Opisaliśmy algorytm iteracji wartości, który oblicza jedną wartość użyteczności dla każdego stanu. Przy nieskończenie wielu stanach wiary musimy być bardziej kreatywni. Rozważ optymalną politykę π* i jej zastosowanie w określonym stanie przekonań b: polityka generuje działanie, następnie dla każdego kolejnego spostrzeżenia stan przekonania jest aktualizowany i generowane jest nowe działanie, i tak dalej. W przypadku tego konkretnego b polityka jest zatem dokładnie równoważna z planem warunkowym, dla niedeterministycznych i częściowo obserwowalnych problemów. Zamiast myśleć o zasadach, pomyślmy o planach warunkowych i o tym, jak oczekiwana użyteczność wykonania ustalonego planu warunkowego zmienia się wraz z początkowym stanem przekonań. Dokonujemy dwóch obserwacji:
1. Niech użyteczność wykonania ustalonego planu warunkowego p rozpoczynającego się w stanie fizycznym s będzie αp(s). Wtedy oczekiwana użyteczność wykonania p w stanie przekonania b jest po prostu 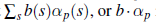
jeśli pomyślimy o nich obu jako o wektorach. Zatem oczekiwana użyteczność ustalonego planu warunkowego zmienia się liniowo z b; to znaczy, odpowiada hiperpłaszczyźnie w przestrzeni przekonań.
- W dowolnym stanie b przekonań optymalna polityka wybierze wykonanie planu warunkowego z najwyższą oczekiwaną użytecznością; a oczekiwana użyteczność b przy optymalnej polityce jest po prostu użytecznością tego planu warunkowego: U(b) = Uπ*(b) = maxpb·αp. Jeśli optymalna polityka π* zdecyduje się na wykonanie p zaczynając od b, wówczas rozsądne jest oczekiwanie, że może wybrać wykonanie p w stanach przekonań, które są bardzo bliskie b; w rzeczywistości, jeśli ograniczymy głębokość planów warunkowych, to takich planów jest tylko skończenie wiele, a ciągła przestrzeń stanów przekonań będzie generalnie podzielona na regiony, z których każdy odpowiada określonemu planowi warunkowemu, który jest optymalny w tym regionie.
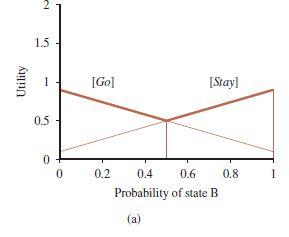
Z tych dwóch obserwacji widzimy, że funkcja użyteczności U(b) w stanach przekonań, będąca maksimum zbioru hiperpłaszczyzn, będzie odcinkowo liniowa i wypukła. Aby to zilustrować, posłużymy się prostym światem dwustanowym. Stany są oznaczone jako A i B i są dwie akcje: Stay pozostaje w miejscu z prawdopodobieństwem 0,9, a Go przełącza się do drugiego stanu z prawdopodobieństwem 0,9. Nagrodami są R (·,·, A) = 0 i R (·,·, B) = 1; oznacza to, że każde przejście kończące się na A ma nagrodę zero, a każde przejście kończące się na B ma nagrodę 1. Na razie przyjmiemy współczynnik dyskontowy γ = 1. Czujnik zgłasza prawidłowy stan z prawdopodobieństwem 0,6. Oczywiście agent powinien zostać, gdy jest w stanie B, i iść, gdy jest w stanie A. Problem w tym, że nie wie, gdzie jest! Zaletą świata dwustanowego jest to, że przestrzeń przekonań może być wizualizowana w jednym wymiarze, ponieważ dwa prawdopodobieństwa b (A) i b (B) sumują się do 1. Na rysunku (a) oś x reprezentuje stan przekonania, zdefiniowany przez b (B), prawdopodobieństwo bycia w stanie B.
Rozważmy teraz jednoetapowe plany [Stay] i [Go], z których każdy otrzymuje nagrodę za jedno przejście w następujący sposób:
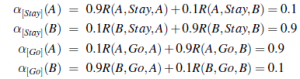
Hiperpłaszczyzny (linie, w tym przypadku) dla b·α[Stay] i b·α[Go] są pokazane na rysunku (a), a ich maksimum jest pogrubione. Pogrubiona linia reprezentuje zatem funkcję użyteczności dla problemu skończonego horyzontu, która umożliwia tylko jedno działanie, a w każdym „kawałku” odcinkowo liniowej funkcji użyteczności działaniem optymalnym jest pierwsze działanie odpowiadającego planu warunkowego. W tym przypadku optymalna jednoetapowa polityka to Pozostań, gdy b(B)> 0.5 i Idź w przeciwnym razie. Kiedy już mamy użyteczność p (s) dla wszystkich planów warunkowych p głębokości 1 w każdym stanie fizycznym s, możemy obliczyć użyteczności dla planów warunkowych o głębokości 2, biorąc pod uwagę każdą możliwą pierwszą akcję, każdą możliwą następną percepcję, a następnie każdy sposób wyboru planu głębokości-1 do wykonania dla każdej percepcji:
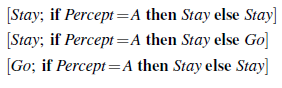
W sumie istnieje osiem odrębnych planów głębokości 2, a ich użyteczność pokazano na rysunku (b).
