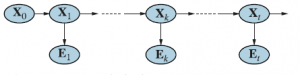
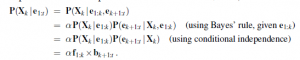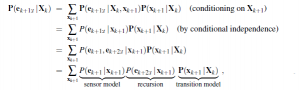Wyobraź sobie, że możesz szybko i łatwo uzyskać dostęp do wysokiego kalibru badań rynkowych, które kiedyś były oferowane tylko największym i najbogatszym firmom – tym, które mogły zlecić to zadanie najlepszym firmom badającym rynek. Czy byłbyś zainteresowany? W przeszłości proces badania rynku był czasochłonny, a wiarygodność spostrzeżeń dotyczących myśli i decyzji konsumentów była daleka od doskonałości. Teraz bezpłatne narzędzia online wykorzystujące sztuczną inteligencję są dostępne w Google i Facebook, w tym Google Trends i Facebook Audience Insights, dzięki czemu każda firma może korzystać z wysokiej jakości informacji w czasie rzeczywistym. Narzędzia te pozwalają firmom, które ich używają, przewidywać i przygotowywać się do trendów w swojej branży, zapewniając im przewagę konkurencyjną. Podczas gdy tylko nieliczne firmy obecnie w pełni korzystają z tych niesamowitych zasobów, rozwój narzędzi sztucznej inteligencji, takich jak Watson IBM, pozwoli wszystkim na szybsze niż kiedykolwiek korzystanie z kompleksowych danych z badań rynkowych w niemal każdej branży. Korzystanie z informacji biznesowych opartych na sztucznej inteligencji może pomóc firmie szybko reagować na nowe trendy na rynku, dzięki czemu może stać się liderem w swojej branży, co może mieć duży wpływ na wyniki finansowe. Chociaż istnieje wiele rodzajów informacji, które te narzędzia AI mogą generować, oto niektóre z najbardziej wpływowych i ważnych:
• Szczegółowe informacje o twoich konkurentach: Obejmuje to wgląd w ich źródła dochodów, produkty odnoszące większe sukcesy, personel, kluczowe przewagi konkurencyjne, wyzwania, przed którymi stają, oraz wyniki w mediach społecznościowych.
• Informacje konsumenckie i dane predykcyjne: Przy coraz większej ilości dostępnych danych narzędzia sztucznej inteligencji ułatwią analizę sygnałów od konsumentów i tworzenie prognoz prognozujących przyszłe trendy. Na przykład firmy mogą teraz korzystać z Google Trends lub Facebook Audience Insights, aby określić, jakie kostiumy na Halloween będą wyszukiwane przez konsumentów w tym sezonie, ale ręczne uzyskanie wyników może zająć trochę czasu. AI sprawi, że ten proces będzie szybszy, wydajniejszy i bardziej efektywny dzięki automatycznej analizie sygnałów konsumentów.
• Możliwości personalizacji produktu: narzędzia AI odgrywają ważną rolę, ponieważ reklama produktu staje się bardziej zindywidualizowana i precyzyjna w celu personalizacji produktu. Zasoby te mogą pomóc firmom zidentyfikować kluczowych odbiorców i skuteczniej docierać do nich na poziomie indywidualnym, dostosowując sposób wyświetlania reklam do czynników takich jak płeć, wiek, lokalizacja lub zawód. To właśnie tam leży przyszłość reklamy.
• Lista najważniejszych czynników wpływających na konsumentów: Instrumenty sztucznej inteligencji mogą pomóc firmom rozpoznać, a następnie wykorzystać najbardziej skuteczne kanały dotarcia do określonego rynku. Jest to szczególnie przydatne na platformach społecznościowych, takich jak YouTube i Instagram, gdzie osoby mogą szybko i skutecznie wpływać na ogromną grupę obserwujących. Korzystanie z osób, które mają największy zasięg wśród odbiorców docelowych, w celu promowania twoich produktów lub usług za pomocą dostosowanych recenzji jest znane jako marketing wpływowy i ma duży potencjał do sukcesu, jeśli jest wykonany poprawnie i autentycznie.
Tego rodzaju badania rynku, których wygenerowanie zajmowało miesiące, mogą w przyszłości zostać zakończone w ciągu kilku godzin, a nawet minut, dzięki niesamowitym możliwościom narzędzi AI. Podczas gdy firmy każdej wielkości prawdopodobnie zaczną wykorzystywać te narzędzia do badania rynku oparte na sztucznej inteligencji w przyszłości, najlepsze możliwości będą dostępne dla pojedynczych przedsiębiorców, którzy chcą mieć możliwość szybkiego wprowadzenia nowych produktów i mogą wykorzystać te zasoby, aby wyprzedzić ich konkurenci. W tej sekcji celowo nie wymieniłem żadnych konkretnych narzędzi badania rynku, które mogłyby wykonać wszystkie wyżej wymienione zadania, ponieważ obecnie jest bardzo niewiele niedrogich, które mogłyby to zrobić. Jednak w przypadku średnich i dużych firm IBM Watson może być jedną z możliwych opcji na początek. Możliwości badań rynku są nieograniczone przy pomocy sztucznej inteligencji.