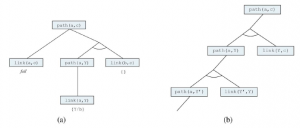
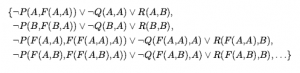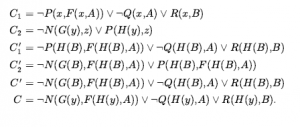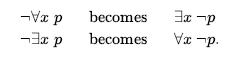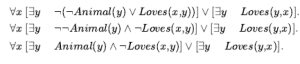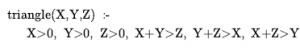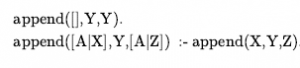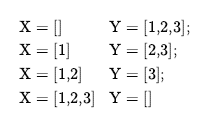Rozszerzając nieco język logiki pierwszego rzędu, aby uwzględnić matematyczny schemat indukcji w arytmetyce, Kurt Gödel był w stanie wykazać w swoim twierdzeniu o niezupełności, że istnieją prawdziwe zdania arytmetyczne, których nie można udowodnić. Dowód twierdzenia o niezupełności wykracza nieco poza zakres tej książki, zajmując co najmniej 30 stron, ale tutaj możemy dać wskazówkę. Zaczynamy od logicznej teorii liczb. W tej teorii istnieje pojedyncza stała 0 i pojedyncza funkcja S (funkcja następnika). W zamierzonym modelu S(0) oznacza 1, S(S(0)) oznacza 2 i tak dalej; język ma zatem nazwy dla wszystkich liczb naturalnych. Słownik zawiera również symbole funkcji + , x i Expt(potęgowanie) oraz zwykły zestaw spójników logicznych i kwantyfikatorów. Pierwszym krokiem jest zauważenie, że zbiór zdań, które możemy napisać w tym języku, można wyliczyć. (Wyobraźmy sobie zdefiniowanie porządku alfabetycznego na symbolach, a następnie ułożenie w porządku alfabetycznym każdego ze zbiorów zdań o długości 1, 2 itd.) Następnie możemy ponumerować każde zdanie α z unikalną liczbą naturalną #α (liczba Gödla). Ma to kluczowe znaczenie: teoria liczb zawiera nazwę dla każdego ze swoich własnych zdań. Podobnie możemy ponumerować każdy możliwy dowód P liczbą Gödla G(P) , ponieważ dowód jest po prostu skończonym ciągiem zdań. Załóżmy teraz, że mamy rekurencyjnie przeliczalny zbiór zdań A, które są prawdziwymi stwierdzeniami dotyczącymi liczb naturalnych. Przypominając, że A można nazwać za pomocą danego zbioru liczb całkowitych, możemy sobie wyobrazić napisanie w naszym języku zdania α(j,A) następującego rodzaju:
∀i i nie jest liczbą Gödla dowodu zdania, którego liczbą Gödla jest j , gdzie dowód wykorzystuje tylko przesłanki w A
Następnie niech sigma; niech będzie zdanie alfa;(σA) , czyli zdanie, które stwierdza własną niedowodliwość na podstawie A . (To, że to zdanie zawsze istnieje, jest prawdziwe, ale nie do końca oczywiste).
Teraz przedstawiamy następujący pomysłowy argument: Załóżmy, że sigma; można udowodnić z A; następnie sigma; jest fałszywe (ponieważ sigma; mówi, że nie można tego udowodnić). Ale wtedy mamy fałszywe zdanie, które można udowodnić z A , więc A nie może składać się tylko ze zdań prawdziwych – a naruszenie naszego założenia. Dlatego sigma; nie da się udowodnić z A . Ale to jest właśnie sigma; sama twierdzi; stąd sigma; to prawdziwe zdanie.
Wykazaliśmy więc (z wyjątkiem 29 1/2 strony), że dla każdego zestawu zdań prawdziwych teorii liczb, a w szczególności zestawu podstawowych aksjomatów, istnieją inne zdania prawdziwe, których nie można udowodnić na podstawie tych aksjomatów. Ustala to między innymi, że nigdy nie możemy udowodnić wszystkich twierdzeń matematyki w ramach danego systemu aksjomatów. Oczywiście było to ważne odkrycie dla matematyki. Jego znaczenie dla sztucznej inteligencji było szeroko dyskutowane, poczynając od spekulacji samego Gödla