Programowanie logiczne to technologia, która zbliża się do urzeczywistnienia deklaratywnego ideału : systemy powinny być konstruowane poprzez wyrażanie wiedzy w języku formalnym, a problemy powinny być rozwiązywane poprzez uruchamianie procesów wnioskowania na tej wiedzy. Ideał podsumowuje równanie Roberta Kowalskiego:
![]()
Prolog jest najczęściej używanym językiem programowania logicznego. Jest używany głównie jako język szybkiego prototypowania i do zadań związanych z manipulacją symbolami, takich jak pisanie kompilatorów (Van Roy, 1990) i analizowanie języka naturalnego (Pereira i Warren, 1980). W Prologu napisano wiele systemów eksperckich dla dziedzin prawnych, medycznych, finansowych i innych. Programy prologowe to zestawy określonych klauzul zapisanych w notacji nieco innej niż standardowa logika pierwszego rzędu. Prolog używa wielkich liter dla zmiennych i małych dla stałych — przeciwieństwo naszej konwencji logiki. Przecinki oddzielają spójniki w zdaniu, a zdanie jest napisane „od tyłu” od tego, do czego jesteśmy przyzwyczajeni; zamiast A Λ B => C w Prologu mamy CF:- A ,B. Oto typowy przykład:
![]()
W Prologu notacja [E|L] oznacza listę, której pierwszym elementem jest E, a reszta to L. Oto program Prologa dla append(X,Y,Z), który się powiedzie, jeśli lista Z jest wynikiem dołączania list X i Y:
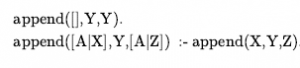
W języku angielskim klauzule te możemy odczytać jako (1) dołączając pustą listę, a lista Y tworzy tę samą listę Y, a (2) [A|Z] jest wynikiem dołączania [A|X] i Y, pod warunkiem, że Z jest wynikiem dołączania X i Y. W większości języków wysokiego poziomu możemy napisać podobną funkcję rekurencyjną, która opisuje sposób dołączania dwóch list. Definicja Prologu jest jednak potężniejsza, ponieważ opisuje relację, która zachodzi między trzema argumentami, a nie funkcję obliczoną z dwóch argumentów. Na przykład, możemy zapytać zapytanie append(X,Y,[1,2,3]): jakie dwie listy można dodać, aby dać [1,2,3]? Prolog zwraca nam rozwiązania
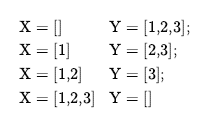
Wykonywanie programów Prologu odbywa się poprzez łańcuchowanie wsteczne w głąb, gdzie klauzule są testowane w kolejności, w jakiej są napisane w bazie wiedzy. Projekt Prologu to kompromis między deklaratywnością a wydajnością wykonania. Niektóre aspekty Prologu wykraczają poza standardowe logiczne wnioskowanie:
* Prolog używa semantyki bazy danych zamiast semantyki pierwszego rzędu, co jest widoczne w sposobie traktowania równości i negacji.
* Istnieje zestaw wbudowanych funkcji arytmetycznych. Literały używające tych symboli funkcji są „udowadniane” przez wykonanie kodu, a nie dalsze wnioskowanie. Na przykład, cel „X to 4 +3 ” udaje się, gdy X jest powiązane z 7. Z drugiej strony cel „5 to X + Y” nie powiedzie się, ponieważ wbudowane funkcje nie rozwiązują arbitralnego równania.
* Istnieją wbudowane predykaty, które po wykonaniu mają skutki uboczne. Należą do nich predykaty wejścia-wyjścia oraz predykaty asercji/wycofywania służące do modyfikowania bazy wiedzy. Takie predykaty nie mają odpowiednika w logice i mogą dawać mylące wyniki – na przykład, jeśli fakty są potwierdzone w gałęzi drzewa dowodowego, która ostatecznie zawodzi.
* Wystąpienie sprawdzenia jest pomijane w algorytmie unifikacji Prologu. Oznacza to, że można dokonać pewnych nierozsądnych wniosków; w praktyce prawie nigdy nie stanowią one problemu.
* Prolog używa wyszukiwania z łańcuchem wstecznym w głąb, bez sprawdzania nieskończonej rekurencji. Stwarza to użyteczny język programowania, który jest bardzo szybki, gdy jest używany prawidłowo, ale oznacza to, że niektóre programy, które wyglądają jak poprawna logika, nie zostaną zakończone.