W domenach „zabawkowych” wybór reprezentacji nie jest tak ważny; wiele opcji będzie działać. Złożone domeny, takie jak zakupy w Internecie czy jazda samochodem w ruchu, wymagają bardziej ogólnych i elastycznych reprezentacji. Ten rozdział pokazuje, jak tworzyć te reprezentacje, koncentrując się na ogólnych pojęciach — takich jak zdarzenia, czas, obiekty fizyczne i przekonania — które występują w wielu różnych dziedzinach. Reprezentowanie tych abstrakcyjnych pojęć jest czasami nazywane inżynierią ontologiczną. Nie możemy mieć nadziei, że przedstawimy wszystko na świecie, nawet 1000-stronicowy podręcznik, ale zostawimy miejsca, w których zmieści się nowa wiedza dla dowolnej domeny. Na przykład określimy, co to znaczy być fizycznym obiektem, a szczegóły różnych typów obiektów — robotów, telewizorów, książek lub czegokolwiek — można później wypełnić. Jest to analogiczne do sposobu, w jaki projektanci struktur programistycznych zorientowanych obiektowo (takich jak środowisko graficzne Java Swing) definiują ogólne koncepcje, takie jak Window, oczekując, że użytkownicy będą używać ich do definiowania bardziej szczegółowych pojęć, takich jak SpreadsheetWindow. Ogólna struktura pojęć nazywana jest wyższą ontologią ze względu na konwencję rysowania grafów z pojęciami ogólnymi na górze i pojęciami bardziej szczegółowymi pod nimi, jak na rysunku
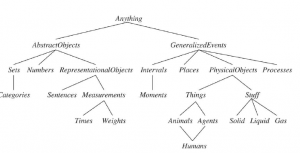
Zanim dalej zajmiemy się ontologią, powinniśmy podać jedno ważne zastrzeżenie. Zdecydowaliśmy się użyć logiki pierwszego rzędu do omawiania zawartości i organizacji wiedzy, chociaż niektóre aspekty realnego świata są trudne do uchwycenia w FOL. Główna trudność polega na tym, że większość uogólnień ma wyjątki lub obowiązuje tylko do pewnego stopnia. Na przykład, chociaż „pomidory są czerwone” jest użyteczną zasadą, niektóre pomidory są zielone, żółte lub pomarańczowe. Podobne wyjątki można znaleźć w prawie wszystkich regułach w tym rozdziale. Umiejętność radzenia sobie z wyjątkami i niepewnością jest niezwykle ważna, ale jest ortogonalna do zadania polegającego na zrozumieniu ogólnej ontologii. Jaki jest pożytek z wyższej ontologii? Rozważ ontologię obwodów. Zawiera wiele upraszczających założeń: całkowicie pomija się czas; sygnały są stałe i nie rozchodzą się; struktura obwodu pozostaje stała. Bardziej ogólna ontologia uwzględniałaby sygnały w określonych momentach i obejmowałaby długości przewodów i opóźnienia propagacji. To pozwoliłoby nam symulować właściwości czasowe obwodu i rzeczywiście takie symulacje są często przeprowadzane przez projektantów obwodów. Moglibyśmy również wprowadzić ciekawsze klasy bramek, na przykład opisując technologię (TTL, CMOS itd.) oraz specyfikację wejścia-wyjścia. Gdybyśmy chcieli omówić niezawodność lub diagnozę, uwzględnilibyśmy możliwość spontanicznej zmiany struktury obwodu lub właściwości bramek. Aby uwzględnić rozproszenie pojemności, musielibyśmy przedstawić, gdzie znajdują się przewody na płytce. Jeśli spojrzymy na świat wumpusów, mamy do czynienia z podobnymi rozważaniami. Chociaż reprezentujemy czas, ma on prostą strukturę: nic się nie dzieje poza momentami działania agenta, a wszystkie zmiany są natychmiastowe. Bardziej ogólna ontologia, lepiej dopasowana do świata rzeczywistego, pozwoliłaby na jednoczesne zmiany rozciągnięte w czasie. Użyliśmy również predykatu zagłębienia, aby powiedzieć, które kwadraty mają zagłębienia. Mogliśmy pozwolić na różne rodzaje dołów, mając kilka osobników należących do klasy dołów, z