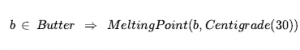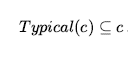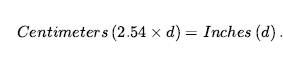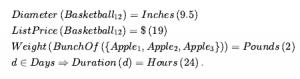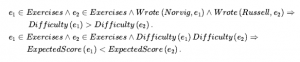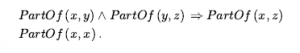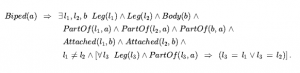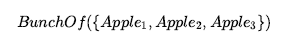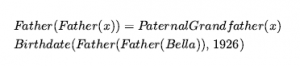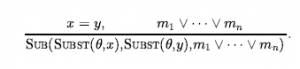Omówiliśmy działania: rzeczy, które się dzieją, takie jak Shoott; i płynnie zmieniające się aspekty świata, takie jak HaveArrowt. Oba były reprezentowane jako zdania, a aksjomatami stanu następcy użyliśmy, aby powiedzieć, że biegłość będzie prawdziwa w czasie, jeśli działanie w czasie spowodowało, że było prawdziwe, lub jeśli było już prawdziwe w czasie t + 1, a działanie nie spowodować, że będzie fałszywe. To było dla świata, w którym akcje są dyskretne, natychmiastowe, zdarzają się pojedynczo i nie mają różnic w sposobie ich wykonywania (to znaczy, jest tylko jeden rodzaj akcji Strzelaj, nie ma różnicy między strzelaniem szybko, powoli nerwowo itd.). Ale gdy przechodzimy od uproszczonych dziedzin do rzeczywistego świata, istnieje znacznie bogatszy zakres działania lub zdarzenia, którymi trzeba się zająć. Rozważ działanie ciągłe, takie jak napełnianie wanny. Aksjomat stanu następcy może mówić, że wanna jest pusta przed akcją i pełna po zakończeniu akcji, ale nie może mówić o tym, co dzieje się podczas akcji. Nie jest też w stanie opisać dwóch czynności dziejących się w tym samym czasie – takich jak mycie zębów podczas oczekiwania na wypełnienie wanny. Aby poradzić sobie z takimi przypadkami, wprowadzamy podejście znane jako rachunek zdarzeń. Obiektami rachunku zdarzeń są zdarzenia, biegły i punkty czasowe. At(Shankar,Berkeley) jest płynny: przedmiot, który odnosi się do faktu przebywania Shankara w Berkeley. Wydarzenie E1 Shankara lecącego z San Francisco do Waszyngtonu jest opisane jako
![]()
gdzie Flyings to kategoria wszystkich zawodów lotniczych. Reifikując zdarzenia umożliwiamy dodanie dowolnej ilości dowolnych informacji o nich. Na przykład możemy powiedzieć, że lot Shankara był wyboisty z Bumpy(E1). W ontologii, w której zdarzenia są n-arnymi predykatami, nie byłoby możliwości dodania takich dodatkowych informacji; przejście do predykatu n+1 nie jest rozwiązaniem skalowalnym. Aby stwierdzić, że biegły jest rzeczywiście prawdziwy, zaczynając od pewnego momentu t1 i kontynuując do czasu t2 , używamy predykatu T , tak jak w T(At(Shankar, Berkeley) t1,t2) . Podobnie używamy Happens(E1,t1,t2), aby powiedzieć, że zdarzenie E1 rzeczywiście miało miejsce, zaczynając w czasie t1 i kończąc w czasie t2 . Kompletny zestaw predykatów dla jednej wersji rachunku zdarzeń to:
T (f, t1, t2) : Płynne f jest prawdziwe dla wszystkich czasów między t1 a t2
Dzieje się (e, t1, t2) : Zdarzenie e rozpoczyna się o godzinie t1 i kończy o godzinie t2
Inicjuje (e, f, t): Zdarzenie e powoduje, że płynne f staje się prawdziwe w czasie t
Kończy (e, f, t): Zdarzenie e powoduje, że płynne f przestaje być prawdziwe w czasie t
Zainicjowane (f, t1, t2) : Płynne f staje się prawdziwe w pewnym momencie między t1 i t2
Zakończony (f, t1, t2) : Płynne f przestaje być prawdziwe w pewnym momencie między t1 i t2
t1 < t2 : Punkt czasowy t1 występuje przed czasem t2
Skutki zdarzenia lotniczego możemy opisać:
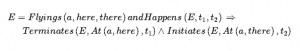
Zakładamy wyróżnione zdarzenie Start, które opisuje stan początkowy, mówiąc, które biegły są prawdziwe (przy użyciu Initiates) lub fałszywe (przy użyciu Terminated) w momencie rozpoczęcia. Możemy wtedy opisać, które biegły są prawd ziwe w jakich momentach za pomocą pary aksjomatów dla T i że ¬T postępuj zgodnie z tym samym ogólnym formatem, co aksjomaty stanu następcy: Załóżmy, że zdarzenie ma miejsce między czasem t1 i t3 , a w t2 gdzieś w tym przedziale czasu zdarzenie zmienia wartość płynnego f , albo inicjując je (uczyniając je prawdziwym) albo kończąc ( czyniąc to fałszywym). Następnie w czasie t4 w przyszłości, jeśli żadne inne zdarzenie nie zmieniło biegłości (odpowiednio albo ją przerwało, albo zainicjowało), to biegły zachowa swoją wartość. Formalnie aksjomaty to:
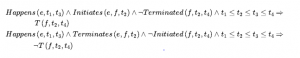
gdzie Zakończone i Zainicjowane są zdefiniowane przez:
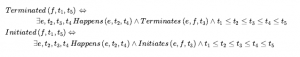
Możemy rozszerzyć rachunek zdarzeń, aby reprezentować zdarzenia jednoczesne (takie jak dwie osoby niezbędne do jazdy na huśtawce), zdarzenia egzogeniczne (takie jak wiatr poruszający obiektem), zdarzenia ciągłe (takie jak przypływ pływu), zdarzenia niedeterministyczne (takie jak jak rzucanie monetą i wyrzucanie resztek lub reszek) i inne komplikacje.