Przypomnijmy sobie trudność, jaką mieliśmy z wyrażeniem ogólnych zasad w logice zdań. Reguły takie jak „Kwadraty sąsiadujące z wumpusem śmierdzą” i „Wszyscy królowie są osobami” to chleb powszedni logiki pierwszego rzędu. Pierwszym z nich zajmiemy się później. Druga zasada, „Wszyscy królowie są osobami”, jest napisana w logice pierwszego rzędu jako
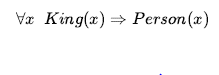
Uniwersalny kwantyfikator jest zwykle wymawiany „Dla wszystkich … ”. (Pamiętaj, że odwrócone A oznacza „wszystko”). Zatem zdanie mówi: „Dla wszystkich, jeśli jest królem, to x jest osobą”. Symbol x nazywa się zmienną. Zgodnie z konwencją, zmienne są małymi literami. Zmienna jest terminem samym w sobie i jako taka może również służyć jako argument funkcji – na przykład LeftLeg(x). Termin bez zmiennych nazywany jest terminem podstawowym.
Intuicyjnie, zdanie ∀x P , gdzie P jest dowolnym zdaniem logicznym, mówi, że jest prawdziwe dla każdego obiektu x. Dokładniej, ∀x P jest prawdziwe w danym modelu, jeśli P jest prawdziwe we wszystkich możliwych interpretacjach rozszerzonych zbudowanych z interpretacji podanej w modelu, gdzie każda interpretacja rozszerzona określa element domeny, do której się odnosi x.
Brzmi to skomplikowanie, ale tak naprawdę jest to tylko ostrożny sposób na określenie intuicyjnego znaczenia uniwersalnej kwantyfikacji. Rozważ model pokazany na rysunku i zamierzoną interpretację, która się z nim wiąże. Interpretację możemy rozszerzyć na pięć sposobów:

Zdanie uniwersalnie kwantyfikowane ∀x King(x) => Person(x) jest prawdziwe w oryginalnym modelu, jeśli zdanie King(x) => Person(x) jest prawdziwe w każdej z pięciu rozszerzonych interpretacji. Oznacza to, że zdanie powszechnie kwantyfikowalne jest równoważne stwierdzeniu następujących pięciu zdań:

Przyjrzyjmy się uważnie temu zestawowi twierdzeń. Ponieważ w naszym modelu król Jan jest jedynym królem, drugie zdanie stwierdza, że jest on osobą, jak byśmy mieli nadzieję. Ale co z pozostałymi czterema zdaniami, które wydają się zawierać twierdzenia dotyczące nóg i koron? Czy to część znaczenia słowa „Wszyscy królowie są osobami”? W rzeczywistości pozostałe cztery twierdzenia są prawdziwe w modelu, ale nie podawaj żadnych roszczeń co do cech osobowości nóg, koron, czy też Richarda. To dlatego, że żaden z tych obiektów nie jest królem. Patrząc na tabelę prawdy, widzimy, że implikacja jest prawdziwa zawsze, gdy jej założenie jest fałszywe – niezależnie od prawdziwości wniosku. Tak więc, stwierdzając zdanie powszechnie skwantyfikowane, co jest równoważne stwierdzeniu całej listy indywidualnych implikacji, w końcu stwierdzamy konkluzję reguły tylko dla tych przedmiotów, dla których przesłanka jest prawdziwa, i nie mówimy w ogóle o tych przedmiotach, dla których założenie jest fałszywe. Tak więc definicja tabeli prawdy okazuje się idealna do pisania ogólnych reguł za pomocą uniwersalnych kwantyfikatorów. Częstym błędem, popełnianym często nawet przez pilnych czytelników, którzy przeczytali ten paragraf kilka razy, jest użycie spójnika zamiast implikacji. Zdanie
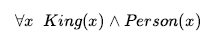
byłoby równoznaczne z twierdzeniem

i tak dalej. Oczywiście to nie oddaje tego, czego chcemy.