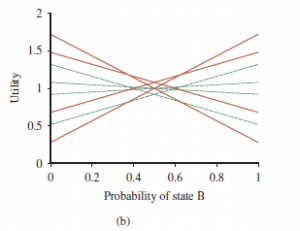
Zauważ, że cztery plany, pokazane jako linie przerywane, są nieoptymalne w całej przestrzeni przekonań – mówimy, że te plany są zdominowane i nie trzeba ich dalej rozważać. Istnieją cztery niezdominowane plany, z których każdy jest optymalny w określonym regionie, jak pokazano na rysunku (c).
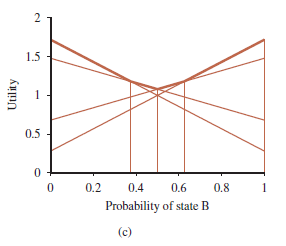
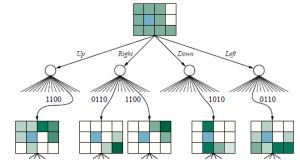
Regiony dzielą przestrzeń stanów przekonań. Powtarzamy proces dla głębokości 3 i tak dalej. Ogólnie rzecz biorąc, niech p będzie planem warunkowym o głębokości d, którego działaniem początkowym jest a i którego podplanem głębokości (d-1) dla percepcji e jest p.e; następnie
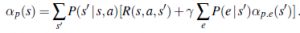
Ta rekurencja w naturalny sposób daje nam algorytm iteracji wartości, który pokazano na rysunku. Struktura algorytmu i jego analiza błędów są podobne do algorytmu iteracji wartości podstawowej na Rysunku 16.6 na stronie 563; główna różnica polega na tym, że zamiast obliczać jeden numer użyteczności dla każdego stanu, POMDP-VALUE-ITERATION utrzymuje zbiór niezdominowanych planów z ich hiperpłaszczyznami użyteczności. Złożoność algorytmu zależy przede wszystkim od tego, ile planów zostanie wygenerowanych. Biorąc pod uwagę działania |A| i możliwe obserwacje |E|, istnieją odrębne plany głębokościowe |A|O(|E|d-1). Nawet dla skromnego, dwupaństwowego świata z d = 8, to jest 2255 planów. Eliminacja planów zdominowanych jest niezbędna dla zmniejszenia tego podwójnie wykładniczego wzrostu: liczba planów niezdominowanych z d = 8 wynosi zaledwie 144. Funkcja użyteczności dla tych 144 planów jest pokazana na rysunku (d).
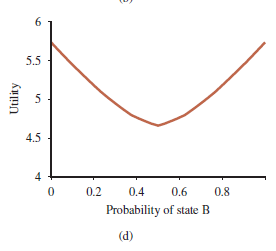
Zauważ, że pośrednie stany przekonań mają niższą wartość niż stan A i stan B, ponieważ w stanach pośrednich agentowi brakuje informacji potrzebnych do wyboru dobrego działania. Dlatego informacja ma wartość ,a optymalne polityki w POMDP często obejmują działania mające na celu gromadzenie informacji.
Mając taką funkcję użyteczności, można wyodrębnić wykonywalną politykę, sprawdzając, która hiperpłaszczyzna jest optymalna w dowolnym stanie przekonania b i wykonując pierwsze działanie odpowiadającego planu. Na rysunku (d) odpowiednia optymalna polityka jest nadal taka sama jak dla planów głębokości 1: Zostań, gdy b(B)> 0,5 i idź w przeciwnym razie. W praktyce algorytm iteracji wartości na rysunku jest beznadziejnie nieefektywny w przypadku większych problemów – nawet POMDP 4×3 jest zbyt trudny.

Głównym powodem jest to, że mając n niezdominowanych planów warunkowych na poziomie d, algorytm konstruuje plany warunkowe |A|· n|E| na poziomie d+1 przed wyeliminowaniem planów zdominowanych. Przy czujniku czterobitowym |E| wynosi 16, a n może być w setkach, więc jest to beznadziejne. Od czasu opracowania tego algorytmu w latach 70. nastąpiło kilka postępów, w tym bardziej wydajne formy iteracji wartości i różne rodzaje algorytmów iteracji polityki. Niektóre z nich omówiono w uwagach na końcu rozdziału. Jednak w przypadku ogólnych POMDP znalezienie optymalnej polityki jest bardzo trudne (w rzeczywistości trudna do PSPACE — to znaczy bardzo trudna). W następnej sekcji opisano inną, przybliżoną metodę rozwiązywania POMDP, opartą na wyszukiwaniu z wyprzedzeniem.