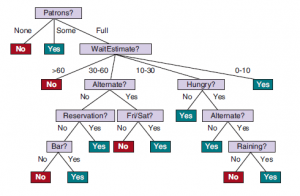
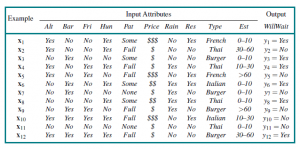
Bardziej formalnie, zadaniem nadzorowanego uczenia się jest:
Mając zestaw uczący N przykładowych par wejście-wyjście
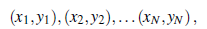
gdzie każda para została wygenerowana przez nieznaną funkcję y = f (x), odkrywa funkcję h, która przybliża prawdziwą funkcję f . Funkcja h nazywana jest hipotezą o świecie. Jest ona wyprowadzona z przestrzeni hipotez H możliwych funkcji. Na przykład przestrzeń hipotez może być zbiorem wielomianów stopnia 3; lub zestaw funkcji JavaScript; lub zestaw formuł logicznych 3-SAT Boolean. Za pomocą alternatywnego słownictwa możemy powiedzieć, że h jest modelem danych, narysowanym z klasy modelu H, lub możemy powiedzieć, że funkcją narysowaną z klasy funkcji. Wynik yi nazywamy podstawową prawdą – prawdziwą odpowiedzią, o którą prosimy nasz model. Jak wybieramy przestrzeń hipotezy? Możemy mieć wcześniejszą wiedzę na temat procesu, który wygenerował dane. Jeśli nie, możemy przeprowadzić eksploracyjną analizę danych: badanie danych za pomocą testów statystycznych i wizualizacji – histogramów, wykresów punktowych, wykresów skrzynkowych – aby poznać dane i uzyskać wgląd w to, jaka przestrzeń hipotez może być odpowiednia. Lub możemy po prostu wypróbować wiele przestrzeni hipotez i ocenić, która z nich działa najlepiej. Jak wybrać dobrą hipotezę z przestrzeni hipotez? Moglibyśmy mieć nadzieję na spójną hipotezę: h takie, że każdy xi w zbiorze uczącym ma h(xi) = yi. W przypadku wyjść o wartości ciągłej nie możemy oczekiwać dokładnego dopasowania do prawdy podstawowej; zamiast tego szukamy najlepiej dopasowanej funkcji, dla której każde h(xi) jest bliskie yi
Prawdziwą miarą hipotezy nie jest to, jak radzi sobie w zestawie uczącym, ale raczej to, jak dobrze radzi sobie z danymi wejściowymi, których jeszcze nie widziała. Możemy to ocenić za pomocą drugiej próbki par (xi,yi) zwanej zbiorem testowym. Mówimy, że h dobrze uogólnia, jeśli dokładnie przewiduje wyniki zbioru testowego.
Rysunek pokazuje, że funkcja h, którą odkrywa algorytm uczący się, zależy od przestrzeni hipotez H, którą bierze pod uwagę oraz od podanego zbioru uczącego.
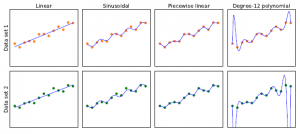
Każdy z czterech wykresów w górnym rzędzie ma ten sam zestaw uczący 13 punktów danych na płaszczyźnie (x,y). Cztery wykresy w dolnym rzędzie mają drugi zestaw 13 punktów danych; oba zbiory są reprezentatywne dla tej samej nieznanej funkcji f(x). Każda kolumna przedstawia najlepiej dopasowaną hipotezę h z innej przestrzeni hipotez:
Kolumna 1: Linie proste; funkcje postaci h(x) = w1x+w0. Nie ma linii, która byłaby spójną hipotezą dla punktów danych.
Kolumna 2: Funkcje sinusoidalne postaci h(x) = w1x+sin(w0x). Ten wybór nie jest do końca spójny, ale bardzo dobrze pasuje do obu zestawów danych.
Kolumna 3: Funkcje odcinkowo-liniowe, w których każdy segment linii łączy kropki z jednego punktu danych do następnego. Te funkcje są zawsze spójne.
Kolumna 4: Wielomiany 12 stopnia, 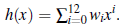 Są one spójne: zawsze możemy uzyskać wielomian stopnia 12, aby idealnie dopasować 13 różnych punktów. Ale tylko dlatego, że hipoteza jest spójna, nie oznacza, że jest to dobre przypuszczenie. Jednym ze sposobów analizowania przestrzeni hipotez jest narzucane przez nie obciążenie (niezależnie od zestawu danych uczących) i wariancja, którą wytwarzają (z jednego zestawu uczącego do drugiego). Przez stronniczość rozumiemy (luźno) tendencję hipotezy predykcyjnej do odchylania się od wartości oczekiwanej po uśrednieniu dla różnych zestawów uczących. Bias często wynika z ograniczeń narzuconych przez przestrzeń hipotez.
Są one spójne: zawsze możemy uzyskać wielomian stopnia 12, aby idealnie dopasować 13 różnych punktów. Ale tylko dlatego, że hipoteza jest spójna, nie oznacza, że jest to dobre przypuszczenie. Jednym ze sposobów analizowania przestrzeni hipotez jest narzucane przez nie obciążenie (niezależnie od zestawu danych uczących) i wariancja, którą wytwarzają (z jednego zestawu uczącego do drugiego). Przez stronniczość rozumiemy (luźno) tendencję hipotezy predykcyjnej do odchylania się od wartości oczekiwanej po uśrednieniu dla różnych zestawów uczących. Bias często wynika z ograniczeń narzuconych przez przestrzeń hipotez.
