https://aie24.pl/
Wspomnieliśmy , że obraz nie może być traktowany jako prosty wektor wejściowych wartości pikseli, głównie dlatego, że sąsiedztwo pikseli naprawdę ma znaczenie. Gdybyśmy mieli skonstruować sieć z całkowicie połączonymi warstwami i obrazem jako danymi wejściowymi, uzyskalibyśmy ten sam wynik, niezależnie od tego, czy trenowaliśmy z niezakłóconymi obrazami, czy z obrazami, których wszystkie piksele zostały losowo permutowane. Ponadto załóżmy, że w pierwszej warstwie ukrytej, do której piksele dostarczają dane wejściowe, znajduje się n pikseli i n jednostek. Jeśli wejście i pierwsza warstwa ukryta są w pełni połączone, oznacza to n2 wag; dla typowego megapikselowego obrazu RGB to 9 bilionów wag. Tak duża przestrzeń parametrów wymagałaby odpowiednio dużej liczby obrazów uczących i ogromnego budżetu obliczeniowego do uruchomienia algorytmu uczącego. Te rozważania sugerują, że powinniśmy skonstruować pierwszą ukrytą warstwę tak, aby każda ukryta jednostka J otrzymywała dane wejściowe tylko z małego, lokalnego obszaru obrazu. To zabija dwie pieczenie na jednym ogniu. Po pierwsze, szanuje sąsiedztwo, przynajmniej lokalnie. (I zobaczymy później, że jeśli kolejne warstwy mają tę samą właściwość lokalności, to sieć będzie respektować sąsiedztwo w sensie globalnym.) Po drugie, zmniejsza liczbę wag: jeśli każdy lokalny region ma l << n pikseli, to będzie w sumie l<<n2 wag. Na razie w porządku. Brakuje nam jednak innej ważnej właściwości obrazów: z grubsza mówiąc, wszystko, co można wykryć w jednym małym, lokalnym obszarze obrazu – na przykład oko lub źdźbło trawy – wyglądałoby tak samo, gdyby pojawiło się w innym małym, lokalnym obszarze Obraz. Innymi słowy, oczekujemy, że dane obrazu będą wykazywać przybliżoną niezmienność przestrzenną, przynajmniej w małej lub średniej skali. Niekoniecznie oczekujemy, że górne połowy zdjęć będą wyglądać jak dolne połowy, więc istnieje skala, poza którą niezmienność przestrzenna nie dłużej trzyma. Lokalną niezmienność przestrzenną można osiągnąć ograniczając wagi l łączące region lokalny z jednostką w warstwie ukrytej, tak aby były takie same dla każdej jednostki ukrytej. (Oznacza to, że dla jednostek ukrytych i oraz j wagi w1,i; … ,wl,i są takie same jak w1,j…,wl, j.) Dzięki temu jednostki ukryte stają się detektorami cech, które wykryj tę samą funkcję wszędzie tam, gdzie pojawia się na obrazie. Zazwyczaj chcemy, aby pierwsza warstwa ukryta wykrywała wiele rodzajów funkcji, a nie tylko jedną; więc dla każdego lokalnego regionu obrazu możemy mieć d ukrytych jednostek zd różnymi zestawami wag. Oznacza to, że we wszystkich występują wagi dl – liczba, która jest nie tylko znacznie mniejsza niż n2, ale w rzeczywistości jest niezależna od n, rozmiaru obrazu. W ten sposób, wstrzykując pewną wcześniejszą wiedzę — mianowicie wiedzę o sąsiedztwie i niezmienności przestrzennej — możemy opracować modele, które mają znacznie mniej parametrów i mogą się uczyć znacznie szybciej. Konwolucyjna sieć neuronowa (CNN) to taka, która zawiera przestrzennie lokalne połączenia, przynajmniej we wczesnych warstwach, i ma wzorce wag, które są replikowane w jednostkach w każdej warstwie. Wzorzec wag, który jest replikowany w wielu regionach lokalnych, nazywa się jądrem, a proces nakładania jądra na piksele obrazu (lub przestrzennie zorganizowane jednostki w kolejnej warstwie) nazywa się splotem. Jądra i sploty najłatwiej zilustrować w jednym wymiarze, a nie w dwóch lub więcej, więc przyjmiemy wektor wejściowy x o rozmiarze n, odpowiadający n pikselom na obrazie jednowymiarowym, oraz jądro wektora k o rozmiarze l. (Dla uproszczenia założymy, że l jest liczbą nieparzystą.) Wszystkie idee przenoszą się bezpośrednio do przypadków wyższych wymiarów. Operację splotu zapisujemy za pomocą symbolu * , na przykład: z = x* k. Operacja jest zdefiniowana w następujący sposób:
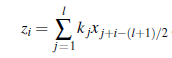
Innymi słowy, dla każdej pozycji wyjściowej i, bierzemy iloczyn skalarny między jądrem k a fragmentem x wyśrodkowanym na xi o szerokości l. Proces zilustrowano na rysunku 22.4 dla wektora jądra [+1;-1;+1], który wykrywa ciemniejszy punkt na obrazie 1D. (Wersja 2D może wykryć ciemniejszą linię.) Zauważ, że w tym przykładzie piksele, na których wyśrodkowane są jądra, są oddzielone odległością 2 pikseli; mówimy, że jądro jest stosowane z krokiem s=2. Zauważ, że warstwa wyjściowa ma mniej pikseli: z powodu kroku liczba pikseli zmniejsza się z n do mniej więcej n/s. (W dwóch wymiarach liczba pikseli wynosiłaby mniej więcej n/sxsy, gdzie sx i sy to kroki w kierunkach x i y na obrazie). Mówimy „w przybliżeniu” z powodu tego, co dzieje się na krawędzi obrazu: na rysunku splot zatrzymuje się na krawędziach obrazu, ale można również uzupełnić wejście dodatkowymi pikselami (zerami lub kopiami zewnętrznych pikseli), aby jądro mogło być zastosowane dokładnie [n/=s] razy.
