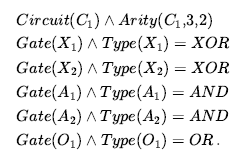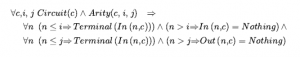Jednym ze sposobów przeprowadzenia wnioskowania pierwszego rzędu jest przekształcenie bazy wiedzy pierwszego rzędu w logikę zdań i użycie wnioskowania zdań, co już wiemy. Pierwszym krokiem jest wyeliminowanie uniwersalnych kwantyfikatorów. Załóżmy na przykład, że nasza baza wiedzy zawiera standardowy aksjomat ludowy, że wszyscy chciwi królowie są źli:
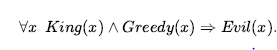
Z tego możemy wywnioskować dowolne z następujących zdań:
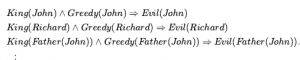
Ogólnie rzecz biorąc, reguła uniwersalnej instancji (w skrócie UI) mówi, że możemy wywnioskować dowolną encję uzyskaną przez zastąpienie termu podstawowego (terminu bez zmiennych) zmienną uniwersalnie kwantyfikowaną. Aby formalnie napisać regułę wnioskowania, posługujemy się pojęciem podstawień. SUBST(θ,α) oznacza wynik zastosowania podstawienia θ do zdania α . Wtedy reguła jest zapisana :
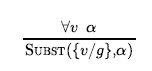
dla dowolnej zmiennej v i podstawowego warunku g. Na przykład trzy zdania podane wcześniej są otrzymywane z podstawieniami {x/John}, {x/Richard} , i {x/Father(John)}. Podobnie, zasada egzystencjalnej egzystencji zastępuje egzystencjalnie skwantyfikowaną zmienną pojedynczym nowym symbolem stałej. Formalne stwierdzenie jest następujące: dla każdego zdania α , zmiennej v i symbolu stałej k, który nie występuje nigdzie indziej w bazie wiedzy,
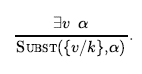
Na przykład ze zdania
![]()
możemy wywnioskować zdanie
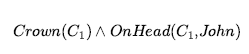
o ile C1nie pojawia się w innym miejscu w bazie wiedzy. Zasadniczo zdanie egzystencjalne mówi, że istnieje jakiś obiekt spełniający warunek, a zastosowanie reguły egzystencjalnej konkretyzacji nadaje temu obiektowi nazwę. Oczywiście ta nazwa nie może już należeć do innego przedmiotu. Matematyka dostarcza dobrego przykładu: załóżmy, że odkrywamy, że istnieje liczba nieco większa niż 2,71828, która spełnia równanie d(xy) / dy = xy dla x . Możemy nadać temu numerowi nazwę e, ale błędem byłoby nadanie mu nazwy istniejącego obiektu, np. π . W logice nowa nazwa nazywa się stałą Skolema. Podczas gdy Uniwersalna Instancja może być zastosowana wiele razy do tego samego aksjomatu, aby wywołać wiele różnych konsekwencji, Egzystencjalna Instancja musi być zastosowana tylko raz, a następnie egzystencjalnie określone ilościowo zdanie może zostać odrzucone. Na przykład nie potrzebujemy już ![]() po dodaniu zdania Kill(Murder, Victim)
po dodaniu zdania Kill(Murder, Victim)