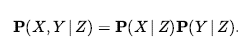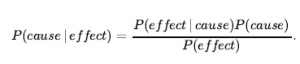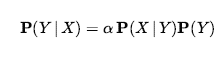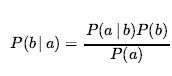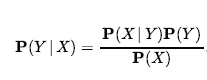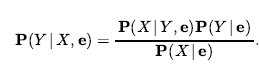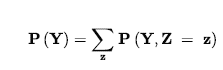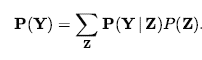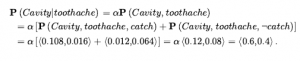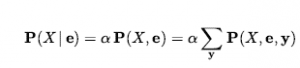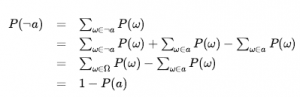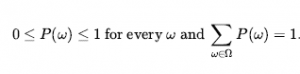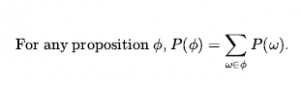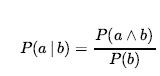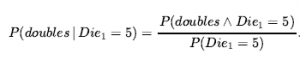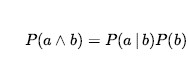Zdania opisujące zbiory możliwych światów są zwykle pisane w notacji, która łączy elementy logiki zdań i notacji spełniania ograniczeń. W terminologii sekcji 2.4.7 jest to reprezentacja podzielona na czynniki, w której możliwy świat jest reprezentowany przez zestaw par zmienna/wartość. Możliwa jest również bardziej ekspresyjna reprezentacja strukturalna, jak pokazano w rozdziale 15 . Zmienne w teorii prawdopodobieństwa nazywane są zmiennymi losowymi, a ich nazwy zaczynają się od dużej litery. Zatem w przykładzie z kostką Total i Die1 są zmiennymi losowymi. Każda zmienna losowa jest funkcją, która odwzorowuje z dziedziny możliwych światów OMEGA na pewien zakres – zbiór możliwych wartości, które może przyjąć. Zakres sumy dla dwóch kości to zestaw {2…12}, a zakres kości1 to {1…6} . Nazwy wartości są zawsze pisane małymi literami, więc możemy napisać SIGMA, aby sumować wartości X . Zmienna losowa typu Boolean ma zakres {true, false} . na przykład twierdzenie, że wyrzucono podwajania, można zapisać jako Double = true . (Alternatywnym zakresem dla zmiennych logicznych jest zbiór {0,1} , w którym to przypadku zmienna ma rozkład Bernoulliego.) Zgodnie z konwencją, zdania w postaci A = prawda są skracane po prostu jako a , podczas gdy A = fałsz jest skrócony jako ¬a. (Stosowanie dubletów, ubytku i bólu zęba w poprzedniej sekcji to skróty tego rodzaju.)
