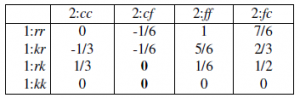
Zwróciliśmy uwagę na znaczenie projektowania systemów sztucznej inteligencji, które mogą działać w warunkach niepewności co do prawdziwego celu człowieka. Wprowadziliśmy prosty model niepewności co do własnych preferencji na przykładzie lodów o smaku duriana. Dzięki prostemu urządzeniu dodawania do modelu nowej zmiennej utajonej reprezentującej nieznane preferencje, wraz z odpowiednim modelem czujnika (np. obserwacja smaku małej próbki lodów), niepewne preferencje mogą być obsługiwane w naturalny sposób . Zbadano również problem wyłącznika: pokazaliśmy, że robot z niepewnością co do ludzkich preferencji będzie ulegał człowiekowi i pozwoli się wyłączyć. W tym problemie Robbie robot nie jest pewien preferencji Harriet człowieka, ale modelujemy decyzję Harriet (czy wyłączyć Robbiego, czy nie) jako prostą, deterministyczną konsekwencję jej własnych preferencji dotyczących działania, które proponuje Robbie. Tutaj uogólniamy ten pomysł na pełną grę dla dwóch osób, zwaną grą asystującą, w której zarówno Harriet, jak i Robbie są graczami. Zakładamy, że Harriet obserwuje własne preferencje θ i postępuje zgodnie z nimi, podczas gdy Robbie ma prawdopodobieństwo a priori P( θ ) przed preferencjami Harriet. Wypłata jest zdefiniowana przez θ i jest identyczna dla obu graczy: zarówno Harriet, jak i Robbie maksymalizują wypłatę Harriet. W ten sposób gra pomocowa dostarcza formalnego modelu idei dającej się udowodnić korzystnej sztucznej inteligencji, wprowadzonej w Rozdziale 1. Oprócz deferencyjnego zachowania wykazywanego przez Robbiego w problemie wyłączania – strategie wyłaniania się jako równowagi w ogólnych grach pomocowych obejmują działania na Część Harriet, którą opisalibyśmy jako nauczanie, nagradzanie, dowodzenie, poprawianie, demonstrowanie lub wyjaśnianie, a także działania ze strony Robbiego, które określilibyśmy jako proszenie o pozwolenie, uczenie się na pokazach, wywoływanie preferencji i tak dalej. Kluczową kwestią jest to, że te zachowania nie muszą być oskryptowane: rozwiązując grę, Harriet i Robbie opracowują sami, jak przekazać informacje o preferencjach od Harriet do Robbiego, aby Robbie mógł być bardziej użyteczny dla Harriet. Nie musimy z góry ustalać, że Harriet ma „dawać nagrody” lub że Robbie ma „postępować zgodnie z instrukcjami”, chociaż mogą to być rozsądne interpretacje tego, jak ostatecznie się zachowują. Aby zilustrować gry asystujące, użyjemy gry ze spinaczami. To bardzo prosta gra, w której człowiek Harriet ma motywację do „zasygnalizowania” robotowi Robbiemu informacji o swoich preferencjach. Robbie jest w stanie zinterpretować ten sygnał, ponieważ potrafi rozwiązać grę i dlatego może zrozumieć, co musiałoby być prawdą w preferencjach Harriet, aby mogła sygnalizować w ten sposób. Etapy gry są przedstawione na rysunku.
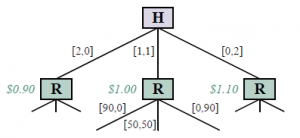
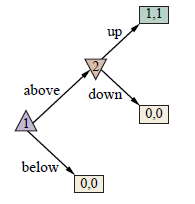
Polega na robieniu spinaczy i zszywek. Preferencje Harriet są wyrażane przez funkcję wypłaty, która zależy od liczby spinaczy do papieru i liczby wyprodukowanych zszywek, z pewnym „kursem wymiany” między nimi. Parametr preferencji θ Harriet oznacza względną wartość (w dolarach) spinacza; na przykład spinacze mogą wyceniać θ =0:45 dolara, co oznacza, że zszywki są warte 1 – θ =0:55 dolara. Tak więc, jeśli wyprodukowanych zostanie p spinaczy i zszywek s, zysk Harriet wyniesie w sumie pθ + s(1-θ ) dolarów. A priori Robbiego to P(θ ) = Uniform( θ;0,1). W samej grze Harriet jest pierwsza i może zrobić dwa spinacze do papieru, dwie zszywki lub po jednym z każdego. Następnie Robbie może zrobić 90 spinaczy, 90 zszywek lub 50 sztuk każdego. Zauważ, że gdyby robiła to sama, Harriet zrobiłaby tylko dwie zszywki o wartości 1,10 dolara. (Patrz adnotacje na pierwszym poziomie drzewa na rysunku 17.6) Ale Robbie patrzy i uczy się z jej wyboru. Czego dokładnie się uczy? Cóż, to zależy od tego, jak Harriet dokona wyboru. Jak Harriet dokonuje wyboru? To zależy od tego, jak Robbie to zinterpretuje. Możemy rozwiązać tę cykliczność, znajdując równowagę Nasha. W tym przypadku jest wyjątkowy i można go znaleźć, stosując najlepszą odpowiedź krótkowzroczną: wybierz dowolną strategię dla Harriet; wybierz najlepszą strategię dla Robbiego, biorąc pod uwagę strategię Harriet; wybrać najlepszą strategię dla Harriet, biorąc pod uwagę strategię Robbiego; i tak dalej. Proces przebiega następująco:
- Zacznij od zachłannej strategii dla Harriet: zrób dwa spinacze, jeśli woli spinacze; zrób po jednym z każdej, jeśli jest obojętna; zrób dwie zszywki, jeśli woli zszywki.
