Wcześniej wprowadziliśmy podstawową ideę poszukiwania w przestrzeni stanów przekonań, aby znaleźć rozwiązanie problemów bezczujnikowych. Zakładamy, że podstawowy problem planowania jest deterministyczny. Początkowy stan przekonania dotyczący problemu z malowaniem bezczujnikowym może zignorować płynność InView, ponieważ agent nie ma czujników. Ponadto przyjmujemy za niezmienne fakty  ponieważ obowiązują one w każdym stanie wiary. Agent nie zna kolorów puszek lub przedmiotów, ani tego, czy puszki są otwarte, czy zamknięte, ale wie, że przedmioty i puszki mają kolory
ponieważ obowiązują one w każdym stanie wiary. Agent nie zna kolorów puszek lub przedmiotów, ani tego, czy puszki są otwarte, czy zamknięte, ale wie, że przedmioty i puszki mają kolory  Po Skolemizing otrzymujemy początkowy stan wiary:
Po Skolemizing otrzymujemy początkowy stan wiary:
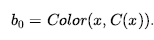
W planowaniu klasycznym, w którym przyjmuje się założenie o zamkniętym świecie, przyjęlibyśmy, że każdy płyn nie wymieniony w stanie jest fałszywy, ale w planowaniu bezczujnikowym (i częściowo obserwowalnym) musimy przełączyć się na założenie otwartego świata, w którym stany zawierają zarówno biegły pozytywny, jak i negatywny, a jeśli biegły się nie pojawia, jego wartość jest nieznana. Zatem stan przekonań odpowiada dokładnie zbiorowi możliwych światów, które spełniają formułę. Biorąc pod uwagę ten początkowy stan przekonań, następująca sekwencja działań jest rozwiązaniem:
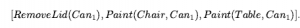
Pokażemy teraz, jak rozwinąć stan przekonań poprzez sekwencję działań, aby pokazać, że ostateczny stan przekonań spełnia cel. Po pierwsze, zauważ, że w danym stanie przekonania b , podmiot może rozważyć każde działanie, którego warunki wstępne są spełnione przez b . (Innych działań nie można użyć, ponieważ model przejścia nie definiuje skutków działań, których warunki wstępne mogą być niespełnione). Ogólna formuła aktualizacji stanu przekonania b przy odpowiednim działaniu w deterministycznym świecie jest następująca:
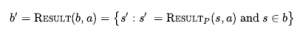
gdzie RESULTP definiuje fizyczny model przejścia. Na razie zakładamy, że początkowy stan wiary jest zawsze koniunkcją literałów, czyli formułą 1-CNF. Aby skonstruować nowy stan przekonań b’ , musimy rozważyć, co dzieje się z każdym dosłownym l w każdym stanie fizycznym s w b, gdy stosowane jest działanie a. W przypadku literałów, których wartość logiczna jest już znana w b , wartość logiczna w b’ jest obliczana na podstawie wartości bieżącej oraz listy add i delete akcji. (Na przykład, jeśli l znajduje się na liście usuwania akcji, to ¬l jest dodawany b’) A co z literałem a , którego wartość prawdy jest nieznana w b? Istnieją trzy przypadki:
- Jeśli akcja dodaje l , to l będzie prawdziwe w b’ niezależnie od jego wartości początkowej.
- Jeśli akcja usunie l , to l będzie fałszywe w b’ niezależnie od jego wartości początkowej.
- Jeśli akcja nie wpływa na l , to l zachowa swoją początkową wartość (która jest nieznana) i nie pojawi się w b’ .
Widzimy więc, że obliczenie b’ jest prawie identyczne z obserwowalnym przypadkiem.