Zakresy mogą być zestawami dowolnych tokenów. Możemy wybrać przedział wiekowy jako zestaw {młodzież, nastolatek, dorosły}, a przedział Pogody może być {słońce, deszcz, chmura, śnieg}. Gdy żadna dwuznaczność nie jest możliwa, często używa się samej wartości jako zdania, że dana zmienna ma tę wartość; tak więc słońce może oznaczać Pogoda = słońce. Wszystkie powyższe przykłady mają skończone zakresy. Zmienne mogą mieć również nieskończone zakresy — albo dyskretne (jak liczby całkowite) albo ciągłe (jak liczby rzeczywiste). W przypadku dowolnej zmiennej o uporządkowanym zakresie dozwolone są również nierówności, takie jak
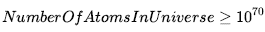
Wreszcie możemy łączyć tego rodzaju zdania elementarne (w tym skrócone formy zmiennych boolowskich) za pomocą spójników logiki zdań. Na przykład możemy wyrazić „Prawdopodobieństwo, że pacjentka ma ubytek, biorąc pod uwagę, że jest nastolatką bez bólu zęba, wynosi 0,1” w następujący sposób:
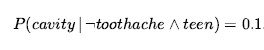
W notacji prawdopodobieństwa często używa się przecinka dla koniunkcji, więc możemy napisać
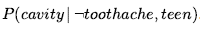
Czasami będziemy chcieli porozmawiać o prawdopodobieństwach wszystkich możliwych wartości zmiennej losowej. Moglibyśmy napisać:

ale jako skrót pozwolimy
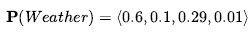
gdzie P wskazuje, że wynik jest wektorem liczb, a gdzie zakładamy predefiniowane uporządkowanie <słońce, deszcz, chmura, śnieg> na zakresie Pogoda . Mówimy, że zdanie P definiuje rozkład prawdopodobieństwa dla zmiennej losowej Wheater – czyli przypisanie prawdopodobieństwa dla każdej możliwej wartości zmiennej losowej. (W tym przypadku, przy skończonym, dyskretnym zakresie, rozkład nazywamy rozkładem kategorycznym). Notacja P jest również używana dla rozkładów warunkowych: P(X|Y) daje wartości P(X = xi | Y = yj) dla każdej możliwej pary i , j.
Dla zmiennych ciągłych nie jest możliwe wypisanie całego rozkładu jako wektora, ponieważ wartości jest nieskończenie wiele. Zamiast tego możemy zdefiniować prawdopodobieństwo, że zmienna losowa przyjmie pewną wartość jako sparametryzowaną funkcję , zwykle nazywaną funkcją gęstości prawdopodobieństwa. Na przykład zdanie
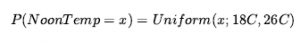
wyraża przekonanie, że temperatura w południe rozkłada się równomiernie między 18 a 26 stopni Celsjusza. Funkcje gęstości prawdopodobieństwa (czasami nazywane plikami pdf) różnią się znaczeniem od rozkładów dyskretnych. Powiedzenie, że gęstość prawdopodobieństwa jest jednolita w zakresie od 18°C do 26°C oznacza, że istnieje 100% szansa, że temperatura spadnie gdzieś w regionie o szerokości 18°C i 50% szansa, że spadnie ona w dowolnym podregionie o szerokości 4°C, oraz wkrótce. Piszemy gęstość prawdopodobieństwa dla ciągłej zmiennej losowej X o wartości x jako P(X = x) lub po prostu P(x) ; intuicyjna definicja P(x) to prawdopodobieństwo, że X mieści się w dowolnie małym obszarze zaczynającym się od x , podzielone przez szerokość obszaru:
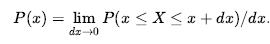
Dla NoonTemp mamy
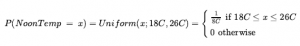
gdzie C oznacza stopnie Celsjusza (nie stałą). W P(NoonTemp = 20,18C) = 1/8C zauważ, że 1/8C nie jest prawdopodobieństwem, jest gęstością prawdopodobieństwa. Prawdopodobieństwo, że NoonTemp wynosi dokładnie 20.18C wynosi zero, ponieważ 20.18C jest regionem o szerokości 0. Niektórzy autorzy używają różnych symboli dla dyskretnych prawdopodobieństw i gęstości prawdopodobieństw; używamy P dla określonych wartości prawdopodobieństwa i P dla wektorów wartości w obu przypadkach, ponieważ zamieszanie rzadko się pojawia, a równania są zwykle identyczne. Zauważ, że prawdopodobieństwa są liczbami niemianowanymi, podczas gdy funkcje gęstości są mierzone jednostką, w tym przypadku odwrotnością stopni Celsjusza. Jeśli ten sam przedział temperatury miałby być wyrażony w stopniach Fahrenheita, miałby szerokość 14,4 stopnia, a gęstość wynosiłaby 1/14,4 F . Oprócz rozkładów na pojedynczych zmiennych potrzebujemy notacji dla rozkładów na wielu zmiennych. Używa się do tego przecinków. Na przykład P(Weather,Cavity) oznacza prawdopodobieństwa wszystkich kombinacji wartości Weather i Cavity . Jest to tabela prawdopodobieństw 4 x 2 zwana łącznym rozkładem prawdopodobieństwa pogody i jamy. Możemy również mieszać zmienne i określone wartości; P(sun,Cavity) byłby dwuelementowym wektorem podającym prawdopodobieństwa wnęki w słoneczny dzień i braku wnęki w słoneczny dzień.
