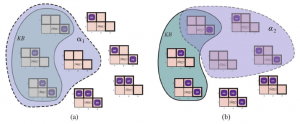
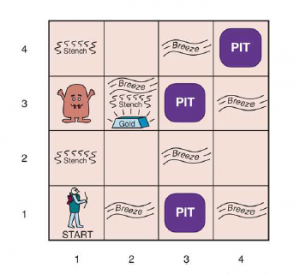
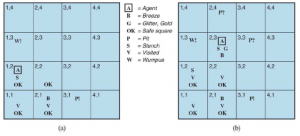
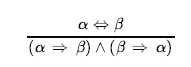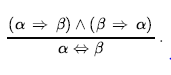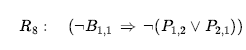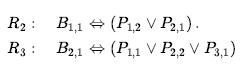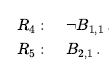Argumentowaliśmy, że opisane do tej pory reguły wnioskowania są prawidłowe, ale nie omawialiśmy kwestii kompletności algorytmów wnioskowania, które ich używają. Algorytmy wyszukiwania, takie jak iteracyjne wyszukiwanie pogłębiające, są kompletne w tym sensie, że znajdą dowolny osiągalny cel, ale jeśli dostępne reguły wnioskowania są nieodpowiednie, to cel nie jest osiągalny – nie ma dowodu, który używa tylko tych reguł wnioskowania. Na przykład, jeśli usuniemy dwuwarunkową zasadę eliminacji, dowód w poprzedniej sekcji nie przejdzie. Obecna sekcja wprowadza pojedynczą regułę wnioskowania, rozdzielczość, która daje kompletny algorytm wnioskowania w połączeniu z dowolnym kompletnym algorytmem wyszukiwania. Zaczynamy od prostej wersji reguły rozwiązywania w świecie wumpusa. Rozważmy kroki prowadzące do Rysunku 7.4(a): agent wraca z [2,1] do [1,1], a następnie przechodzi do [1,2], gdzie odczuwa smród, ale nie ma wiatru. Do bazy wiedzy dodajemy następujące fakty:
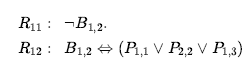
W tym samym procesie, który doprowadził R10 do tego wcześniej, możemy teraz wyprowadzić brak wgłębień w [2,2] i [1,3] (pamiętaj, że [1,1] jest już znany jako bez wgłębień):
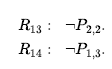
Możemy również zastosować dwuwarunkową eliminację do R3 , a następnie Modus Ponens z R5 , aby uzyskać fakt, że w [1,1], [2,2] lub [3,1] jest dziura:
![]()
Teraz pojawia się pierwsze zastosowanie reguły rozstrzygania: literał in rozwiązuje z literałem in, aby dać rezolwentę
![]()
Po angielsku; jeśli w jednym z [1,1], [2,2] i [3,1] jest dół, a nie w [2,2], to jest w [1,1] lub [3,1]. Podobnie dosłowne ¬P1,1 w R1 rozwiązuje z dosłownym P1,1 w R1,6 dając
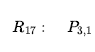
Po angielsku: jeśli jest dół w [1,1] lub [3,1], a nie w [1,1], to jest w [3,1]. Te dwa ostatnie kroki wnioskowania są przykładami reguły wnioskowania o rozdzielczości jednostki
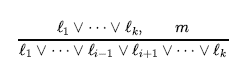
gdzie każdy l jest literałem, a li i m są literałami komplementarnymi (tj. jeden jest negacją drugiego). Tak więc reguła rozstrzygania jednostek przyjmuje klauzulę – alternatywę literałów – i literał i tworzy nową klauzulę. Zauważ, że pojedynczy literał może być postrzegany jako alternatywa jednego literału, znanego również jako klauzula jednostkowa. Regułę rozdzielczości jednostek można uogólnić do reguły pełnej rozdzielczości
![]()
gdzie li i mj są literałami komplementarnymi. To mówi, że rozdzielczość przyjmuje dwie klauzule i tworzy nową klauzulę zawierającą wszystkie literały dwóch oryginalnych klauzul z wyjątkiem dwóch literałów uzupełniających. Na przykład mamy
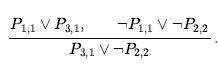
Jednocześnie można rozwiązać tylko jedną parę literałów uzupełniających. Na przykład możemy rozwiązać P i wydedukować ¬P
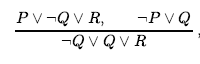
ale nie można rozwiązać jednocześnie na P i Q, aby wywnioskować R. Jest jeszcze jeden techniczny aspekt reguły rozstrzygania: wynikowa klauzula powinna zawierać tylko jedną kopię każdego literału. Usunięcie wielu kopii literałów nazywa się faktoringiem. Na przykład, jeśli rozwiązujemy (A V B) za pomocą (A V ¬B), otrzymujemy (A V A), co sprowadza A do samego faktoringu.
