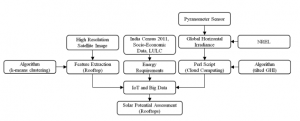
https://aie24.pl/
Zdjęcia satelitarne o wysokiej rozdzielczości zostały wyodrębnione za pomocą Google Earth Pro i podzielone na 43 segmenty. Algorytm k-średnich został zastosowany do poszczególnych segmentowanych części w celu wyodrębnienia obrysu budynku dla powierzchni kwadratowej. Kilka wyników uzyskanych przy użyciu algorytmu grupowania k-średnich w celu wyodrębnienia śladów budynków pokazano na rysunku .
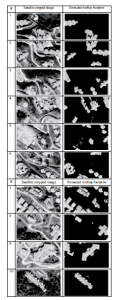
Wyodrębnione ślady wszystkich budynków ze zdjęć satelitarnych pokazano na rysunku.
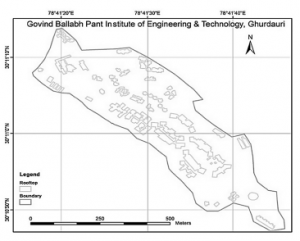
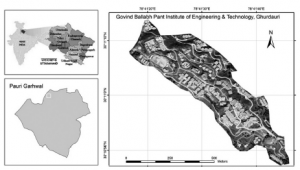
Całkowita powierzchnia dachu budynku GBPIET w Ghurdauri wynosi 34 462 m2. Z tej całkowitej powierzchni dachu 70%, tj. 24 124 m2 zostało uwzględnione do oszacowania potencjału słonecznego. 30% powierzchni zostało zarezerwowane pod infrastrukturę i konserwację fotowoltaiki słonecznej. Intensywne obliczeniowo zadania polegające na znalezieniu optymalnego kąta pochylenia i pochylenia GHI zostały wykonane przy użyciu architektury Hadoop w chmurze obliczeniowej XenCenter. Wartość optymalnego kąta pochylenia uzyskanego po kilku iteracjachi i walidacjia z wykorzystaniem wygenerowanych i przewidywanych wyjść PV na dachach GBPIET, Ghurdauri wynosi około 20,18°
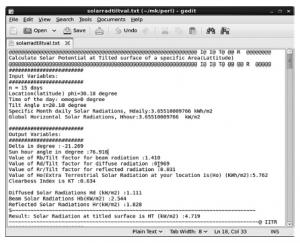
Przy tym kącie nachylenia panele fotowoltaiczne są w stanie wytworzyć maksymalny kwant energii elektrycznej z energii słonecznej. Podobne podejście można zastosować również w innych lokalizacjach. Ocena tego kąta pochylenia została również potwierdzona lokalnymi danymi GHI (piranometrycznymi) i danymi meteorologicznymi. Wartości GHI pochodzące z NREL zostały wykorzystane do oszacowania miesięcznych i rocznych oszacowań nasłonecznienia przy nachylonej fotowoltaice słonecznej. Wartości GHI w ujęciu miesięcznym/rocznym przedstawia tabela
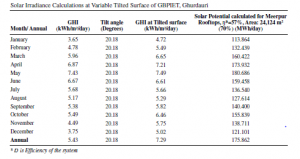
Natychmiastowe oszacowanie nasłonecznienia za pomocą piranometru zostało obliczone i stwierdzono, że jest on w stanie spełnić pełne wymagania energetyczne, jak pokazano w tabeli

To pokazuje, że oszacowany potencjał słoneczny jest wystarczający do uzupełnienia zapotrzebowania na energię elektryczną GBPIET, Ghurdauri. Wartości irradiancji wahają się od 4 do 6 kWh/m2/dzień, 6-6,8 kWh/m2/dzień, 3,5-5,5 kWh/m2/dzień i 6,9-7,1 kWh/m2/dzień przy użyciu CAMS McClear, NASA POWER, SMART, i odpowiednio pochylony GHI. Wartości RMSE uzyskane między irradiancjami za pomocą nachylonego GHI i modeli pochodzących z satelitów wynoszą 0,30 (CAMS McClear), 0,12 (NASA POWER) i 0,31 (SMARTS). Wartości uzyskane za pomocą modelu CAMS McClear wykorzystują warunki pogodowe w czasie rzeczywistym za pomocą usług internetowych i dostarczają wartości irradiancji. NASA POWER wykorzystuje produkty pochodzące z satelitów i parametry meteorologiczne w celu zapewnienia wartości napromieniowania. Mapa zasobów słonecznych uzyskana za pomocą modelu NASA POWER jest bardzo dokładna do pomiarów naziemnych, tj. piranometru. Zostało to potwierdzone odczytem uzyskanym przy użyciu piranometru i pochylonego GHI. W związku z tym na podstawie tych badań wyciągnięto wniosek, że model NASA POWER daje wartości bliższe pochylonemu GHI, potwierdzonemu za pomocą odczytów piranometrycznych. Ocena tych modeli została przeprowadzona przy użyciu wartości RMSE uzyskanych pomiędzy modelami pochodzącymi z satelity (CAMS McClear, SMARTS i NASA POWER) a podejściem nachylonym GHI. Wartość RMSE uzyskana dla NASA POWER wynosi 0,12. Wskazuje to na dobrą korelację z rozwiniętym podejściem pochylonego GHI.