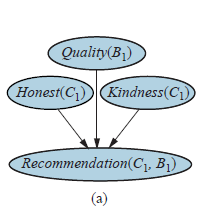
Zacznijmy od prostego przykładu: załóżmy, że sprzedawca książek online chciałby przedstawić ogólną ocenę produktów na podstawie rekomendacji otrzymanych od swoich klientów. Ocena przybierze formę późniejszego rozkładu jakości książki, biorąc pod uwagę dostępne dowody. Najprostszym rozwiązaniem jest oparcie oceny na średniej rekomendacji, być może z wariancją determinowaną liczbą rekomendacji, ale nie uwzględnia to faktu, że niektórzy klienci są życzliwsi od innych, a niektórzy mniej uczciwi niż inni. Uprzejmi klienci zwykle dają wysokie rekomendacje nawet dość przeciętnym książkom, podczas gdy nieuczciwi klienci dają bardzo wysokie lub bardzo niskie rekomendacje z powodów innych niż jakość — mogą być opłacani za promowanie niektórych książek wydawców. Dla pojedynczego klienta C1 polecającego pojedynczą książkę B1, sieć Bayesa może wyglądać jak ta pokazana na rysunku (a).
(Wyrażenia z nawiasami, takie jak Honest(C1), są po prostu fantazyjnymi symbolami – w tym przypadku fantazyjnymi nazwami zmiennych losowych.) Z dwoma klientami i dwiema książkami, sieć Bayesa wygląda jak ta na rysunku 18.2( b). W przypadku większej liczby książek i klientów ręczne określanie sieci Bayesa jest dość niepraktyczne. Na szczęście sieć ma dużo powtarzalnej struktury. Każda zmienna Rekomendacja(c;b) ma rodzicami zmienne Honest(c), Kindness(c) i Quality(b). Co więcej, tabele prawdopodobieństwa warunkowego (CPT) dla wszystkich zmiennych Rekomendacja(c;b) są identyczne, podobnie jak te dla wszystkich zmiennych Honest(c) i tak dalej. Sytuacja wydaje się być dostosowana do języka pierwszego rzędu. Chcielibyśmy powiedzieć coś w stylu
Rekomendacja(c;b) ~ RecCPT(Uczciwy(c);Uprzejmość(c);Jakość(b))
co oznacza, że rekomendacja książki przez klienta zależy prawdopodobnie od uczciwości i życzliwości klienta oraz jakości książki według ustalonego CPT. Podobnie jak logika pierwszego rzędu, RPM mają symbole stałych, funkcji i predykatów. Przyjmiemy również sygnaturę typu dla każdej funkcji — to znaczy specyfikację typu każdego argumentu i wartości funkcji. (Jeżeli znany jest typ każdego obiektu, wiele fałszywych możliwych światów jest eliminowanych przez ten mechanizm; na przykład nie musimy się martwić o życzliwość każdej książki, książki polecające klientów itd.) W przypadku domeny rekomendacji książek, typy to Klient i Książka, a sygnatury typów dla funkcji i predykatów są następujące:
Uczciwy : Klient -> {true; false}
Życzliwość: Klient-> {1,2,3,4,5}
Jakość : Książka -> {1,2,3,4,5}
Rekomendacja: Księga x Klienta -> {1;2;3;4;5}
Symbolami stałymi będą wszystkie nazwy klientów i książek, które pojawiają się w zestawie danych sprzedawcy. W przykładzie przedstawionym na rysunku (b) były to C1, C2 i B1, B2.
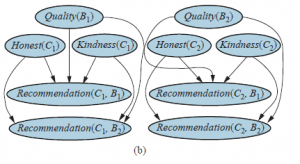
Biorąc pod uwagę stałe i ich typy, wraz z funkcjami i ich sygnaturami typów, podstawowe zmienne losowe RPM uzyskuje się poprzez utworzenie instancji każdej funkcji z każdą możliwą kombinacją obiektów. W przypadku modelu rekomendacji książek podstawowe zmienne losowe obejmują Uczciwość(C1), Jakość(B2), Rekomendację(C1,B2) i tak dalej. Są to dokładnie te zmienne, które pojawiają się na rysunku (b). Ponieważ każdy typ ma tylko skończenie wiele instancji (dzięki założeniu domknięcia domeny), liczba podstawowych zmiennych losowych również jest skończona. Aby ukończyć RPM, musimy napisać zależności, które rządzą tymi zmiennymi losowymi. Dla każdej funkcji istnieje jedna instrukcja zależności, gdzie każdy argument funkcji jest zmienną logiczną (tj. zmienną, która obejmuje obiekty, jak w logice pierwszego rzędu). Na przykład poniższa zależność stwierdza, że dla każdego klienta c prawdopodobieństwo a priori uczciwości wynosi 0,99 prawdziwe, a 0,01 fałszywe:
Uczciwy(c) ~ <0:99;0:01>
Podobnie możemy określić wcześniejsze prawdopodobieństwa wartości życzliwości każdego klienta i jakości każdej książki, każde w skali 1-5:
Życzliwość(c) ~ <0:1;0:1;0:2;0:3;0:3>
Jakość(b) ~ <0:05;0:2;0:4;0:2;0:15>
