Aby nauczyć się sieci bayesowskiej z ukrytymi zmiennymi, stosujemy te same spostrzeżenia, które działały w przypadku mieszanek Gaussa. Rysunek(a)
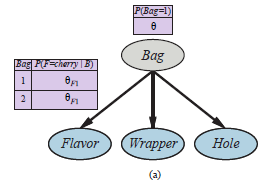
przedstawia sytuację, w której zmieszano dwie torebki cukierków. Cukierki są opisane trzema cechami: oprócz Smaku i Opakowania, niektóre cukierki mają otwór w środku, a niektóre nie. Rozkład cukierków w każdej torebce jest opisany przez naiwny model Bayesa: cechy są niezależne dla danej torebki, ale rozkład prawdopodobieństwa warunkowego dla każdej cechy zależy od torebki. Parametry są następujące: θ jest prawdopodobieństwem a priori, że cukierek pochodzi z Bag 1; θF1 i θF2 to prawdopodobieństwa, że smak jest wiśniowy, biorąc pod uwagę, że cukierek pochodzi odpowiednio z Torebki 1 lub Torebki 2; θW1 i θW2 podają prawdopodobieństwa, że opakowanie jest czerwone; a θH1 i θH2 dają prawdopodobieństwo, że cukierek ma dziurkę. Ogólny model to model mieszany: ważona suma dwóch różnych rozkładów, z których każdy jest iloczynem niezależnych rozkładów jednowymiarowych. (W rzeczywistości możemy również modelować mieszaninę Gaussów jako sieć bayesowską, jak pokazano na rysunku (b).)
Na rysunku torebka jest zmienną ukrytą, ponieważ po zmieszaniu cukierków już nie wiedzieć, z której torby pochodzi każdy cukierek. Czy w takim razie możemy odzyskać opisy dwóch torebek, obserwując cukierki z mieszanki? Przejdźmy przez iterację EM dla tego problemu. Najpierw spójrzmy na dane. Wygenerowaliśmy 1000 próbek z modelu, którego prawdziwe parametry są następujące:
![]()
Oznacza to, że cukierki z równym prawdopodobieństwem pochodzą z obu toreb; pierwszy to głównie wiśnia z czerwonymi obwoluty i dziurkami; drugi to głównie limonka z zielonymi opakowaniami i bez dziur. Liczba ośmiu możliwych rodzajów cukierków jest następująca:
Zaczynamy od inicjalizacji parametrów. Dla uproszczenia numerycznego wybieramy arbitralnie
![]()
Najpierw popracujmy nad parametrem θ. W przypadku w pełni obserwowalnym oszacowalibyśmy to bezpośrednio na podstawie zaobserwowanej liczby cukierków z torebek 1 i 2. Ponieważ torebka jest zmienną uk rytą, zamiast tego obliczamy oczekiwane liczby. Oczekiwana liczba ![]() jest sumą prawdopodobieństwa, że cukierek pochodzi z woreczka 1 dla wszystkich cukierków.
jest sumą prawdopodobieństwa, że cukierek pochodzi z woreczka 1 dla wszystkich cukierków.