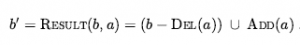
Nie możemy całkowicie użyć semantyki zbiorów, ponieważ (1) musimy upewnić się, że b’ nie zawiera zarówno l, jak i ¬l oraz (2) atomy mogą zawierać niezwiązane zmienne. Ale nadal tak jest że RESULTP(b,a) jest obliczany zaczynając od b , ustawiając każdy atom, który pojawia się w Del(a) na false i ustawiając każdy atom, który pojawia się w ADD(a) na true. Na przykład, jeśli zastosujemy RemoveLid(Can1) do początkowego stanu przekonania b0 , otrzymamy
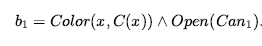
Kiedy wykonujemy akcję  ,warunek
,warunek  jest spełniony przez dosłowne
jest spełniony przez dosłowne  z wiązaniem
z wiązaniem  i nowym stanem wiary jest
i nowym stanem wiary jest
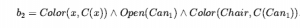
Na koniec stosujemy akcję  aby uzyskać
aby uzyskać
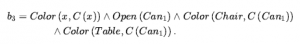
Ostateczny stan przekonania spełnia cel  ze zmienną c przywiązaną do
ze zmienną c przywiązaną do 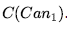
Poprzednia analiza reguły aktualizacji wykazała bardzo ważny fakt: rodzina stanów przekonań definiowanych jako koniunkcje literałów jest zamknięta pod aktualizacjami zdefiniowanymi przez schematy działania PDDL. Oznacza to, że jeśli stan przekonania zaczyna się jako koniunkcja literałów, to każda aktualizacja da koniunkcję literałów. Oznacza to, że w świecie z n biegłościami każdy stan przekonań może być reprezentowany przez koniunkcję rozmiaru O(n) . To bardzo pocieszający wynik, biorąc pod uwagę, że na świecie jest 2n stanów. Mówi, że możemy zwięźle przedstawić wszystkie podzbiory tych 2n stanów, których kiedykolwiek będziemy potrzebować. Co więcej, proces sprawdzania stanów przekonań, które są podzbiorami lub nadzbiorami wcześniej odwiedzonych stanów przekonań, jest również łatwy, przynajmniej w przypadku zdań. Istotą tego przyjemnego obrazu jest to, że działa on tylko w przypadku schematów działania, które mają takie same skutki dla wszystkich stanów, w których spełnione są ich warunki wstępne. To właśnie ta właściwość umożliwia zachowanie reprezentacji stanu przekonań 1-CNF. Gdy tylko efekt może zależeć od stanu, wprowadzane są zależności między biegłymi, a właściwość 1-CNF zostaje utracona. Rozważmy na przykład prosty świat próżni zdefiniowany wcześniej. Niech biegły to AtL i AtR dla lokalizacji robota oraz CleanL i CleanR dla stanu kwadratów. Zgodnie z definicją problemu działanie Ssania nie ma żadnego warunku wstępnego – zawsze można to zrobić. Trudność polega na tym, że jego efekt zależy od lokalizacji robota: gdy robot jest AtL, wynikiem jest CleanL, ale gdy jest AtR, wynikiem jest CleanR. W przypadku takich działań nasze schematy działania będą potrzebowały czegoś nowego: efektu warunkowego. Mają one składnię „gdy warunek: efekt”, gdzie warunek jest logiczną formułą porównywaną z bieżącym stanem, a efekt jest formułą opisującą stan wynikowy. Dla świata próżni:
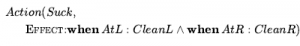
Po zastosowaniu do początkowego stanu przekonania True, wynikowym stanem przekonania jest  który nie jest już w 1-CNF. Ogólnie, efekty warunkowe mogą wywoływać arbitralne zależności między osobami biegłymi w stanie przekonań, prowadząc w najgorszym przypadku do stanów przekonań o wielkości wykładniczej. Ważne jest, aby zrozumieć różnicę między warunkami wstępnymi a efektami warunkowymi. Wszystkie efekty warunkowe, których warunki są spełnione, mają swoje efekty stosowane w celu wygenerowania wynikowego stanu przekonania; jeśli żaden nie jest spełniony, stan wynikowy pozostaje niezmieniony. Z drugiej strony, jeśli warunek wstępny nie jest spełniony, to akcja nie ma zastosowania, a stan wynikowy jest nieokreślony. Z punktu widzenia planowania bezczujnikowego lepiej jest mieć efekty warunkowe niż działanie nie dające się zastosować. Na przykład możemy podzielić Ssanie na dwie akcje z bezwarunkowymi skutkami w następujący sposób:
który nie jest już w 1-CNF. Ogólnie, efekty warunkowe mogą wywoływać arbitralne zależności między osobami biegłymi w stanie przekonań, prowadząc w najgorszym przypadku do stanów przekonań o wielkości wykładniczej. Ważne jest, aby zrozumieć różnicę między warunkami wstępnymi a efektami warunkowymi. Wszystkie efekty warunkowe, których warunki są spełnione, mają swoje efekty stosowane w celu wygenerowania wynikowego stanu przekonania; jeśli żaden nie jest spełniony, stan wynikowy pozostaje niezmieniony. Z drugiej strony, jeśli warunek wstępny nie jest spełniony, to akcja nie ma zastosowania, a stan wynikowy jest nieokreślony. Z punktu widzenia planowania bezczujnikowego lepiej jest mieć efekty warunkowe niż działanie nie dające się zastosować. Na przykład możemy podzielić Ssanie na dwie akcje z bezwarunkowymi skutkami w następujący sposób:

