsze niż uczenie bayesowskie, ponieważ wymaga rozwiązania problemu optymalizacji zamiast dużego problemu sumowania (lub integracji). Zarówno w uczeniu bayesowskim, jak i uczeniu MAP ważną rolę odgrywa hipoteza poprzedzająca P(hi). W rozdziale 19 widzieliśmy, że nadmierne dopasowanie może wystąpić, gdy przestrzeń hipotez jest zbyt wyrazista, to znaczy, gdy zawiera wiele hipotez, które dobrze pasują do zbioru danych. Metody uczenia bayesowskiego i MAP wykorzystują wcześniejsze, aby ukarać złożoność. Zazwyczaj bardziej złożone hipotezy mają niższe prawdopodobieństwo a priori – po części dlatego, że jest ich tak wiele. Z drugiej strony bardziej złożone hipotezy mają większą zdolność dopasowania danych. (W skrajnym przypadku tabela przeglądowa może dokładnie odtworzyć dane). Dlatego wcześniejsza hipoteza zawiera kompromis między złożonością hipotezy a jej stopniem dopasowania do danych. Efekt tego kompromisu widać najwyraźniej w przypadku logicznym, w którym H zawiera tylko hipotezy deterministyczne (takie jak h1, który mówi, że każdy cukierek jest wiśnią). W takim przypadku P(d|hi) wynosi 1, jeśli hi jest spójne, a 0 w przeciwnym razie. Patrząc na równanie (1), widzimy, że hMAP będzie wtedy najprostszą teorią logiczną, która jest zgodna z danymi. Dlatego nauka J maksymalnie a posteriori stanowi naturalne ucieleśnienie brzytwy Ockhama. Inny wgląd w kompromis między złożonością a stopniem dopasowania można uzyskać, logarytmując równanie (1). Wybranie hMAP do maksymalizacji P(djhi)P(hi) jest równoznaczne z minimalizacją
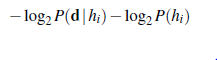
Używając związku między kodowaniem informacji a prawdopodobieństwem, widzimy, że wyraz -log2 P(hi) jest równy liczbie bitów wymaganych do sprecyzowania hipotezy hi. Co więcej, -log2 P(d|hi) to dodatkowa liczba bitów wymagana do sprecyzowania danych przy założeniu hipotezy. (Aby to zobaczyć, weź pod uwagę, że nie są wymagane żadne bity, jeśli hipoteza dokładnie przewiduje dane – jak w przypadku h5 i sznurka cukierków z limonki – i log2 1=0.) Dlatego uczenie MAP polega na wyborze hipotezy, która zapewnia maksymalną kompresję dane. Do tego samego zadania odnosi się bardziej bezpośrednio metoda uczenia się z minimalną długością opisu, czyli MDL. Podczas gdy uczenie MAP wyraża prostotę, przypisując wyższe prawdopodobieństwa prostszym hipotezom, MDL wyraża to bezpośrednio, licząc bity w binarnym kodowaniu hipotez i danych. Ostatecznym uproszczeniem jest założenie jednolitego a priori nad przestrzenią hipotez. W takim przypadku uczenie się MAP sprowadza się do wybrania hi, które maksymalizuje P(d|hi). Nazywa się to hipotezą maksymalnego prawdopodobieństwa, hML. Nauka maksymalnego prawdopodobieństwa jest bardzo powszechna w statystyce, dyscyplinie, w której wielu badaczy nie ufa subiektywnej naturze hipotez a priori. Jest to rozsądne podejście, gdy nie ma powodu, aby a priori przedkładać jedną hipotezę nad inną — na przykład, gdy wszystkie hipotezy są jednakowo złożone. Gdy zestaw danych jest duży, wcześniejszy rozkład nad hipotezami jest mniej ważny – dowody z danych są wystarczająco mocne, aby zasypać wcześniejszy rozkład hipotezami. Oznacza to, że uczenie z maksymalnym prawdopodobieństwem jest dobrym przybliżeniem do uczenia bayesowskiego i MAP z dużymi zestawami danych, ale ma problemy (jak zobaczymy) z małymi zestawami danych.