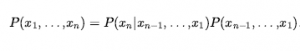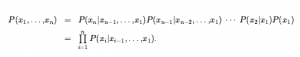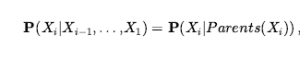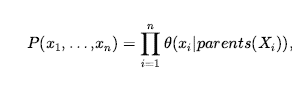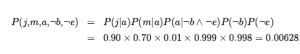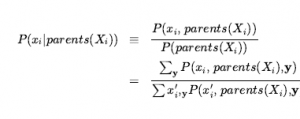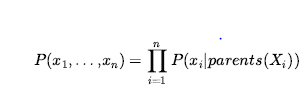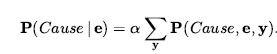Możemy połączyć pomysły zawarte w tym rozdziale, aby rozwiązać problemy z rozumowaniem probabilistycznym w świecie wumpusów. (Patrz rozdział 7, aby uzyskać pełny opis świata wumpusów.) W świecie wumpusów pojawia się niepewność, ponieważ czujniki agenta dostarczają tylko częściowe informacje o świecie. Na przykład Rysunek pokazuje sytuację, w której każdy z trzech nieodwiedzonych, ale osiągalnych kwadratów — [1,3], [2,2] i [3,1] — może zawierać dół. Czyste wnioskowanie logiczne nie może niczego wywnioskować na temat tego, który kwadrat jest najprawdopodobniej bezpieczny, więc agent logiczny może być zmuszony do losowego wyboru. Zobaczymy, że agent probabilistyczny może zrobić znacznie lepiej niż agent logiczny.
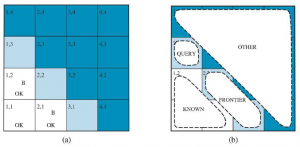
Naszym celem jest obliczenie prawdopodobieństwa, że każdy z trzech kwadratów zawiera dziurę. (W tym przykładzie ignorujemy wumpusa i złoto.) Odpowiednie właściwości świata wumpusa są takie, że (1) dziura wieje we wszystkich sąsiednich polach, oraz (2) każde pole inne niż [1,1] zawiera dół z prawdopodobieństwem 0,2. Pierwszym krokiem jest identyfikacja zestawu zmiennych losowych, których potrzebujemy:
* Podobnie jak w przypadku logiki zdań, chcemy mieć jedną zmienną Boole’a Pij dla każdego kwadratu, co jest prawdziwe, jeśli kwadrat [i,j] faktycznie zawiera dołek.
* Mamy również zmienne logiczne Bij, które są prawdziwe, jeśli [i,j] square is breezy; uwzględniamy te zmienne tylko dla obserwowanych kwadratów — w tym przypadku [1,1], [1,2] i [2,1].
Następnym krokiem jest określenie pełnego rozkładu złącza, P(P1,1,…,P4,4, B1.1 ,…,B4,4).
Stosując regułę produktu, mamy
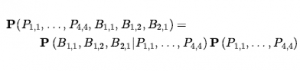
Ta dekompozycja ułatwia sprawdzenie, jakie powinny być wspólne wartości prawdopodobieństwa. Pierwszym terminem jest warunkowy rozkład prawdopodobieństwa konfiguracji bryzy, przy danej konfiguracji dołu; jego wartości wynoszą 1, jeśli wszystkie przewiewne kwadraty sąsiadują z dołami, a 0 w przeciwnym razie. Drugi termin to prawdopodobieństwo a priori konfiguracji dołu. Każdy kwadrat zawiera dołek z prawdopodobieństwem 0,2, niezależnie od pozostałych kwadratów; W związku z tym,
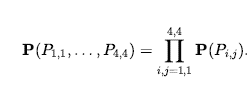
Dla konkretnej konfiguracji z dokładnie n dołkami prawdopodobieństwo wynosi 0,2n x 0,816-n. W sytuacji przedstawionej na rysunku dowodem jest zaobserwowana bryza (lub jej brak) na każdym odwiedzanym kwadracie, w połączeniu z faktem, że na każdym takim kwadracie nie ma jamy. Skrócimy te fakty jako b= ¬1,1 Λb1,2 Λ b2,1 i known = ¬p1,1 Λ ¬p1,2 Λ ¬p2,1 . Interesują nas odpowiedzi na takie pytania jak P(P1,3 | known , b) : jakie jest prawdopodobieństwo, że [1,3] zawiera wgłębienie, biorąc pod uwagę dotychczasowe obserwacje? Aby odpowiedzieć na to zapytanie, możemy zastosować standardowe podejście równania , a mianowicie sumowanie wpisów z pełnego łącznego rozkładu. Niech Unknown będzie zbiorem zmiennych Pi,j dla kwadratów innych niż kwadraty znane i kwadrat zapytania [1,3]. Następnie z równania mamy
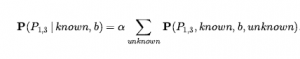
Podaliśmy już pełne prawdopodobieństwa łączne, więc gotowe – czyli chyba, że zależy nam na obliczeniach. Jest 12 nieznanych kwadratów; stąd suma zawiera 212 = 4096 terminów. Ogólnie rzecz biorąc, sumowanie rośnie wykładniczo wraz z liczbą kwadratów. Zapewne ktoś mógłby zapytać, czy inne kwadraty nie są nieistotne? Jak [4,4] może wpłynąć na to, czy [1,3] ma dół? Rzeczywiście, ta intuicja jest z grubsza słuszna, ale trzeba ją doprecyzować. Tak naprawdę mamy na myśli to, że gdybyśmy znali wartości wszystkich zmiennych pit sąsiadujących z kwadratami, na których nam zależy, to doły (lub ich brak) w innych, bardziej odległych kwadratach nie miałyby dalszego wpływu na nasze przekonanie. Niech Frontier będzie zmiennymi pit (innymi niż zmienna zapytania), które sąsiadują z odwiedzonymi kwadratami, w tym przypadku tylko [2,2] i [3,1]. Niech również Other będzie zmiennymi pit dla innych nieznanych kwadratów; w tym przypadku jest 10 innych kwadratów, jak pokazano na rysunku (b). Z tymi definicjami Unknown = Frontier U Other . Kluczowe spostrzeżenie podane powyżej można teraz sformułować w następujący sposób: obserwowane bryzy są warunkowo niezależne od innych zmiennych, biorąc pod uwagę zmienne znane, graniczne i zapytania. Aby skorzystać z tego wglądu, manipulujemy formułą zapytania do postaci, w której bryza jest uwarunkowana wszystkimi innymi zmiennymi, a następnie stosujemy warunkową niezależność:

gdzie ostatni krok wykorzystuje warunkową niezależność: b jest niezależne od innych podanych znanych , P1,3 i granicy. Teraz pierwszy wyraz w tym wyrażeniu nie zależy od innych zmiennych, więc możemy przesunąć sumowanie do wewnątrz:

Przez niezależność, jak w Równaniu (12.22) , termin po prawej stronie może być rozłożony na czynniki, a następnie terminy mogą być uporządkowane:

gdzie ostatni krok składa P(known) w stałą normalizującą i wykorzystuje fakt ,że Σother jest równy 1.
Teraz w sumowaniu są tylko cztery wyrazy dla zmiennych granicznych P2,2 i P3,1 . Użycie niezależności i warunkowej niezależności całkowicie wyeliminowało inne kwadraty z rozważań.
Zauważ, że prawdopodobieństwa w P(b|k, P1,3, frontier) wynoszą 1, gdy obserwacje wiatru są zgodne z innymi zmiennymi i 0 w przeciwnym razie. Zatem dla każdej wartości P1,3 sumujemy modele logiczne dla zmiennych granicznych, które są zgodne z
znane fakty. Modele i związane z nimi wcześniejsze prawdopodobieństwa — P(frontier) — pokazano na rysunku. Mamy
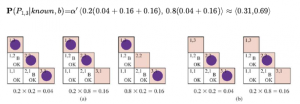
Oznacza to, że [1,3] (i [3,1] według symetrii) zawiera wgłębienie z prawdopodobieństwem około 31%. Podobne obliczenia, które czytelnik mógłby chcieć wykonać, pokazują, że [2,2] zawiera wgłębienie z około 86% prawdopodobieństwem. Agent wumpus powinien zdecydowanie unikać [2,2]! Zauważ, że nasz agent logiczny z rozdziału 7 nie wiedział, że [2,2] jest gorszy niż inne kwadraty. Logika może nam powiedzieć, że nie wiadomo, czy w [2, 2] jest dziura, ale potrzebujemy prawdopodobieństwa, aby powiedzieć nam, jakie to jest prawdopodobne. Ta sekcja pokazała, że nawet pozornie skomplikowane problemy można precyzyjnie sformułować w teorii prawdopodobieństwa i rozwiązać za pomocą prostych algorytmów. Aby uzyskać wydajne rozwiązania, można wykorzystać niezależność i zależności warunkowe w celu uproszczenia wymaganych podsumowań. Te relacje często odpowiadają naszemu naturalnemu zrozumieniu, jak należy rozłożyć problem. W następnym rozdziale opracujemy formalne reprezentacje takich relacji, a także algorytmy operujące na tych reprezentacjach w celu efektywnego wnioskowania probabilistycznego.