Teraz mamy tylko schematy bezwarunkowe, więc wszystkie stany przekonań pozostają w 1-CNF; niestety nie możemy określić stosowalności SuckL i SuckR w początkowym stanie wiary. Wydaje się zatem nieuniknione, że nietrywialne problemy będą obejmować niestabilne stany przekonań, podobnie jak te, które napotkaliśmy, gdy rozważaliśmy problem szacowania stanu dla świata wumpusów. Sugerowanym wówczas rozwiązaniem było użycie konserwatywnego przybliżenia do dokładnego stanu przekonań; na przykład stan przekonania może pozostać w 1-CNF, jeśli zawiera wszystkie literały, których wartości prawdy można określić i traktuje wszystkie inne literały jako nieznane. Chociaż to podejście jest słuszne, ponieważ nigdy nie generuje błędnego planu, jest niekompletne, ponieważ może nie być w stanie znaleźć rozwiązań problemów, które z konieczności wiążą się z interakcjami między literałami. Aby dać trywialny przykład, jeśli celem jest, aby robot znalazł się na czystym kwadracie, to [Ssanie] jest rozwiązaniem, ale agent bezczujnikowy, który nalega na stany przekonań 1-CNF, nie znajdzie go. Być może lepszym rozwiązaniem jest szukanie sekwencji działań, które utrzymają stan przekonań tak prosty, jak to tylko możliwe. W świecie próżni bezczujnikowej sekwencja działań [Prawo,Ssanie,Lewo,Ssanie] generuje następującą sekwencję stanów przekonań:

Oznacza to, że agent może rozwiązać problem, zachowując stan przekonania 1-CNF, nawet jeśli niektóre sekwencje (np. te zaczynające się od Suck) wychodzą poza 1-CNF. Ogólna lekcja nie jest stracona dla ludzi: zawsze wykonujemy drobne czynności (sprawdzamy czas, klepiemy po kieszeniach, aby upewnić się, że mamy kluczyki do samochodu, czytamy znaki drogowe podczas poruszania się po mieście), aby wyeliminować niepewność i zachować nasze przekonania do opanowania. Jest jeszcze inne, zupełnie inne podejście do problemu nieporadnie poruszających się stanów wiary: w ogóle nie zawracaj sobie głowy ich obliczaniem. Załóżmy, że początkowy stan przekonań b0 jest i chcielibyśmy poznać stan przekonań wynikający z sekwencji działania [a1…am] . Zamiast obliczać to wprost, po prostu przedstaw to jako „b0, a następnie [a1…am]”. Jest to leniwa, ale jednoznaczna reprezentacja stanu przekonań i jest dość zwięzła — O(n+m), gdzie n jest rozmiarem początkowego stanu przekonań (zakłada się, że jest w 1-CNF), a m jest maksymalną długością sekwencja działań. Jako reprezentacja stanu przekonań ma jednak jedną wadę: ustalenie, czy cel jest spełniony, czy działanie jest możliwe, może wymagać wielu obliczeń. Obliczenie można zaimplementować jako test implikacji: jeśli Am reprezentuje zbiór aksjomatów stanu następcy wymaganych do zdefiniowania wystąpień akcji a1 .. am — jak wyjaśniono dla SATPLAN — a Gm zapewnia, że cel jest prawdziwy po m krokach, to plan osiąga cel, jeśli  —
—  to znaczy, jeśli jest niezadowalające.
to znaczy, jeśli jest niezadowalające.
Biorąc pod uwagę nowoczesny solver SAT, może być możliwe zrobienie tego znacznie szybciej niż obliczenie pełnego stanu wiary. Na przykład, jeśli żadne z działań w sekwencji nie ma określonego celu płynnego na swojej liście dodawania, solver wykryje to natychmiast. Pomocne jest również, jeśli częściowe wyniki dotyczące stanu przekonań — na przykład biegły, o którym wiadomo, że są prawdziwe lub fałszywe — są zapisywane w pamięci podręcznej, aby uprościć kolejne obliczenia. Ostatnim elementem układanki planowania bezczujnikowego jest funkcja heurystyczna, która kieruje poszukiwaniami. Znaczenie funkcji heurystycznej jest takie samo jak w przypadku planowania klasycznego: oszacowanie (być może dopuszczalne) kosztu osiągnięcia celu z danego stanu wiary. W przypadku stanów przekonań mamy jeden dodatkowy fakt: rozwiązanie dowolnego podzbioru stanu przekonań jest z konieczności łatwiejsze niż rozwiązanie stanu przekonań: stąd każda dopuszczalna heurystyka obliczona dla podzbioru jest dopuszczalna dla samego stanu przekonań. Najbardziej oczywistymi kandydatami są podzbiory singletonów, czyli poszczególne stany fizyczne.
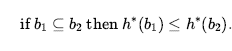
Stąd każda dopuszczalna heurystyka obliczona dla podzbioru jest dopuszczalna dla samego stanu przekonań. Najbardziej oczywistymi kandydatami są podzbiory singletonów, czyli poszczególne stany fizyczne. Możemy wziąć dowolny losowy zbiór stanów s1, … sN, które są w stanie przekonania b , zastosować dowolną dopuszczalną heurystykę h i zwrócić
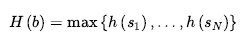
jako oszacowanie heurystyczne do rozwiązania. Możemy również użyć niedopuszczalnych heurystyk, takich jak heurystyka „ignoruj-usuń-listy”, która wydaje się działać całkiem dobrze w praktyce.








