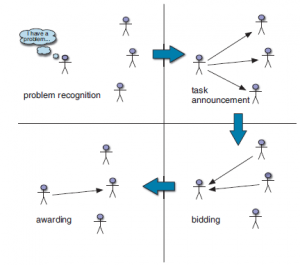
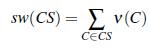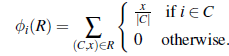Jednym z najważniejszych problemów w systemach wieloagentowych jest alokacja ograniczonych zasobów; ale równie dobrze możemy powiedzieć po prostu „alokacja zasobów”, ponieważ w praktyce najbardziej użyteczne zasoby są w pewnym sensie ograniczone. Aukcja jest najważniejszy mechanizm alokacji zasobów. Najprostszym ustawieniem aukcji jest jeden zasób i wielu możliwych licytujących. Każdy oferent i ma wartość użytkową vi dla przedmiotu.
W niektórych przypadkach każdy licytant ma prywatną wartość przedmiotu. Na przykład tandetny sweter może być atrakcyjny dla jednego licytującego i bezwartościowy dla drugiego. W innych przypadkach, takich jak licytacja praw do odwiertu dla traktu naftowego, przedmiot ma wspólną wartość — trakt przyniesie pewną sumę pieniędzy, X, a wszyscy licytujący wyceniają dolara jednakowo – ale nie ma pewności, jaka jest rzeczywista wartość X. Różni licytujący mają różne informacje, a co za tym idzie różne szacunki prawdziwej wartości przedmiotu. W obu przypadkach licytujący otrzymują własne vi. Biorąc pod uwagę vi, każdy licytujący ma szansę, w odpowiednim czasie lub momentach aukcji, na złożenie oferty bi. Najwyższa oferta, bmax, wygrywa przedmiot, ale zapłacona cena nie musi być bmax; to część konstrukcji mechanizmu.
Najbardziej znanym mechanizmem aukcji jest aukcja z ceną rosnącą, czyli aukcja angielska, w której centrum rozpoczyna od zapytania o minimalną (lub rezerwową) stawkę bmin. Jeśli jakiś oferent jest gotów zapłacić tę kwotę, centrum prosi o bmin + d, o pewną podwyżkę d i kontynuuje od tego momentu. Aukcja kończy się, gdy nikt już nie chce licytować; następnie ostatni licytant wygrywa przedmiot, płacąc cenę. Skąd wiemy, czy to dobry mechanizm? Jednym z celów jest maksymalizacja oczekiwanych przychodów sprzedawcy. Kolejnym celem jest maksymalizacja pojęcia użyteczności globalnej. Cele te do pewnego stopnia się pokrywają, ponieważ jednym z aspektów maksymalizacji globalnej użyteczności jest zapewnienie, że zwycięzcą aukcji jest agent, który najbardziej ceni przedmiot (a tym samym jest gotów zapłacić najwięcej). Mówimy, że aukcja jest skuteczna, jeśli towar trafia do agenta, który najbardziej je ceni. Aukcja z rosnącą ofertą rosnącą jest zwykle zarówno skuteczna, jak i maksymalizuje przychody, ale jeśli cena minimalna jest ustawiona zbyt wysoko, licytant, który ceni ją najbardziej, może nie licytować, a jeśli rezerwa jest ustawiona zbyt nisko, sprzedawca może uzyskać mniejsze przychody. Prawdopodobnie najważniejszą rzeczą, jaką może zrobić mechanizm aukcji, jest zachęcenie odpowiedniej liczby licytujących do wejścia do gry i zniechęcenie ich do angażowania się w zmowę. Zmowa to nieuczciwe lub nielegalne porozumienie pomiędzy dwoma lub więcej oferentami mające na celu manipulowanie cenami. Może się to zdarzyć w tajnych transakcjach na zapleczu lub milcząco, zgodnie z zasadami mechanizmu. Na przykład w 1999 r. Niemcy zlicytowały dziesięć bloków widma telefonii komórkowej z jednoczesną aukcją (oferty zostały złożone na wszystkich dziesięciu blokach jednocześnie), stosując zasadę, że każda oferta musi być co najmniej 10% podwyżką w stosunku do poprzedniej oferty na bloku. Było tylko dwóch wiarygodnych oferentów, a pierwszy, Mannesman, złożył ofertę 20 mln marek niemieckich na bloki 1-5 i 18,18 mln na bloki 6-10. Dlaczego 18,18 mln? Jeden z menedżerów T-Mobile powiedział, że „zinterpretował pierwszą ofertę Mannesmana jako ofertę”. Obie strony mogą obliczyć, że 10% podwyżka 18,18 mln to 19,99 mln; w ten sposób oferta Mannesmana została zinterpretowana jako mówiąca: „każdy z nas może dostać połowę bloków za 20M; nie psujmy tego, podbijając ceny. I faktycznie T-Mobile licytował 20M na bloki 6-10 i to był koniec licytacji.