Słuszność reguły rozstrzygnięcia można łatwo dostrzec, biorąc pod uwagę dosłowne li, które jest komplementarne do dosłownego mj w drugiej klauzuli. Jeśli li jest prawdziwe, to mj jest fałszywe, a zatem ![]() musi być prawdziwe, ponieważ
musi być prawdziwe, ponieważ ![]() jest dane. Jeśli li jest fałszywe, to
jest dane. Jeśli li jest fałszywe, to ![]() musi być prawdziwe, ponieważ
musi być prawdziwe, ponieważ ![]() .Teraz li jest prawda lub fałsz, więc jeden lub drugi z tych wniosków jest słuszny – dokładnie tak, jak stanowi reguła rozstrzygania. Bardziej zaskakujące w regule rozstrzygającej jest to, że stanowi ona podstawę rodziny kompletnych procedur wnioskowania. Dowód twierdzenia oparty na rozdzielczości może, dla dowolnych zdań i logiki zdań, zdecydować, czy
.Teraz li jest prawda lub fałsz, więc jeden lub drugi z tych wniosków jest słuszny – dokładnie tak, jak stanowi reguła rozstrzygania. Bardziej zaskakujące w regule rozstrzygającej jest to, że stanowi ona podstawę rodziny kompletnych procedur wnioskowania. Dowód twierdzenia oparty na rozdzielczości może, dla dowolnych zdań i logiki zdań, zdecydować, czy ![]()
Spójna forma normalna
Reguła rozwiązywania dotyczy tylko klauzul (czyli alternatywy literałów), więc wydaje się, że dotyczy tylko baz wiedzy i zapytań składających się z klauzul. Jak zatem może prowadzić do kompletnej procedury wnioskowania dla całej logiki zdań? Odpowiedź brzmi, że każde zdanie logiki zdań jest logicznie równoważne koniunkcji zdań. Mówi się, że zdanie wyrażone jako koniunkcja zdań jest w spójnej formie normalnej lub CNF. Opiszemy teraz procedurę konwersji na CNF. Procedurę ilustrujemy zamieniając zdanie B1,1 ⇔ (P,1,2 V _2,1)na CNF. Kroki są następujące:
- Wyeliminuj ⇔ , zastępując α ⇔ β z (α ⇔ β) Λ ( β ⇔ α)
![]()
- Wyeliminuj ⇒ , zastępując (α ⇒ β) z ¬α V β:
![]()
- CNF wymaga ¬, aby pojawiać się tylko w literach, więc „poruszamy się ¬ do wewnątrz” poprzez wielokrotne zastosowanie następujących równoważności :
¬(¬α) ≡ α (eliminacja podwójnej negacji)
¬(α Λ β) ≡ (¬α V ¬β) (De Morgan)
¬(α V β) ≡ (¬α Λ ¬β) (De Morgan)
W tym przykładzie wymagamy tylko jednego zastosowania ostatniej reguły:
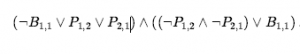
- Teraz mamy zdanie zawierające zagnieżdżone Λ i V operatory zastosowane do literałów. Stosujemy prawo dystrybucji, rozprowadzając V i Λ tam, gdzie to możliwe.
![]()
Pierwotne zdanie jest teraz w CNF jako połączenie trzech klauzul. Jest znacznie trudniejszy do odczytania, ale może być wykorzystany jako dane wejściowe do procedury rozwiązywania problemów.