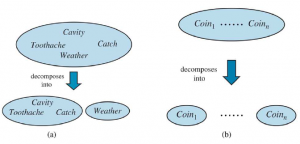
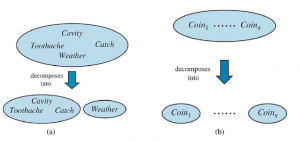
Notacja P sprawia, że niektóre wyrażenia są znacznie bardziej zwięzłe, niż mogłyby być w innym przypadku. Na przykład reguły iloczynów dla wszystkich możliwych wartości pogody i wnęki można zapisać jako pojedyncze równanie:
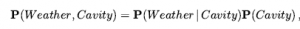
Jako przypadek zdegenerowany, P(słońce, wnęka) nie ma zmiennych, a zatem jest wektorem zerowym, który możemy traktować jako wartość skalarną. Teraz zdefiniowaliśmy składnię zdań i twierdzeń prawdopodobieństwa i podaliśmy część semantyki: Równanie definiuje prawdopodobieństwo zdania jako sumy prawdopodobieństw światów, w których ono zachodzi. Aby uzupełnić semantykę, musimy powiedzieć, czym są światy i jak określić, czy zdanie ma zastosowanie w świecie. Zapożyczamy tę część bezpośrednio z semantyki logiki zdań w następujący sposób. Świat możliwy jest definiowany jako przypisanie wartości do wszystkich rozważanych zmiennych losowych. Łatwo zauważyć, że ta definicja spełnia podstawowy wymóg, aby możliwe światy wzajemnie się wykluczały i były wyczerpujące (Ćwiczenie 12.EXEX). Na przykład, jeśli zmienne losowe są Cavity, Tothache i Weather , to jest 2 x 2 x 4 = 16 możliwych światów. Co więcej, prawdziwość dowolnego zdania można łatwo określić w takich światach za pomocą tego samego rekurencyjnego obliczania prawdziwości, którego używaliśmy do logiki zdań. Należy zauważyć, że niektóre zmienne losowe mogą być zbędne, ponieważ ich wartości można uzyskać we wszystkich przypadkach z wartości innych zmiennych. Na przykład zmienna Doubles w świecie dwóch kości jest prawdziwa dokładnie wtedy, gdy Die1 – Die2 . Włączenie Doubles jako jednej ze zmiennych losowych, oprócz Die1 i Die2, wydaje się zwiększać liczbę możliwych światów od 36 do 72, ale oczywiście dokładnie połowa z 72 będzie logicznie niemożliwa i będzie miała prawdopodobieństwo 0. Z powyższej definicji światów możliwych wynika, że model prawdopodobieństwa jest całkowicie określony przez łączny rozkład dla wszystkich zmiennych losowych – tzw. pełny wspólny rozkład prawdopodobieństwa. Na przykład, biorąc pod uwagę Cavity , Toothache i Weather , pełny rozkład stawów to P (Cavity , Toothache , Weather) . Ten wspólny rozkład można przedstawić jako tabelę 2 x 2 x 4 z 16 wpisami. Ponieważ prawdopodobieństwo każdego zdania jest sumą światów możliwych, pełny łączny rozkład w zasadzie wystarcza do obliczenia prawdopodobieństwa dowolnego zdania.