Podstawowy projekt agenta POMDP online jest prosty: zaczyna się od pewnego wcześniejszego stanu wiary; wybiera działanie oparte na pewnym procesie deliberacji skoncentrowanym na jego obecnym stanie przekonań; po wykonaniu działania otrzymuje obserwację i aktualizuje swój stan przekonania za pomocą algorytmu filtrującego; i proces się powtarza. Jednym z oczywistych wyborów do procesu rozważań jest algorytm expectimax , z wyjątkiem stanów przekonań, a nie stanów fizycznych jako węzłów decyzyjnych w drzewie. Węzły losowe w drzewie POMDP mają gałęzie oznaczone możliwymi obserwacjami i prowadzące do następnego stanu przekonania, z prawdopodobieństwem przejścia podanym przez równanie. Fragment drzewa oczekiwania-stanu przekonania dla POMDP 4 x 3 pokazano na rysunku.
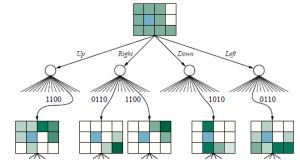
Złożoność czasowa wyczerpującego poszukiwania do głębokości d wynosi O (|A|d · |E|d), gdzie |A| to liczba dostępnych akcji, a |E| to liczba możliwych perceptów. (Zauważ, że jest to znacznie mniej niż liczba możliwych planów warunkowych głębokości d generowanych przez iterację wartości). Podobnie jak w przypadku obserwowalnym, próbkowanie w węzłach losowych jest dobrym sposobem na zmniejszenie współczynnika rozgałęzienia bez utraty zbyt dużej dokładności w ostateczna decyzja. Zatem złożoność przybliżonego podejmowania decyzji online w POMDP może nie być drastycznie gorsza niż w przypadku MDP. W przypadku bardzo dużych przestrzeni stanów dokładne filtrowanie jest niewykonalne, więc agent będzie musiał uruchomić przybliżony algorytm filtrowania, taki jak filtrowanie cząstek (patrz strona 510). Wtedy przekonania w drzewie oczekiwanym stają się zbiorami cząstek, a nie dokładnymi rozkładami prawdopodobieństwa. W przypadku problemów z długimi horyzontami konieczne może być również uruchomienie rozgrywania dalekiego zasięgu stosowanego w algorytmie UCT. Połączenie filtrowania cząstek i UCT zastosowane w POMDP nosi nazwę częściowo obserwowalnego planowania Monte Carlo lub POMCP. Z reprezentacją DDN dla modelu, algorytm POMCP ma, przynajmniej w zasadzie, zastosowanie do bardzo dużych i realistycznych POMDP. POMCP jest w stanie generować właściwe zachowanie w 4 x 3 POMDP. Krótki (i nieco szczęśliwy) przykład pokazano na rysunku
![]()
Agenci POMDP oparte na dynamicznych sieciach decyzyjnych i podejmowaniu decyzji online mają szereg zalet w porównaniu z innymi, prostszymi projektami agentów przedstawionymi we wcześniejszych rozdziałach. W szczególności zajmują się częściowo obserwowalnymi, stochastycznymi środowiskami i mogą łatwo zrewidować swoje „plany”, aby poradzić sobie z nieoczekiwanymi dowodami. Dzięki odpowiednim modelom czujników mogą poradzić sobie z awarią czujnika i planować zbieranie informacji. Wykazują „wdzięczną degradację” pod presją czasu i w złożonych środowiskach, przy użyciu różnych technik aproksymacyjnych. Więc czego brakuje? Główną przeszkodą we wdrażaniu takich agentów w świecie rzeczywistym jest niemożność generowania udanego zachowania w długich skalach czasowych. Losowe lub prawie losowe zagrania nie mają nadziei na uzyskanie jakiejkolwiek pozytywnej nagrody za, powiedzmy, zadanie nakrycia stołu do kolacji, co może wymagać dziesiątek milionów działań związanych z kontrolą motoryczną. Wydaje się konieczne zapożyczenie niektórych pomysłów dotyczących planowania hierarchicznego.