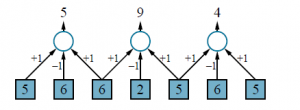
W przypadku małych jąder zazwyczaj używamy s=1, więc dane wyjściowe mają takie same wymiary jak obraz . Operacja nakładania jądra na obraz może być zaimplementowana w oczywisty sposób przez program z odpowiednimi zagnieżdżonymi pętlami; ale może być również sformułowana jako pojedyncza operacja macierzowa, tak jak zastosowanie macierzy wag w równaniu . Na przykład splot przedstawiony na rysunku można postrzegać jako następujące mnożenie macierzy:
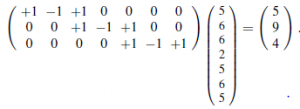
W tej macierzy wag jądro pojawia się w każdym wierszu, przesunięte zgodnie z krokiem względem poprzedniego wiersza. Niekoniecznie trzeba jawnie skonstruować macierz wag — w końcu są to głównie zera — ale fakt, że splot jest liniowy Operacja macierzowa służy jako przypomnienie, że gradient można łatwo i skutecznie zastosować do CNN, tak samo jak do zwykłych sieci neuronowych. Jak wspomniano wcześniej, będzie d jąder, a nie tylko jeden; więc przy kroku równym 1 wynik będzie d razy większy. Oznacza to, że dwuwymiarowa tablica wejściowa staje się trójwymiarową tablicą ukrytych jednostek, gdzie trzeci wymiar ma rozmiar d. Ważne jest zorganizowanie warstwy ukrytej w ten sposób, aby wszystkie dane wyjściowe jądra z określonej lokalizacji obrazu pozostały powiązane z tą lokalizacją. Jednak w przeciwieństwie do wymiarów przestrzennych obrazu ten dodatkowy „wymiar jądra” nie ma żadnych właściwości sąsiedztwa, więc nie ma sensu przeprowadzać wzdłuż niego splotów. CNN zostały pierwotnie zainspirowane modelami kory wzrokowej zakorzenionymi w neuronauce. W tych modelach pole receptywne neuronu jest częścią bodźców czuciowych, które mogą wpływać na aktywację tego neuronu. W CNN pole receptywne jednostki w pierwszej ukrytej warstwie jest małe — tylko rozmiar jądra, tj. l pikseli. W głębszych warstwach sieci może być znacznie większy. Rysunek ilustruje to dla jednostki w drugiej warstwie ukrytej, której pole receptywne zawiera pięć pikseli
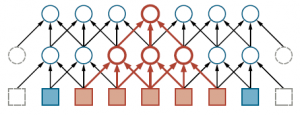
Gdy krok wynosi 1, jak na rysunku, węzeł w m-tej warstwie ukrytej będzie miał pole receptywne o rozmiarze (l -1)m+1; więc wzrost jest liniowy wm. (W obrazie 2D każdy wymiar pola receptywnego rośnie liniowo z m, więc obszar rośnie kwadratowo.) Gdy krok jest większy niż 1, każdy piksel w warstwie m reprezentuje s pikseli w warstwie m-1; dlatego pole receptywne rośnie jako O(lsm) – to znaczy wykładniczo wraz z głębokością. Ten sam efekt występuje w przypadku warstw puli, które omówimy dalej.