Na koniec potrzebujemy zależności dla rekomendacji: dla każdego klienta c i książki b wynik zależy od uczciwości i życzliwości klienta oraz jakości książki: Rekomendacja(c;b) RecCPT(Honest(c); Kindness (c); Jakość(b)) gdzie RecCPT jest oddzielnie zdefiniowaną tabelą prawdopodobieństwa warunkowego z 2 x 5 x 5=50 wierszami, każdy z 5 wpisami. Dla ilustracji przyjmiemy, że uczciwa rekomendacja książki o jakości q od osoby życzliwej k jest równomiernie rozłożona w zakresie
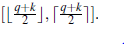
Semantykę RPM można uzyskać przez utworzenie instancji tych zależności dla wszystkich znanych stałych, dając sieć bayesowską (jak na rysunku (b)), która definiuje łączny rozkład zmiennych losowych RPM. Zbiór światów możliwych jest iloczynem kartezjańskim zakresów wszystkich podstawowych zmiennych losowych i, podobnie jak w przypadku sieci bayesowskich, prawdopodobieństwo dla każdego świata możliwego jest iloczynem odpowiednich prawdopodobieństw warunkowych z modelu. W przypadku klientów C i książek B istnieją zmienne C Honest, C Kindness, zmienne jakości B i zmienne rekomendacji BC, prowadzące do możliwych światów 2C5C+B+BC. Z dziesięcioma milionami książek i miliardem klientów to około 107×1015 światów. Dzięki wyrazistej sile RPM, kompletny model prawdopodobieństwa nadal ma tylko mniej niż 300 parametrów – większość z nich znajduje się w tabeli RecCPT. Możemy udoskonalić model poprzez zapewnienie niezależności zależnej od kontekstu ( aby odzwierciedlić fakt, że nieuczciwi klienci ignorują jakość podczas wydawania rekomendacji; ponadto życzliwość nie odgrywa żadnej roli w ich decyzjach. Zatem Rekomendacja(c;b) jest niezależna od Uprzejmości(c) i Jakości(b), gdy Uczciwy(c)=false:
Rekomendacja(c;b) ~ jeśli Uczciwy(c) to
UczciwyRecCPT (życzliwość (c); jakość (b))
w przeciwnym razie <0.4,0.1,0.0,0.1,0.4> :
Ten rodzaj zależności może wyglądać jak zwykła instrukcja if-then-else w języku programowania, ale istnieje kluczowa różnica: silnik wnioskowania niekoniecznie zna wartość testu warunkowego, ponieważ Honest(c) jest zmienną losową . Możemy rozwijać ten model na nieskończone sposoby, aby był bardziej realistyczny. Załóżmy na przykład, że uczciwy klient, który jest fanem autora książki, zawsze daje książce 5, niezależnie od jakości:
Rekomendacja(c;b) ~ jeśli Uczciwy(c) to
jeśli Fan(c;Autor(b)) to Dokładnie(5)
w przeciwnym razie HonestRecCPT (życzliwość (c); jakość (b))
w przeciwnym razie <0.4,0.1,0.0,0.1,0.4>
Ponownie, test warunkowy Fan(c;Autor(b)) jest nieznany, ale jeśli klient daje tylko 5s książkom konkretnego autora i nie jest poza tym szczególnie uprzejmy, wtedy prawdopodobieństwo późniejszego, że klient jest fanem tego autora będzie być na haju. Ponadto dystrybucja a posteriori będzie miała tendencję do dyskontowania 5 klientów w ocenie jakości książek tego autora. W tym przykładzie domyślnie założyliśmy, że wartość Autor(b) jest znana dla każdego b, ale może tak nie być. Jak system może uzasadnić, czy, powiedzmy, C1 jest fanem Autora(B2), gdy Autor(B2) jest nieznany? Odpowiedź brzmi, że system może być zmuszony do uzasadnienia wszystkich możliwych autorów. Załóżmy (dla uproszczenia), że jest tylko dwóch autorów, A1 i A2. Wtedy Autor(B2) jest zmienną losową z dwiema możliwymi wartościami, A1 i A2 i jest rodzicem Rekomendacji(C1,B2). Zmienne Fan(C1,A1) i Fan(C1,A2) są też rodzicami. Rozkład warunkowy dla Rekomendacji(C1,B2) jest zatem zasadniczo multiplekserem, w którym rodzic Author(B2) działa jako selektor, aby wybrać, który z Fan(C1 ,A1) i Fan(C1,A2) faktycznie ma wpływ na rekomendację . Niepewność wartości Author(B2), która wpływa na strukturę zależności sieci, jest przykładem niepewności relacyjnej. Jeśli zastanawiasz się, w jaki sposób system może ustalić, kto jest Author(B2), rozważ możliwość, że trzech innych klientów jest fanami A1 (i nie ma innych wspólnych ulubionych autorów) i wszyscy trzej przyznali B2 ocenę 5, mimo że większość innych klientów uważa to za dość ponure. W takim przypadku jest bardzo prawdopodobne, że autorem B2 jest A1. Pojawienie się tak wyrafinowanego rozumowania z zaledwie kilku linijek modelu RPM jest intrygującym przykładem tego, jak probabilistyczne wpływy rozprzestrzeniają się poprzez sieć powiązań między obiektami w modelu. W miarę dodawania większej liczby zależności i większej liczby obiektów obraz przekazywany przez rozkład a posteriori często staje się coraz wyraźniejszy.