Niemiecki rząd otrzymał mniej, niż się spodziewał, ponieważ dwaj konkurenci byli w stanie wykorzystać mechanizm przetargowy, aby dojść do milczącego porozumienia, jak nie konkurować. Z punktu widzenia rządu lepszy wynik mogłaby osiągnąć każda z tych zmian w mechanizmie: wyższa cena rezerwowa; aukcja pierwszej ceny z zapieczętowaną ofertą, tak aby konkurenci nie mogli komunikować się poprzez swoje oferty; lub zachęty do sprowadzenia trzeciego oferenta. Być może zasada 10% była błędem w konstrukcji mechanizmu, ponieważ ułatwiała precyzyjną sygnalizację z Mannesmana do T-Mobile. Ogólnie rzecz biorąc, zarówno sprzedający, jak i funkcja globalnej użyteczności zyskują, jeśli jest więcej oferentów, chociaż globalna użyteczność może ucierpieć, jeśli policzymy koszt straconego czasu licytujących, którzy nie mają szans na wygraną. Jednym ze sposobów zachęcenia większej liczby oferentów jest ułatwienie im mechanizmu. W końcu, jeśli wymaga to zbyt wielu badań lub obliczeń ze strony oferentów, mogą zdecydować się na przeniesienie swoich pieniędzy gdzie indziej. Pożądane jest więc, aby oferenci mieli dominującą strategię. Przypomnijmy, że „dominujący” oznacza, że strategia działa przeciwko wszystkim innym strategiom, co z kolei oznacza, że agent może ją przyjąć bez względu na inne strategie. Agent z dominującą strategią może po prostu licytować, nie tracąc czasu na rozważanie możliwych strategii innych agentów. Mechanizm, dzięki któremu agenci mają dominującą strategię, nazywa się mechanizmem odpornym na strategię. Jeśli, jak to zwykle bywa, strategia ta polega na ujawnieniu przez licytujących ich prawdziwej wartości, vi, wówczas nazywa się to aukcją ujawniającą prawdę lub uczciwą; używany jest również termin zgodny z zachętą. Zasada objawienia mówi, że każdy mechanizm może zostać przekształcony w równoważny mechanizm ujawniający prawdę, więc częścią projektowania mechanizmu jest znalezienie tych równoważnych mechanizmów.