- Istnieją trzy możliwości, które Robbie musi rozważyć, biorąc pod uwagę tę strategię dla Harriet:
(a) Jeśli Robbie widzi, jak Harriet robi dwa spinacze, wnioskuje, że woli spinacze, więc teraz uważa, że wartość spinacza jest równomiernie rozłożona między 0,5 a 1,0, ze średnią 0,75. W takim przypadku jego najlepszym planem jest zrobienie 90 spinaczy o oczekiwanej wartości 67,50 dolarów dla Harriet.
(b) Jeśli Robbie widzi, że Harriet robi po jednym z nich, wywnioskuje, że spinacze i zszywki ceni sobie na 0,50, więc najlepszym wyborem jest zrobienie po 50 sztuk.
(c) Jeśli Robbie widzi, że Harriet robi dwie zszywki, to według tego samego argumentu, co w (a), powinien zrobić 90 zszywek.
- Biorąc pod uwagę tę strategię dla Robbiego, najlepsza strategia Harriet różni się teraz nieco od strategii zachłannej z kroku 1. Jeśli Robbie ma zamiar zareagować na zrobienie przez nią jednego z nich, robiąc po 50 sztuk każdego nie tylko, jeśli jest dokładnie obojętna, ale jeśli jest prawie obojętna. W rzeczywistości optymalna polityka polega teraz na zrobieniu jednego z nich, jeśli ceni sobie spinacze do papieru gdzieś między około 0,446 a 0,554.
- Biorąc pod uwagę tę nową strategię dla Harriet, strategia Robbiego pozostaje niezmieniona. Na przykład, jeśli wybierze jeden z nich, wywnioskuje, że wartość spinacza jest równomiernie rozłożona między 0,446 a 0,554, ze średnią 0,50, więc najlepszym wyborem jest zrobienie 50 sztuk każdego. Ponieważ strategia Robbiego jest taka sama jak w kroku 2, najlepsza odpowiedź Harriet będzie taka sama jak w kroku 3 i znaleźliśmy równowagę.
Dzięki swojej strategii Harriet w efekcie uczy Robbiego swoich preferencji, używając prostego kodu – języka, jeśli chcesz – wyłaniającego się z analizy równowagi. Zauważ też, że Robbie nigdy nie poznaje dokładnie preferencji Harriet, ale uczy się wystarczająco, by działać optymalnie w jej imieniu – tj. zachowuje się tak, jak gdyby dokładnie znał jej preferencje. Jest on ewidentnie korzystny dla Harriet zgodnie z podanymi założeniami i przy założeniu, że Harriet gra poprawnie. Najlepsza odpowiedź krótkowzroczna działa w tym przykładzie i innych, ale nie w bardziej złożonych przypadkach. Można wykazać, że przy braku powiązań powodujących problemy z koordynacją znalezienie optymalnego profilu strategii gry pomocowej sprowadza się do rozwiązania POMDP, którego przestrzeń stanów jest podstawową przestrzenią stanów gry plus parametry preferencji człowieka θ. Ogólnie rzecz biorąc, POMDP są bardzo trudne do rozwiązania (sekcja 16.5), ale POMDP reprezentujące gry asystujące mają dodatkową strukturę, która umożliwia bardziej wydajne algorytmy. Gry asystujące można uogólnić, aby umożliwić wielu ludzkim uczestnikom, wielu robotom, niedoskonale racjonalnym ludziom, ludziom, którzy nie znają własnych preferencji i tak dalej. Zapewniając podzieloną na czynniki lub ustrukturyzowaną przestrzeń działania, w przeciwieństwie do prostych akcji atomowych w grze w spinacze, możliwości komunikacji można znacznie zwiększyć. Niewiele z tych odmian zostało dotychczas zbadanych, ale spodziewamy się, że kluczowa właściwość gier asystujących pozostanie prawdziwa: im inteligentniejszy robot, tym lepszy wynik dla człowieka.