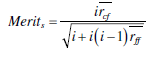Zastosujmy ten model do interpretacji obrazów liter, które zostały zdegradowane za pomocą szumu addytywnego. Rysunek przedstawia obraz zdegradowany wraz z wynikami z trzech niezależnych przebiegów MCMC.

Dla każdego przebiegu pokazujemy renderowanie liter zawartych w śladzie po zatrzymaniu łańcucha Markowa. We wszystkich trzech przypadkach wynikiem jest niepewność sekwencji liter, co sugeruje, że rozkład a posteriori jest silnie skoncentrowany na prawidłowej interpretacji.
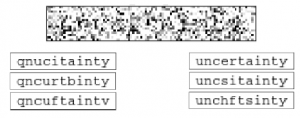
Teraz zdegradujmy tekst jeszcze bardziej, zamazując go na tyle, że trudno go przeczytać. Rysunek przedstawia wyniki wnioskowania na tym trudniejszym wejściu.

Tym razem, chociaż wydaje się, że wnioskowanie MCMC zbiegło się na (jak wiemy) prawidłowej liczbie liter, pierwsza litera jest błędnie identyfikowana jako q i nie ma pewności co do pięciu z dziesięciu kolejnych liter. W tym momencie istnieje wiele możliwych sposobów interpretacji wyników. Możliwe, że wnioskowanie MCMC dobrze się wymieszało, a wyniki są dobrym odzwierciedleniem prawdziwego a posteriori, biorąc pod uwagę model i obraz; w takim przypadku niepewność niektórych liter i błąd w pierwszej literze są nieuniknione. Aby uzyskać lepsze wyniki, może być konieczne ulepszenie modelu tekstowego lub zmniejszenie poziomu szumu. Możliwe też, że wnioskowanie MCMC nie zostało prawidłowo wymieszane: jeśli uruchomimy 300 łańcuchów dla 25 tysięcy lub 25 milionów iteracji, możemy znaleźć całkiem inny rozkład wyników, być może wskazujący, że pierwszą literą jest prawdopodobnie u, a nie q. Prowadzenie większej liczby wniosków może być kosztowne pod względem pieniędzy i czasu oczekiwania. Co więcej, nie ma niezawodnego testu na zbieżność metod wnioskowania Monte Carlo. Moglibyśmy spróbować ulepszyć algorytm wnioskowania, być może projektując lepszy rozkład propozycji dla MCMC lub używając wskazówek oddolnych z obrazu, aby sugerować lepsze początkowe hipotezy. Te ulepszenia wymagają dodatkowego przemyślenia, implementacji i debugowania. Trzecią alternatywą jest ulepszenie modelu. Na przykład moglibyśmy włączyć wiedzę o angielskich słowach, taką jak prawdopodobieństwa par liter. Rozważamy teraz tę opcję.