Okazuje się, że aukcja z rosnącą licytacją ma większość pożądanych właściwości. Licytant z najwyższą wartością vi otrzymuje towar po cenie bo+d, gdzie bo to najwyższa oferta spośród wszystkich pozostałych agentów, a d to przyrost aukcjonera. Licytanci mają prostą strategię dominującą: kontynuuj licytację, dopóki bieżący koszt jest niższy niż twój vi. Mechanizm nie do końca ujawnia prawdę, ponieważ wygrywający licytujący ujawnia tylko, że jego vi ≥ bo+d; mamy dolną granicę vi, ale nie dokładną wartość. Wadą (z punktu widzenia sprzedającego) aukcji z rosnącą ceną jest to, że może zniechęcić konkurencję. Załóżmy, że w przetargu na widmo telefonów komórkowych jest jedna firma, która ma przewagę, co do której wszyscy zgadzają się, że byłaby w stanie wykorzystać istniejących klientów i infrastrukturę, a tym samym osiągnąć większy zysk niż ktokolwiek inny. Potencjalni konkurenci widzą, że nie mają szans w aukcji z rosnącą ofertą, ponieważ firma, która ma przewagę, zawsze może licytować wyżej. W ten sposób konkurenci mogą w ogóle nie wejść, a uprzywilejowana firma wygrywa po cenie minimalnej. Kolejną negatywną właściwością angielskiej aukcji są jej wysokie koszty komunikacji. Albo aukcja odbywa się w jednym pomieszczeniu, albo wszyscy licytujący muszą mieć szybkie i bezpieczne linie komunikacyjne; w obu przypadkach muszą mieć czas na przejście przez kilka rund licytacji. Alternatywnym mechanizmem, który wymaga znacznie mniej komunikacji, jest aukcja zapieczętowana. Każdy licytujący składa jedną ofertę i przekazuje ją licytatorowi, tak aby inni licytanci nie widzieli jej. Dzięki temu mechanizmowi nie ma już prostej strategii dominującej. Jeśli twoja wartość to vi i uważasz, że maksymalna stawka wszystkich pozostałych agentów wyniesie bo, powinieneś zalicytować bo+ ε , dla niektórych małych ε , jeśli jest to mniej niż vi. W związku z tym Twoja oferta zależy od Twojej oceny ofert innych agentów, co wymaga więcej pracy. Pamiętaj też, że agent z najwyższą wartością vi może nie wygrać aukcji. Jest to równoważone przez fakt, że aukcja jest bardziej konkurencyjna, co zmniejsza nastawienie na uprzywilejowanego licytanta. Mała zmiana w mechanizmie aukcji z zapieczętowaną ofertą prowadzi do aukcji drugiej ceny z zapieczętowaną ofertą, znanej również jako aukcja Vickreya. W takich aukcjach zwycięzca płaci cenę drugiej najwyższej oferty, bo, zamiast płacić własną ofertę. Ta prosta modyfikacja całkowicie eliminuje złożone rozważania wymagane w przypadku standardowych (lub pierwszej ceny) aukcji z zapieczętowaną ofertą, ponieważ obecnie dominującą strategią jest po prostu licytowanie vi; mechanizm ujawnia prawdę. Należy zauważyć, że użyteczność agenta i pod względem jego oferty bi, jego wartości vi i najlepszej oferty spośród innych agentów, bo, wynosi

Aby zobaczyć, że bi =vi jest strategią dominującą, zauważ, że gdy (vi-bo) jest dodatnie, każda oferta, która wygrywa aukcję, jest optymalna, a w szczególności licytacja vi wygrywa aukcję. Z drugiej strony, gdy (vi-bo) jest ujemne, każda oferta, która przegrywa aukcję, jest optymalna, a w szczególności licytacja vi przegrywa aukcję. Zatem licytacja vi jest optymalna dla wszystkich możliwych wartości bo iw rzeczywistości vi jest jedyną ofertą, która ma tę właściwość. Ze względu na swoją prostotę i minimalne wymagania obliczeniowe zarówno dla sprzedającego, jak i oferentów, aukcja Vickreya