Na przykład przestrzeń hipotez funkcji liniowych wywołuje silne obciążenie: dopuszcza jedynie funkcje składające się z linii prostych. Jeśli w danych występują jakiekolwiek wzorce inne niż ogólne nachylenie linii, funkcja liniowa nie będzie w stanie przedstawić tych wzorców. Mówimy, że hipoteza jest niedostateczna, gdy nie znajduje prawidłowości w danych. Z drugiej strony, odcinkowo funkcja liniowa ma niski błąd systematyczny; kształt funkcji zależy od danych. Przez wariancję rozumiemy wielkość zmiany hipotezy z powodu fluktuacji danych uczących. Dwa wiersze na rysunku 19.1 reprezentują zestawy danych, z których każdy był próbkowany z tej samej funkcji f(x). Zestawy danych okazały się nieco inne. W przypadku pierwszych trzech kolumn niewielka różnica w zestawie danych przekłada się na niewielką różnicę w hipotezie. Nazywamy to niską wariancją. Ale wielomiany stopnia 12 w czwartej kolumnie mają dużą wariancję: spójrz, jak różne są te dwie funkcje na obu końcach osi x. Oczywiście, co najmniej jeden z tych wielomianów musi być słabym przybliżeniem do prawdziwego f(x). Mówimy, że funkcja nadmiernie dopasowuje dane, gdy zwraca zbyt dużą uwagę na konkretny zestaw danych, na którym jest trenowana, co powoduje, że działa słabo na niewidocznych danych. Często występuje kompromis między obciążeniem a wariancją: wybór między bardziej złożonymi hipotezami o niskim odchyleniu, które dobrze pasują do danych uczących, a prostszymi hipotezami o niskiej wariancji, które mogą lepiej uogólniać. Albert Einstein powiedział w 1933 r.: „Nadrzędnym celem całej teorii jest uczynienie nieredukowalnych podstawowych elementów tak prostymi i jak najmniejszymi, bez konieczności rezygnacji z adekwatnej reprezentacji pojedynczej podstawy doświadczenia”. Innymi słowy, Einstein zaleca wybór najprostszej hipotezy, która pasuje do danych. Zasadę tę można prześledzić dalej od XIV-wiecznego angielskiego filozofa Williama z Ockham2. Jego zasada, że „wielości [bytów] nie należy zakładać bez konieczności” nazywa się brzytwą Ockhama, ponieważ służy do „ogolenia” wątpliwych wyjaśnień. . Zdefiniowanie prostoty nie jest łatwe. Wydaje się jasne, że wielomian z tylko dwoma parametrami jest prostszy niż jeden z trzynastoma parametrami. Która hipoteza jest najlepsza na rysunku? Nie możemy być pewni. Gdybyśmy wiedzieli, że dane reprezentują, powiedzmy, liczbę wejść na stronę internetową, która rośnie z dnia na dzień, ale także cykli w zależności od pory dnia, moglibyśmy faworyzować funkcję sinusoidalną. Gdybyśmy wiedzieli, że dane na pewno nie są cykliczne, ale mają wysoki poziom szumu, faworyzuje to funkcję liniową. W niektórych przypadkach analityk jest skłonny powiedzieć nie tylko, że hipoteza jest możliwa lub niemożliwa, ale raczej, jak bardzo jest prawdopodobna. Uczenie nadzorowane można przeprowadzić wybierając hipotezę h*, która jest najbardziej prawdopodobna, biorąc pod uwagę dane:
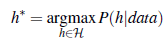
Zgodnie z regułą Bayesa jest to równoznaczne z
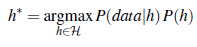
Następnie możemy powiedzieć, że prawdopodobieństwo a priori P(h) jest wysokie dla gładkiego wielomianu stopnia 1 lub -2 i niższe dla wielomianu stopnia 12 z dużymi, ostrymi skokami. Zezwalamy na nietypowo wyglądające funkcje, gdy dane mówią, że naprawdę ich potrzebujemy, ale odradzamy je, dając im niskie prawdopodobieństwo a priori. Dlaczego nie pozwolić, aby H było klasą wszystkich programów komputerowych lub wszystkich maszyn Turinga? Problem I polega na tym, że istnieje kompromis między ekspresywnością przestrzeni hipotez a złożonością obliczeniową znalezienia dobrej hipotezy w tej przestrzeni. Na przykład dopasowanie linii prostej do danych jest łatwym obliczeniem; dopasowanie wielomianów wysokiego stopnia jest nieco trudniejsze; a montaż maszyn Turinga jest nierozstrzygnięty. Drugim powodem preferowania prostych przestrzeni hipotez jest to, że prawdopodobnie będziemy chcieli użyć h po tym, jak się go nauczymy, a obliczanie h(x), gdy h jest funkcją liniową, jest gwarantowane, aby było szybkie, podczas gdy obliczanie dowolnego programu maszyny Turinga nie jest nawet gwarantowane zakończenie. Z tych powodów większość prac nad uczeniem się skupiała na prostych reprezentacjach. W ostatnich latach pojawiło się duże zainteresowanie głębokim uczeniem, gdzie reprezentacje nie są proste, ale gdzie obliczenie h(x) nadal wymaga tylko ograniczonej liczby kroków, aby wykonać obliczenia na odpowiednim sprzęcie. Zobaczymy, że kompromis między ekspresywnością a złożonością nie jest prosty: często jest tak, jak widzieliśmy z logiką pierwszego rzędu w rozdziale 8, że język ekspresyjny umożliwia dopasowanie prostej hipotezy do danych, przy jednoczesnym ograniczeniu wyrazistość języka oznacza, że każda spójna hipoteza musi być złożona.