Problem asocjacji danych był pierwotnie badany w kontekście śledzenia radarowego wielu celów, gdzie odbite impulsy są wykrywane w stałych odstępach czasu przez obracającą się antenę radaru. W każdym kroku czasowym na ekranie może pojawić się wiele impulsów, ale nie ma bezpośredniej obserwacji, które impulsy w czasie t odpowiadają którym impulsom w czasie t -1. Rysunek 18.8(a) pokazuje prosty przykład z dwoma skokami na krok czasowy dla pięciu kroków. Każdy impuls jest oznaczony swoim krokiem czasowym, ale nie zawiera żadnych informacji identyfikujących. Załóżmy na razie, że wiemy, że dokładnie dwa samoloty, A1 i A2, generują impulsy. W terminologii OUPM, A1 i A2 są gwarantowanymi obiektami, co oznacza, że gwarantuje się ich istnienie i odrębność; ponadto w tym przypadku nie ma innych obiektów. (Innymi słowy, jeśli chodzi o samoloty, ten scenariusz jest zgodny z semantyką bazy danych założoną w obrotach na minutę.) Niech ich prawdziwe pozycje to X(A1, t) i X(A2, t), gdzie t jest nieujemną liczbą całkowitą indeksuje czasy aktualizacji czujnika. Zakładamy, że pierwsza obserwacja dociera do t=1, a w czasie 0 wcześniejszy rozkład dla lokalizacji każdego samolotu to InitX(). Aby uprościć sprawę, założymy również, że każdy samolot porusza się niezależnie, zgodnie ze znanym modelem przejściowym – np. liniowym – modelem gaussowskim używanym w filtrze Kalmana. Ostatnim elementem jest model czujnika: ponownie zakładamy model liniowo – gaussowski, w którym samolot w pozycji x wytwarza blip b, którego obserwowana pozycja blipu Z(b) jest liniową funkcją x z dodanym szumem gaussowskim. Każdy samolot generuje dokładnie jeden impuls w każdym kroku czasowym, więc impuls ma za początek samolot i krok czasowy. Tak więc, pomijając na razie poprzedni, model wygląda tak:
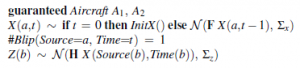
gdzie F i Σx są macierzami opisującymi model przejścia liniowego i kowariancją szumu przejścia, a H i Σz są odpowiednimi macierzami dla modelu czujnika. Kluczową różnicą między tym modelem a standardowym filtrem Kalmana jest to, że istnieją dwa obiekty generujące odczyty czujnika (blips). Oznacza to, że w danym kroku czasowym istnieje niepewność co do tego, który obiekt wytworzył dany odczyt czujnika. Każdy możliwy świat w tym modelu zawiera asocjację – zdefiniowaną przez wartości wszystkich zmiennych Source(b) dla wszystkich kroków czasowych – między samolotem a impulsami. Dwie możliwe hipotezy asocjacyjne przedstawiono na rysunku (b–c).
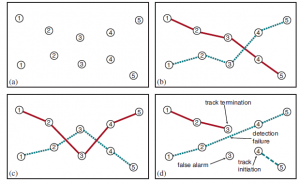
Ogólnie rzecz biorąc, dla n obiektów i T przedziałów czasowych istnieje (n!)T sposobów przypisywania impulsów do samolotów – strasznie duża liczba. Opisany dotychczas scenariusz obejmował n znanych obiektów generujących n obserwacji w każdym kroku czasowym. Rzeczywiste zastosowania asocjacji danych są zazwyczaj znacznie bardziej skomplikowane. Często zgłaszane obserwacje zawierają fałszywe alarmy (znane również jako bałagan), które nie są spowodowane przez rzeczywiste obiekty. Mogą wystąpić błędy wykrywania, co oznacza, że nie zostanie zgłoszona żadna obserwacja Bałagan dla rzeczywistego obiektu. W końcu pojawiają się nowe obiekty, a stare znikają. Zjawiska te, które tworzą jeszcze więcej możliwych światów, o które można się martwić, zostały zilustrowane na rysunku (d). Odpowiednia jednostka OUPM jest pokazana na rysunku

Ze względu na jego praktyczne znaczenie zarówno dla zastosowań cywilnych, jak i wojskowych, napisano dziesiątki tysięcy artykułów na temat problemu śledzenia wielu celów i kojarzenia danych. Wielu z nich po prostu próbuje opracować złożone matematyczne szczegóły obliczeń prawdopodobieństwa dla modelu z rysunku 18.9 lub dla jego prostszych wersji. W pewnym sensie jest to niepotrzebne, gdy model jest wyrażony w probabilistycznym języku programowania, ponieważ silnik wnioskowania ogólnego przeznaczenia wykonuje wszystkie obliczenia matematyczne poprawnie dla dowolnego modelu – w tym tego. Co więcej, opracowanie scenariusza (latanie formacji, obiekty zmierzające do nieznanych miejsc docelowych, obiekty startujące lub lądujące itp.) mogą być obsługiwane przez niewielkie zmiany w modelu bez uciekania się do nowych wyprowadzeń matematycznych i skomplikowanego programowania. Z praktycznego punktu widzenia wyzwaniem z tego rodzaju modelem jest złożoność wnioskowania. Podobnie jak w przypadku wszystkich modeli prawdopodobieństwa, wnioskowanie oznacza sumowanie zmiennych innych niż zapytanie i dowody. Do filtrowania w HMM i DBN byliśmy w stanie zsumować zmienne stanu od 1 do t-1 za pomocą prostej sztuczki programowania dynamicznego; w przypadku filtrów Kalmana wykorzystaliśmy również specjalne właściwości Gaussa. Jeśli chodzi o powiązanie danych, mamy mniej szczęścia. Nie ma (znanego) wydajnego dokładnego algorytmu, z tego samego powodu, dla którego nie ma żadnego dla przełączania filtru Kalmana: rozkład filtrowania, który opisuje łączny rozkład liczby i lokalizacji samolotów na każdym kroku czasowym, kończy się jako mieszanina wykładniczo wiele rozkładów, po jednym dla każdego sposobu wybierania sekwencji obserwacji do przypisania do każdego statku powietrznego. W odpowiedzi na złożoność wnioskowania dokładnego zastosowano kilka metod przybliżonych. Najprostszym podejściem jest wybranie jednego „najlepszego” przypisania w każdym kroku czasowym, biorąc pod uwagę przewidywane pozycje obiektów w bieżącym czasie. To przypisanie wiąże obserwacje z obiektami i umożliwia aktualizację śladu każdego obiektu oraz wykonanie prognozy dla następnego kroku czasowego. Do wyboru „najlepszego” przypisania często stosuje się tak zwany filtr najbliższego sąsiada, który wielokrotnie wybiera najbliższą parę przewidywanej pozycji lter i obserwacji i dodaje tę parę do przypisania. Filtr najbliższego sąsiedztwa działa dobrze, gdy obiekty są dobrze rozdzielone w przestrzeni stanów, a niepewność predykcji i błąd obserwacji są małe – innymi słowy, gdy nie ma możliwości pomyłki. Gdy istnieje większa niepewność co do prawidłowego przypisania, lepszym podejściem jest wybór przypisania, które maksymalizuje łączne prawdopodobieństwo bieżących obserwacji, biorąc pod uwagę przewidywane pozycje. Można to zrobić wydajnie za pomocą algorytmu węgierskiego (Kuhn, 1955), mimo że jest n! zadania do wyboru, gdy nadejdzie każdy nowy przedział czasowy. Każda metoda, która zobowiązuje do jednego najlepszego przypisania w każdym kroku czasowym, sromotnie zawodzi w trudniejszych warunkach. W szczególności, jeśli algorytm dokona nieprawidłowego przypisania, przewidywanie w następnym kroku czasowym może być znacząco błędne, prowadząc do większej liczby nieprawidłowych przypisań i tak dalej. Podejścia do próbkowania mogą być znacznie bardziej efektywne. Algorytm filtrowania cząstek do powiązania danych działa poprzez utrzymywanie dużego zbioru możliwych bieżących przypisań. Algorytm MCMC bada przestrzeń historii przypisania — na przykład rysunek (b–c) może być stanami w przestrzeni stanów MCMC — i może zmienić zdanie na temat poprzednich decyzji przypisania. Jednym z oczywistych sposobów na przyspieszenie wnioskowania opartego na próbkowaniu dla śledzenia wielocelowego jest użycie sztuczki Rao-Blackwellization z rozdziału 14 (strona 514): biorąc pod uwagę konkretną hipotezę asocjacji dla wszystkich obiektów, obliczenia filtrowania dla każdego obiektu można zazwyczaj wykonać dokładnie i wydajnie, zamiast próbkowania wielu możliwych sekwencji stanów dla obiektów. Na przykład w modelu z rysunku 18.9 obliczenia filtrowania oznaczają po prostu uruchomienie filtru Kalmana dla sekwencji obserwacji przypisanych do danego hipotetycznego obiektu. Co więcej, przy przejściu z jednej hipotezy asocjacyjnej na inną, obliczenia muszą być powtórzone tylko dla obiektów, których skojarzone obserwacje uległy zmianie. Obecne metody asocjacji danych MCMC mogą obsługiwać wiele setek obiektów w czasie rzeczywistym, dając jednocześnie dobre przybliżenie prawdziwych rozkładów a posteriori.


