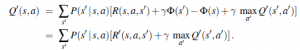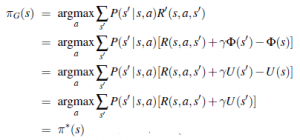Wyjątkowo popularna platforma e-commerce Amazon, Amazon.com, wdraża technologię uczenia maszynowego od dłuższego czasu. Dzięki uczeniu maszynowemu Amazon.com może polecać podobne produkty, gdy klienci coś kupują lub wysyłać odpowiednie promocje użytkownikom, którzy oglądali niektóre produkty, ale ich nie kupowali. Amazon jest bez wątpienia jednym z prekursorów, jeśli chodzi o wykorzystanie korzyści związanych z produktywnością i wydajnością stworzonych przez użycie robotów, co z kolei pozwala firmie oferować lepsze funkcje dla klientów, takie jak szybka dostawa. W rzeczywistości, zgodnie z najnowszymi raportami, obecnie w magazynach Amazon jest używanych ponad 100 000 robotów pomarańczowych i ponad 1000 pracowników, którzy budują, programują i pracują obok nich. Amazon inwestuje zasoby w rozwój sztucznej inteligencji również w wielu innych obszarach. Od dostaw dronów po osobistą asystentkę Alexę, a także badania danych klientów, firma znalazła różne sposoby ulepszania swoich produktów i usług poprzez zastosowanie sztucznej inteligencji.
Praktyczne zastosowania sztucznej inteligencji w Amazon
Amazon wykorzystuje sztuczną inteligencję do ulepszenia niektórych swoich e-commerce i usługi internetowe. Niektóre sposoby wykorzystania technologii obejmują:
• Produkty zalecane przez Amazon: Jedną z najpopularniejszych aplikacji sztucznej inteligencji firmy Amazon jest jej zdolność do gromadzenia i analizowania danych klientów w celu tworzenia dokładniejszych sugestii dotyczących produktów. Dla Amazon i jej dostawców utrzymanie wydatków konsumentów jest kluczowe, a AI pomaga im w utrzymaniu napływu zamówień.
• Osobisty asystent Alexa: osobisty asystent Amazona otrzymał niedawno ulepszenie dzięki dodaniu Echo, cyfrowego urządzenia głośnikowego, które jeszcze bardziej ułatwia interakcję z Alexą. Echo / Alexa aktywowane mową mogą być używane do wyszukiwania informacji, takich jak czas lub pogoda, do odtwarzania muzyki i do wielu innych zadań.
• Przechowywanie w chmurze: AI zostało zastosowane w usłudze przechowywania w chmurze Amazon w celu zabezpieczenia danych. Nazywa się Amazon Macie i wykorzystuje uczenie maszynowe do wyszukiwania, sortowania i ochrony poufnych informacji. Macie powstał w reakcji na naruszenie bezpieczeństwa, które miało miejsce w Amazon S3, prostej usłudze przechowywania w chmurze, kiedy ponad 60 000 poufnych plików należących do rządu USA stało się dostępnych dla ogółu społeczeństwa. Dzięki sztucznej inteligencji bardziej wyrafinowani Macie mogą teraz wyszukiwać tego rodzaju poufne dane i zabezpieczyć je, a także śledzić dostęp do danych w celu wykrycia podejrzanych działań.
Usługi AI w chmurze Amazon dla firm
Amazon będzie jedną z najbardziej konkurencyjnych firm oferujących usługi sztucznej inteligencji firmom, podobnie jak Google, Microsoft i IBM. Od dłuższego czasu Amazon jest dostawcą usług hostingowych dla wielu klientów korporacyjnych, a teraz zaczyna oferować również możliwości AI dla innych firm. Na przykład Intuit, firma finansująca niektóre popularne produkty finansowe, takie jak TurboTax, wykorzystuje platformę AI Amazon do wprowadzania uczenia maszynowego do swoich produktów. Platforma AI firmy Amazon oferuje następujące podstawowe produkty i usługi dla firm:
• Amazon Lex: Umożliwia tworzenie potężnych chatbotów z funkcjami audio. Działa z tą samą technologią, która zasila Amazon Alexa i wykorzystuje automatyczne rozpoznawanie mowy (ASR) i rozumienie języka naturalnego (NLU).
• Amazon Polly: usługa zamiany tekstu na mowę, która pozwala tworzyć aplikacje mówiące w kilku językach.
• Rozpoznawanie Amazon: Umożliwia dodanie analizy obrazu do dowolnej apliakcji.
Jestem pewien, że platforma AI Amazon będzie bardzo popularna wśród wszystkich rodzajów firm, zwłaszcza małych i średnich, które zaczynają rozumieć znaczenie rozpoczęcia pracy ze sztuczną inteligencją. Więcej informacji można znaleźć na stronie: https://aws.amazon.com/amazon-ai
Chociaż firma ma już sztuczną inteligencję na większości swoich produktów, wciąż liczy na przyszły rozwój sztucznej inteligencji, aby ulepszyć swoją ofertę. wciąż liczy na przyszły rozwój sztucznej inteligencji, aby ulepszyć swoją ofertę. Według dyrektora generalnego Amazon, Jeffa Bezosa, sztuczna inteligencja ma kluczowe znaczenie dla sukcesu firmy:
“Uczenie maszynowe napędza nasze algorytmy prognozowania popytu, rankingu wyszukiwania produktów, rekomendacji produktów i ofert, zerowania miejsc docelowych, wykrywania oszustw, tłumaczeń i wielu innych. Choć mniej widoczny, znaczny wpływ uczenia maszynowego będzie tego typu – po cichu, ale w znaczący sposób usprawni podstawowe operacje “.
Bezos powiedział również, że wierzy, że AI będzie kluczem do tego ulepszenie wszystkich firm i rządów. Matt Wood, dyrektor generalny Deep Learning i AI dla Amazon Web Services (AWS), wspomniał ostatnio, że internetowy gigant handlu elektronicznego ma największą platformę AI na świecie.