jest szeroko stosowana w rozproszonych systemach sztucznej inteligencji. Wyszukiwarki internetowe przeprowadzają co roku kilka bilionów aukcji, aby sprzedawać reklamy wraz z wynikami wyszukiwania, a witryny aukcyjne online obsługują towary o wartości 100 miliardów dolarów rocznie, korzystając z różnych wariantów aukcji Vickrey. Zwróć uwagę, że oczekiwana wartość dla sprzedającego to bo, co jest tym samym oczekiwanym zwrotem, co limit aukcji angielskiej, gdy przyrost d dochodzi do zera. W rzeczywistości jest to bardzo ogólny wynik: twierdzenie o równoważności przychodów mówi, że z kilkoma drobnymi zastrzeżeniami każdy mechanizm aukcji, w którym oferenci mają wartości vi znane tylko sobie (ale znają rozkład prawdopodobieństwa, z którego te wartości są próbkowane), przyniesie te same oczekiwane przychody. Zasada ta oznacza, że różne mechanizmy konkurują ze sobą nie na zasadzie generowania przychodów, ale raczej na innych cechach. Chociaż aukcja drugiej ceny jest odsłanianiem prawdy, okazuje się, że licytacja n towarów przy cenie n+1 nie jest odsłanianiem prawdy. Wiele wyszukiwarek internetowych korzysta z mechanizmu, w ramach którego wystawiają na aukcje n boksów reklamowych na stronie. Osoba, która zaoferuje najwyższą cenę, wygrywa pierwsze miejsce, druga osoba z najwyższą ofertą otrzymuje drugie miejsce i tak dalej. Każdy zwycięzca płaci cenę oferowaną przez następną niższą ofertę, przy założeniu, że płatność jest dokonywana tylko wtedy, gdy osoba wyszukująca faktycznie kliknie reklamę. Najwyższe sloty są uważane za bardziej wartościowe, ponieważ są bardziej prawdopodobne, że zostaną zauważone i kliknięte. Wyobraź sobie, że trzech licytujących, b1;b2 i b3, ma wycenę kliknięcia na v1=200;v2=180; i v3=100, oraz że n = 2 sloty są dostępne; i wiadomo, że górne miejsce jest klikane w 5% przypadków, a dolne w 2%. Jeśli wszyscy licytujący licytują zgodnie z prawdą, b1 wygrywa najwyższe miejsce i płaci 180, a oczekiwany zwrot (200-180) 0:05=1. Drugi slot trafia na b2. Ale b1 widzi, że gdyby zalicytował cokolwiek z zakresu 101–179, przyznałby pierwsze miejsce na b2, wygrałby drugie miejsce i przyniósłby oczekiwany zwrot (200100) :02=2. W ten sposób b1 może podwoić swój oczekiwany zwrot, licytując w tym przypadku mniej niż jej prawdziwa wartość. Ogólnie rzecz biorąc, oferenci w tej aukcji cenowej n+1 muszą poświęcić dużo energii na analizę ofert innych osób, aby określić swoją najlepszą strategię; nie ma prostej strategii dominującej. Aggarwal i inni pokazują, że istnieje unikalny, prawdziwy mechanizm aukcji dla tego problemu z wieloma slotami, w którym zwycięzca slotu j płaci cenę za slot j tylko za te dodatkowe kliknięcia, które są dostępne na slocie j, a nie na gnieździe j+1. Zwycięzca płaci cenę za dolny slot za pozostałe kliknięcia. W naszym przykładzie b1 zalicytowałby zgodnie z prawdą 200 i zapłaciłby 180 za dodatkowe :05-:02=:03 kliknięcia w górnym slocie, ale zapłaciłby tylko koszt dolnego gniazda, czyli 100, za pozostałe 0,02 kliknięcia . Zatem całkowity zwrot z b1 wyniósłby (200-180) :03+(200100) :02=2:6. Innym przykładem sytuacji, w której aukcje mogą wchodzić w grę w ramach sztucznej inteligencji, jest sytuacja, w której grupa agentów decyduje, czy współpracować nad wspólnym planem. Hunsberger i Grosz pokazują, że można to skutecznie osiągnąć dzięki aukcji, w której agenci ubiegają się o role we wspólnym planie.