których każdy ma inne właściwości. Podobnie możemy chcieć pozwolić na inne zwierzęta oprócz wumpusów. Być może nie da się określić dokładnego gatunku na podstawie dostępnych spostrzeżeń, więc musielibyśmy stworzyć biologiczną taksonomię, aby pomóc agentowi przewidzieć zachowanie mieszkańców jaskini na podstawie skąpych wskazówek. W przypadku każdej ontologii specjalnego przeznaczenia możliwe jest dokonanie takich zmian, aby przejść w kierunku większej ogólności. Powstaje wtedy oczywiste pytanie: czy wszystkie te ontologie zbiegają się w ontologii ogólnego przeznaczenia? Po wiekach filozoficznych i obliczeniowych dociekań odpowiedź brzmi „może”. W tej części przedstawiamy jedną ontologię ogólnego przeznaczenia, która łączy idee z tamtych wieków. Dwie główne cechy ontologii ogólnego przeznaczenia odróżniają je od zbiorów ontologii specjalnego przeznaczenia:
* Ontologia ogólnego przeznaczenia powinna mieć zastosowanie w mniej więcej dowolnej domenie specjalnego przeznaczenia (z dodatkiem aksjomatów dziedzinowych). Oznacza to, że żaden problem reprezentacyjny nie może być finezyjny ani zamiatany pod dywan.
* W każdej wystarczająco wymagającej dziedzinie różne obszary wiedzy muszą być ujednolicone, ponieważ rozumowanie i rozwiązywanie problemów może obejmować kilka obszarów jednocześnie. Na przykład system naprawy obwodów robota musi analizować obwody pod kątem połączeń elektrycznych i układu fizycznego oraz czasu, zarówno w celu analizy synchronizacji obwodów, jak i szacowania pracy, którą można połączyć z tymi, które opisują układ przestrzenny i muszą działać równie dobrze dla nanosekund i minut oraz dla angstremów i metrów.
Powinniśmy z góry powiedzieć, że przedsięwzięcie ogólnej inżynierii ontologicznej odniosło jak dotąd jedynie ograniczony sukces. Żadna z najlepszych aplikacji AI nie korzysta z ogólnej ontologii – wszystkie wykorzystują inżynierię wiedzy specjalnego przeznaczenia i maszynę uczenia się. Względy społeczne/polityczne mogą utrudnić konkurującym stronom uzgodnienie ontologii. Jak mówi Tom Gruber : „Każda ontologia jest traktatem – umową społeczną – pomiędzy ludźmi, dla których istnieje jakiś wspólny motyw dzielenia się”. Kiedy rywalizujące obawy przeważają nad motywacją do dzielenia się, nie może być wspólnej ontologii. Im mniejsza liczba interesariuszy, tym łatwiej jest stworzyć ontologię, a co za tym idzie trudniej stworzyć ontologię ogólnego przeznaczenia niż taką o ograniczonym przeznaczeniu, taką jak Open Biomedical Ontology (Smith i in., 2007). Te ontologie, które istnieją, zostały stworzone czterema ścieżkami:
- Przez zespół przeszkolonych ontologów lub logików, którzy projektują ontologię i piszą aksjomaty. System CYC był w większości zbudowany w ten sposób.
- Importując kategorie, atrybuty i wartości z istniejącej bazy danych lub baz danych. DBPEDIA została zbudowana poprzez import ustrukturyzowanych faktów z Wikipedii.
- Analizując dokumenty tekstowe i wydobywając z nich informacje. TEXTRUNNER został zbudowany poprzez czytanie dużego zbioru stron internetowych.
- Zachęcając niewykwalifikowanych amatorów do wchodzenia w wiedzę zdroworozsądkową. System OPENMIND został zbudowany przez wolontariuszy, którzy przedstawiali fakty w języku angielskim.
Na przykład w Grafie wiedzy Google wykorzystano częściowo ustrukturyzowaną treść z Wikipedii, łącząc ją z innymi treściami zebranymi z całej sieci pod nadzorem człowieka. Zawiera ponad 70 miliardów faktów i dostarcza odpowiedzi na około jedną trzecią wyszukiwań w Google