![]()
Prawdopodobieństwa te można obliczyć za pomocą dowolnego algorytmu wnioskowania dla sieci bayesowskich. W przypadku naiwnego modelu Bayesa, takiego jak ten w naszym przykładzie, możemy wnioskować „ręcznie”, korzystając z reguły Bayesa i stosując warunkową niezależność:
![]()
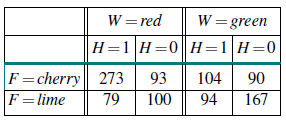
Stosując tę formułę do, powiedzmy, 273 cukierków wiśniowych w czerwonych opakowaniach z dziurkami, otrzymujemy wkład w wysokości
![]()
Kontynuując z pozostałymi siedmioma rodzajami cukierków w tabeli liczebności, otrzymujemy θ(1)=0:6124. Rozważmy teraz inne parametry, takie jak θF1. W przypadku w pełni obserwowalnym oszacowalibyśmy to bezpośrednio na podstawie zaobserwowanej liczby cukierków wiśniowych i limonkowych z torebki 1. Oczekiwana liczba cukierków wiśniowych z torebki 1 jest dana wzorem
![]()
Ponownie, prawdopodobieństwa te można obliczyć dowolnym algorytmem sieci Bayesa. Kończąc ten proces otrzymujemy nowe wartości wszystkich parametrów:
![]()
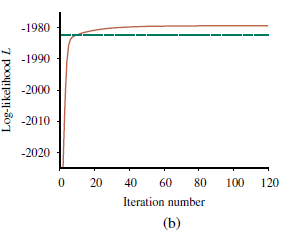
Oznacza to, że aktualizacja poprawia samo prawdopodobieństwo około e23 ≈ 1010. Przy dziesiątej iteracji wyuczony model jest lepiej dopasowany niż model oryginalny (L= -1982.214). Następnie postęp staje się bardzo powolny. Nie jest to rzadkością w przypadku EM, a wiele praktycznych systemów łączy EM z algorytmem gradientowym, takim jak Newton-Raphson w ostatniej fazie uczenia się. Ogólna lekcja z tego przykładu jest taka, że aktualizacje parametrów dla uczenia sieci bayesowskiej z ukrytymi zmiennymi są bezpośrednio dostępne z wyników wnioskowania na każdym przykładzie. Ponadto dla każdego parametru potrzebne są tylko lokalne prawdopodobieństwa a posteriori. Tutaj „lokalny” oznacza, że tablicę prawdopodobieństwa warunkowego (CPT) dla każdej zmiennej Xi można nauczyć się z prawdopodobieństw a posteriori obejmujących tylko Xi i jego rodziców Ui. Definiując θijk jako parametr CPT P(Xi=xij |Ui=uik), aktualizacja jest podawana przez znormalizowane oczekiwane liczby w następujący sposób:
![]()
Oczekiwane liczby uzyskuje się przez zsumowanie przykładów, obliczenie prawdopodobieństw P(Xi=xij,Ui=uik) dla każdego przy użyciu dowolnego algorytmu wnioskowania sieci Bayesa. W przypadku dokładnych algorytmów – w tym eliminacji zmiennych – wszystkie te prawdopodobieństwa można uzyskać bezpośrednio jako produkt uboczny standardowego wnioskowania, bez konieczności wykonywania dodatkowych obliczeń związanych z uczeniem się. Ponadto informacje potrzebne do nauki są dostępne lokalnie dla każdego parametru. Cofając się trochę, możemy pomyśleć o tym, co robi algorytm EM w tym przykładzie jako odzyskiwanie siedmiu parametrów ( θ, θF1, θW1 , θH1, θF2 , θW2, θH2) z siedmiu (23 -1) obserwowane liczebności w danych. (Ósma liczba jest ustalona przez fakt, że liczby sumują się do 1000). Gdyby każdy cukierek był opisany dwoma atrybutami, a nie trzema (powiedzmy, pomijając dziury), mielibyśmy pięć parametrów (θ, θF1 , θW1 , θF2 , θW2), ale tylko trzy (22-1) zaobserwowane zliczenia. W takim przypadku nie jest możliwe odzyskanie masy mieszanki lub właściwości dwóch zmieszanych ze sobą worków. Mówimy, że model dwuatrybutowy nie jest identyfikowalny. Identyfikowalność w sieciach bayesowskich to trudna kwestia. Zauważ, że nawet przy trzech atrybutach i siedmiu zliczeniach nie możemy jednoznacznie odtworzyć modelu, ponieważ istnieją dwa obserwacyjnie równoważne modele z odwróconą zmienną Bag. W zależności od tego, jak parametry są inicjowane, EM zbiegnie się albo do modelu, w którym torebka 1 zawiera głównie wiśnie, a torebka 2 głównie limonkę, lub odwrotnie. Tego rodzaju, jeśli nieidentyfikowalność jest nieunikniona w przypadku zmiennych, które nigdy nie są obserwowane.